Tag: visual studio
Three Awesome Months
Posted by bsstahl on 2019-02-26 and Filed Under: event
The next few months are going to be absolutely amazing. We've got some great events coming up in March and April right here in the Valley of the Sun. In addition, I currently have 4 conferences scheduled in 4 different countries on 2 continents.
AZGiveCamp IX - Presented by Quicken Loans - March 8th-10th
The most important occasion coming up is the 9th AZGiveCamp Hackathon of Help. This year, we're very fortunate to have Quicken Loans presenting our event and hosting it at their new facility in downtown Phoenix. At AZGiveCamp, Arizona's finest technologists will put their skills to work creating software for some great local charity organizations. We help them help our community by using our skills to create tools that help them further their mission.
Visual Studio 2019 Arizona Launch - April 16th
Another fun event for developers in the valley is the Visual Studio 2019 Arizona Launch event being hosted at Galvanize. We'll have some great speakers talking about how Visual Studio 2019 is a more productive, modern, and innovative environment for building software.
Around the World
In March, I'll be visiting opposite ends of the east coast of North America.
First, on March 2nd, I'll be attending the always amazing South Florida Code Camp in Fort Lauderdale. This event is right up there with the biggest community conferences in the country and is always worth attending. This will be the 7th year I've presented at SoFlaCC. If you're in the area I hope you'll attend.
Later in March, I cross the border into Canada to attend ConFoo Montreal. This will be my first trip ever to Montreal so I hope the March weather is kind to this 35 year Phoenix resident. The event runs from March 13th - 15th and there will be 2 Canadiens games during the time I am there so I should be able to get to at least one of them.
In May I get to do a short tour of Europe, spending 2 weeks at conferences in Budapest, Hungary (Craft Conference), and Marbella, Spain (J on the Beach). While I have done some traveling in Europe before, I have never been to Spain or Hungary so I am really looking forward to experiencing the history and culture that these two cities have to offer.
Keep up With Me
I maintain a list of my presentations, both past and upcoming, on the Community Speaker page of this blog. I also try to document my conference experiences @bsstahl. If you are going to be attending any of these events, please be sure to ping me and let me know.
Tags: azgivecamp charity code camp conference givecamp microsoft nonprofit phoenix presentation schedule speaking user group visual studio
Testing the Untestable with Microsoft Fakes
Posted by bsstahl on 2017-03-20 and Filed Under: development
It is fairly easy these days to test code in isolation if its dependencies are abstracted by a reusable interface. But what do we do if the dependency cannot easily be referenced via such an interface? Enter Shims, from the Microsoft Fakes Framework(formerly Moles). Shims allow us to isolate our testing from any dependent methods, including methods in assemblies we do not control, even if those methods are not exposed through a reusable interface. To see how easy it is, follow along with me through this example.
In this sample code on GitHub, we are building a repository for an application that currently gets its data from a file exported from a system that tracks scheduled meetings. It is very likely that the system will, in the future, expose a more modern interface for that data so we have isolated the data storage using a simple Repository interface that has one method. This method, called GetMeetings returns a collection of Meeting entities that start during the specified date range. The method will return an empty collection if no data is found matching the specified criteria, and could throw either of 2 custom errors, a PermissionsExceptionwhen the user does not have the proper permissions to access the information, and a DataUnavailableException for when the data source is unavailable for any other reason, such as a network outage or if the data file cannot be located.
It is important to point out why a custom exception should be thrown when the data file is not found, rather than allowing the FileNotFoundException to bubble-up. If we allow the implementation-specific exception to bubble, we have exposed an implementation detail to the caller. That is, the calling code is now aware of the fact that this is a file system implementation. If code is written in a client that traps for FileNotFoundException, then the repository implementation is swapped-out for a SQL server implementation, the client code will have to change to handle the new types of errors that could be thrown by that implementation. This violates the Dependency Inversion principle, the “D” from the SOLID principles. By exposing only a custom exception, we are hiding those implementation details from the caller.
Downstream clients can easily test code that uses this repository without having to actually access the repository implementation because we have exposed the IMeetingSourceRepository interface. However, it is a bit more difficult to actually test the repository implementation itself. We have a few options here:
- Create data files that hold known data samples and load those files during unit testing.
- Create a wrapper around the System.IO namespace that exposes an interface, such as in the System.IO.Abstractions project.
- Don’t test any code that requires reaching-out to the file system.
Since I am of the opinion that 100% code coverage is both reasonable, and desirable (although not a measurable goal), I will summarily dispose of option 3 for the purpose of this analysis. I have used option 2 many times in my life, and while employing wrapper code is a valid and reasonable solution, it adds additional code to my production deployments that is very limited in terms of what it adds to the loose-coupling of my solution since I already am loosely-coupled to this implementation via the IMeetingSourceRepository interface.
Even though it is far from a perfect solution (many would consider them more integration tests than unit tests), I initially selected option 1 for this implementation. That is, I created data files and deployed them along with my tests. You can see the test files I created in the Data folder of the MeetingSystem.Data.FileSystem.Test project. These files are deployed alongside my tests using the DeploymentItem directive that decorates the Repository_GetMeetings_Should class of the test project. Using this method, I was able to create tests that:
- Verify that the correct # of meetings are returned from a file
- Verify that meetings are properly filtered by the StartDateTime of the meeting
- Validate the data elements returned from the file
- Validate that the proper custom exception is thrown if a FileNotFoundException is thrown by the underlying code
So we have verified nearly everything we need to test in our implementation. We’ve verified that the data is returned properly, and that one of our custom exceptions is being returned. But what about the PermissionsException? We were able to simulate a FileNotFoundException in our tests by just using a bad filename, but how do we test for a permissions problem? The ReadAllText method of the File object from System.IO will throw a System.Security.SecurityException if the file cannot be read due to a permissions problem. We need to trap this exception and throw our own exception, but how can we validate that we have successfully done so and that the functionality remains intact through future refactoring? How can we simulate a permissions exception on a file that we have enough permission on to deploy to a test folder? Enter Shims from the Microsoft Fakes Framework.
Instead of having our tests actually reach-out to the file system and actually try to load a file, we can intercept calls to the System.IO.File.ReadAllText method and have those calls execute some delegate code instead. This code, which we write in our test methods, can be specific to each test and exist only within the context of the test. As a result, we are not deploying any additional code to production, while still thoroughly validating our code. In fact, using this methodology, I could re-implement my previous tests, including my test data in the tests themselves, making these tests better unit tests. I could then reserve tests that actually reach out to files for integration test libraries that are run less frequently, and perhaps even behind the scenes.
Note: If you wish to follow-along with these instructions, you can grab the code from the DemoStart branch of the GitHub repo, rather than the Master branch where this is already done.
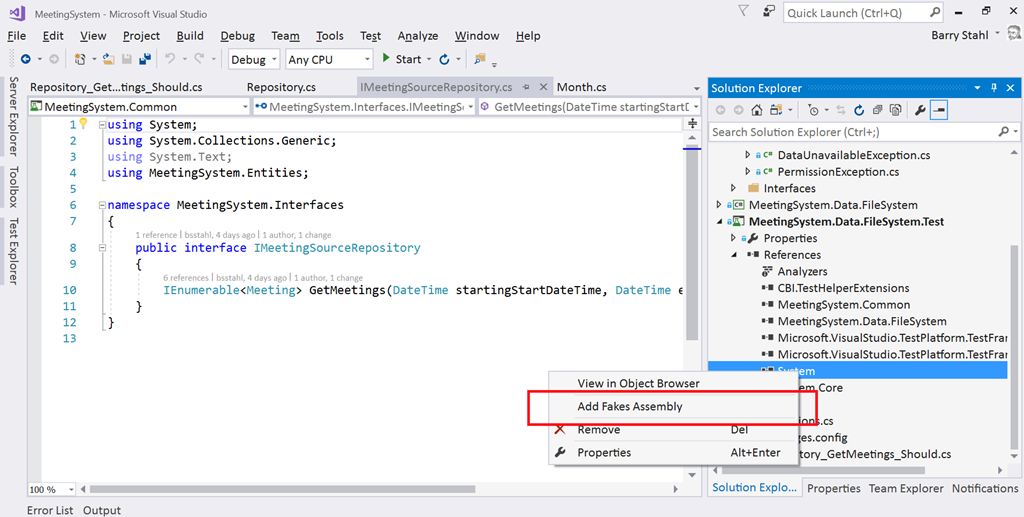
To use Shims, we first have to create a Fakes Assembly. This is done by right-clicking on the System reference in the test project from Visual Studio 2017, and selecting “Add Fakes Assembly” (full framework only – not yet available for .NET Core assemblies). Be sure to do this in the test project since we don’t want to actually deploy the Fakes assembly in our production code. Using the add fakes assembly menu item does 2 things:
- Adds a reference to Microsoft.QualityTools.Testing.Fakes assembly
- Creates 2 .fakes XML files in the Fakes folder within the test project. These items are built into corresponding fakes dll files that are deployed with the test project and used to provide stub and shim objects that mimic the objects in the selected assemblies. These fake objects reside in the same namespace as their “real” counterparts, except with “Fakes” on the end. Thus, our fake File object will reside in the System.IO.Fakes namespace.
The next step in using shims is to create a ShimsContext within a Using statement. Any method calls that execute within this context can be intercepted and replaced by our delegates. For example, a test that replaces the call to ReadAllText with a method that returns a single line of constant data can be seen below.
Methods on shim objects are referenced through properties of the fake object. These properties are of type FakesDelegate.Func and match the signature of the method being shimmed. The return data type is also appended to the property name so that each item’s signature can be represented with a different property name. In this case, the ReadAllText method of the File object is represented in the System.IO.Fakes.File object as a property called ReadAllTextString, of type FakesDelegate.Func<string, string>, since the method takes a string parameter (the path of the file), and returns a string (the text contents of the file). If we assign a method delegate to this property, that method will be executed in place of the call to System.IO.File.ReadAllText whenever ReadAllText is called within the ShimContext.
In the gist shown above, the variable p represents the input parameter and will hold the path specified in the test (in this case “April2017.abc”). The return value for our delegate method comes from the constant string dataFile. We can put anything we want here. We can replace the delegate with a call to an anonymous method, or with a call to an existing method. We can return a value gleaned from an external source, or, as is needed for our permissions test, throw an exception.
For the purposes of our test to verify that we throw a PermissionsException when a SecurityException is thrown, we can replace the value of the ReadAllTextString property with our delegate which throws the exception we need to test for, as seen here:
System.IO.Fakes.ShimFile.ReadAllTextString =
p => throw new System.Security.SecurityException("Test Exception");
Then, we can verify in our test that our custom exception is thrown. The full working example can be seen by grabbing the Master branch of the GitHub repo.
What can you test with these Shim objects that you were unable to test before? Tell me about it @bsstahl.
Tags: abstraction assembly code sample framework fakes interface moles mstest solid tdd testing unit testing visual studio
Demo Code for Testing in Visual Studio 2017
Posted by bsstahl on 2017-03-16 and Filed Under: event
The demo code for my presentation on Testing in Visual Studio 2017 at the VS2017 Launch event can be found on GitHub. There are 2 branches to this repository, the Main branch which holds the completed demo, and the DemoStart branch which holds the starting point of the demonstration in case you would like to implement the sample yourself.
The demo shows how Microsoft Fakes (formerly Moles) can be used to create tests against code that does not implement a reusable interface. This can be done without having to resort to integration style tests or writing extra wrapper code just to implement an interface. During my launch presentation, I also use this code to demonstrate the use of Intellitest (formerly Pex) to generate exploratory tests.
Tags: abstraction code sample coding-practices community conference development di interface microsoft moles mstest pex phoenix presentation tdd testing unit testing visual studio
Testing a .NET Core Library in VS2015
Posted by bsstahl on 2017-01-09 and Filed Under: development
I really enjoy working with .NET Core. I like the fact that my code is portable to many platforms and that the footprint is so much smaller than with traditional .NET applications. Unfortunately, the tooling has not quite reached the level that we expect from a Microsoft finished product (which it isn’t – yet). As a result, there are some additional actions we need to take when setting up our solutions in Visual Studio 2015 to allow us to unit test our code properly. The following are the steps that I currently take to setup and test a .NET Core library using XUnit and Moq. I know that a number of these steps will be done for us, or at least made much easier, by the tooling in the coming months, either by Visual Studio 2017, or by enhancements to the Visual Studio 2015 environments.
- Create the library to be tested in Visual Studio 2015
- File > New Project > .Net Core > Class Library
- Notice that this project is created in a solution folder called ‘src’
- Create a solution folder named ‘test’ to hold our test projects
- Right-click on the Solution > Add > New Solution Folder
- Add a new console application to the test folder as our test project
- Right-click on the ‘test’ folder > Add > New Project > .Net Core > Console Application
- Add a reference to the library being tested in the test project
- Right-click on the test project > Add > Reference > Select the library to be tested
- Install packages needed for unit testing from NuGet to the test project
- Right-click on the test project > Manage NuGet Packages > Browse
- Install ‘xunit’ as our unit test runner
- The current version for .Net Core is ‘2.2.0-beta4-build3444’
- Install ‘dotnet-test-xunit’ to integrate xunit with the Visual Studio test tools
- The current version for .Net Core is ‘2.2.0-preview2-build1029’
- Install ‘Moq’ as our mocking library
- The current version for .Net Core is ‘4.6.38-alpha’
- Edit the project.json of the test library
- Change the “EmitEntryPoint” option to false
- Add “testrunner” : “xunit” node
Some other optional steps include:
- Install the ‘Microsoft.CodeCoverage’ package from NuGet to enable the code coverage tooling
- Install the ‘Microsoft.Extension.DependencyInjection’ package from NuGet to enable DI
- Install the ‘TestHelperExtensions’ package from NuGet to add extensions that assist with writing good unit tests
- Add any additional runtimes that might be needed. Some options are:
- win10-x86
- win10-x64
- win7-x86
- win7-x64
- Set ‘Run tests after build’ in Visual Studio so tests run automatically
There will likely be better ways to do many of these things shortly, but if you know a better way now, please let me know @bsstahl.
Tags: testing code coverage development di ioc microsoft moq mocks professional development tdd unit testing visual studio dotnet
AZGiveCamp is Breaking the Mold
Posted by bsstahl on 2016-08-11 and Filed Under: event
The organizing team of AZGiveCamp recently announced that we would be hosting a one-day Hackathon for Humanitarian Toolbox on Saturday, August 27th, from 8:30 am to 5pm at Ticketmaster in Scottsdale, AZ. This event is a bit of a departure for us. We have been looking for ways to evolve the organization to host more and different coding-for-charity events while continuing our mission to to help charitable and non-profit organizations in our community meet their technology needs. We hope you’ll join us for this first experiment with other event types at AZGiveCamp.
AZGiveCamp’s flagship event is our Hackathon of Help. We have had the privilege of hosting 7 such events in the Valley of the Sun so far, with our 8th scheduled for March of 2017. These events take up an entire weekend and are designed to put multiple charity and non-profit organizations together with multiple development teams. The teams are tasked with taking a project from idea to completion in the course of one weekend. During these events, participants may chose to camp out at the event facility, stay up and work on their projects, or go home at night, returning to continue the project in the morning until the final turnover on Sunday afternoon. These events are technology agnostic, with the specific technologies to be used determined by the teams themselves.
By contrast, the AZGiveCamp Humanitarian Toolbox Hackathon will be only a 1-day event. Participants will work on a single project, the Humanitarian Toolbox (htBox) allReady project, for which the technologies, design, and many of the features have already been chosen and implemented. We will be lending our support to this worthy organization by adding features, upgrading tooling, and writing tests against the existing code base. This event will not be judged by how many projects we complete, but by how much better-off the project is when we are done.
For those not familiar with Humanitarian Toolbox, they are an organization that sets up projects to assist humanitarian organizations. Their current project, dubbed allReady, is designed to organize the preparedness campaigns of the Red Cross and other disaster response groups. The project is implemented in ASP.NET Core MVC with a Cordova client. Participants need to have at least a basic comfort level with one or both of these technologies, along with the appropriate development tools, to be an effective contributor to this project. Specifics of the required tools can be found on the event page on Meetup.
We hope you’ll join us at this and future AZGiveCamp events.
Tags: azgivecamp aspdotnet charity community givecamp ionic nonprofit open source phoenix visual studio apache cordova
No More Collection Objects
Posted by bsstahl on 2015-10-27 and Filed Under: development
I don't create collection objects anymore.
I know, I know. I was they guy always preaching that every entity that was being collected had to have its own collection object. It was the right thing at the time; if you needed to take an action on an enumeration or list of objects, those actions needed to be done within a strongly-typed collection object to maintain encapsulation. Even if all that was happening was that an inherited List<T> function was being called, that functionality needed to be called on the TCollection object because, if it wasn't, it was likely that the next time logic needed to be performed on the collection, there wouldn't be a place to put it. Collection logic would end up being spread-out around your code rather than encapsulated in the collection. It was also possible that the implementation might change and need to be updated everywhere, instead of in one place.
Today however, that has all changed. Extension methods now allow us, at any time, to add functionality to ICollection<T>, IList<T>, IEnumerable<T> or any other interface or class. We can attach our list or enumeration based actions directly to the list or enumeration class, and do so at any time, since the methods appear the same to the developer as methods directly on the collection type. Thus, the "no place to put it" fear no longer exists. I've even started using this technique for my factory methods to make it clear that what I am creating is, in fact, an IEnumerable<T>, as in this example.
var stations = (null as IEnumerable<Station>).Create();
var localStations = stations.GetNearby(currentLocation);
In this example, both the Create and GetNearby methods are extension methods found in a static class called StationExtensions.
So, the big advantage here is that these methods can be added anytime, meaning we don't need to create an object that we MAY need in the future. This is better adherence to the YAGNI principle so it is a better pattern to follow. But what about disadvantages? Does it hurt us in any way to perform our collection actions this way? I'm not comfortable answering that question with an absolute "no" yet because I don't think I've been using this technique long enough to have covered enough ground with it, but I can certainly say that I haven't found any disadvantages yet. It seems like these extension methods are basically perfect for this type of activity. These methods do everything that the methods of a collection object do, can (and should) be put in a separate module to keep the code together, can be navigated to by Visual Studio in the same way as other methods, and have the same access (private, internal, public) restrictions that collection objects have. About the only thing I can say that is not 100% positive about using these techniques is that the (null as IEnumerable<T>) syntax to create a local variable instance to call the class factory from is not quite as elegant as I'd like it to be.
So you tell me, do you still create collection objects? Have you found any reason why using extension methods in this way is not as good as putting those methods into a strongly-typed collection? Sound off in the Fediverse @bsstahl and let's talk about it.
Tags: class coding-practices csharp development encapsulation entity generics inheritance list visual studio yagni
Dynamic Optimization Presentation
Posted by bsstahl on 2015-10-21 and Filed Under: event
I hope you’ve had an opportunity to see my presentation, “Dynamic Optimization – One Technique all Programmers Should Know” at a Code Camp or User Group near you. If so, and you want to have a copy of the slide deck for your very own, you can see it embedded below, or use the direct link to the Powerpoint here.
The subject of this presentation is using a technique called Dynamic Programming to solve problems that have more than one possible solution. This technique works very well when used to solve problems that are recursive in nature. One of the best things about this technique is that it guarantees that the solution it produces is the best possible solution.
We look at three examples during the presentation, the first is done only “on paper” and is an example of using this technique to solve a knapsack problem. The second example is done in pseudo-code and solves a linear best-path problem in the game of Chutes & Ladders. Finally, we drop into Visual Studio to solve a 2-dimensional best-path problem. Sample code for both of the last 2 examples can be found in GitHub.
Keep an eye on my Speaking Engagements Page for opportunities to see this presentation live. If you are a user group or conference organizer, you can contact me to schedule an in-person presentation. This presentation is a lot of fun to deliver and has been received extremely well at Code Camps and User Groups across the country.
Tags: algorithms code camp code sample community conference development dynamic skill visual studio
Simplify Your API
Posted by bsstahl on 2015-10-12 and Filed Under: development
If you are building an API for other Developers to use, you will find out two things very quickly:
- Developers don't read documentation (you probably already know this).
- If your API depends on its documentation to get developers to understand and discover its features, it is likely that it will not be used.
Fortunately, there are some simple mechanisms for wrapping complex APIs and making their functionality both easy to use, and highly discoverable. An API that uses tools like IntelliSense in Visual Studio to make its features discoverable by the downstream developer is far more likely to be adopted then one that doesn't. In recent years, additions to the C# language have made creating a Domain Specific Language that uses a fluent syntax for nearly any API into a simple process.
Create the Context
The 1st step in simplifying any API is to provide a single starting point for the downstream developer to interact with. In most cases, the best practice is to use the façade pattern to define a context that holds our entity collections. Each collection of entities becomes a property on the context object. These properties all return an IQueryable<Entity>. For example, in the EnumerableStack demo solution on GitHub (https://github.com/bsstahl/SimpleAPI), I created an object Bss.EnumerableStack.Data.EnumerableStack to provide this functionality. It has two properties, Posts and Questions, each of which returns an IQueryable<Post>. It is these properties that will be used to access the data from our API.
The context object, on top of becoming the single point of entry for downstream developers, also hides any complexities in the construction logic of the underlying data source. That is, if there is any configuration or other setup required to access the upstream data provider (such as web service access or database connections), much of the complexity of that construction can be hidden from the API user. A good example of this can be seen in the FluentStack demo solution from the same GitHub repository. There, the Bss.FluentStack.Data.OData.FluentStack context object wraps the functionality of constructing the connection to the StackOverflow OData web service.
Extend Our Language
Now that we have data to access, it's time for us to extend our domain specific language to provide tools to make accessing this data simpler for the API caller. We can use Extension methods on IQueryable<Entity> to create custom filters for our data. By creating extension methods that accept IQueryable<Entity> as a parameter and return the same, we can create methods that can be chained together to form a fluent syntax that will perform complex filtering. For example, in the EnumerableStack solution , the Questions, WithAcceptedAnswer and TaggedWith methods found in the Bss.EnumerableStack.Data.Extensions module, can all be used to execute queries on the data exposed by the properties of our context object, as shown below:
var results = new EnumerableStack().Posts.WithAcceptedAnswer().TaggedWith("odata");
In this case, both the WithAcceptedAnswer and TaggedWith filters are applied to the data. The best part about these methods are that they are visible in Intellisense (once the namespace has been brought into scope with a Using statement) making the functionality easy to discover and use.
Another big advantage of creating these extension methods is that they can hide the complexity of the lower level API. Here, the WithAcceptedAnswer method is wrapping a where clause that filters for those posts that have an AcceptedAnswerId property that is non-null. It may not be obvious to a downstream API consumer that the definition of a post with an "accepted answer" is one where the AcceptedAnswerId has a value. Our API hides that implementation detail and allows the consumer to simply request what is needed. Similarly, the TaggedWith method hides the fact that the StackOverflow API stores tags in lower-case, within angle-brackets, and with all tags on a post joined into a single string. To search for tags, the consumer would need to know this, and take all appropriate actions when searching for a tag if we didn't hide that complexity in the TaggedWith method.
Simplify Query Predicates
A predicate is a function that accepts an entity as a parameter, and returns a boolean value. These functions are often used in the Where clause of a query to indicate which objects should be included in the result set. For example, in the query below
var results = new EnumerableStack().Posts.Where(p => p.Parent == null);
the function expression p => p.Parent == null is a predicate that returns true if the Parent property of the entity is null. For each entity passed to the function, the value of that property is tested, and if null, the entity is included in the results of the query. Here we are using a Lambda Expression to provide a delegate to our function. One of the coolest things about Linq is that we can now represent this expression in a variable of type Expression<Func<Entity, bool>>, that is, a Lambda expression of a function that takes an Entity and returns a boolean. This is pretty awesome because if we can store it in a variable, we can pass it around and enable extension methods like this one, as found in the Asked class of the Bss.EnumerableStack.Data library:
public static Expression<Func<Post, bool>> InLast(TimeSpan span)
{
return p => p.CreationDate > DateTime.UtcNow.Subtract(span);
}
This method accepts a TimeSpan object and returns the Lambda Expression type useable as a predicate. The input TimeSpan is subtracted from the current DateTime UTC value, and compared to the CreationDate property of a Post entity. If the creation date of the Post is later than 30-days prior to the current date, the function returns true. Since this InLast method is static on a class called Asked, we can use it like this:
var results = new EnumerableStack().Questions.Where(Asked.InLast(TimeSpan.FromDays(30));
Which will return questions that were asked in the last 30 days. This becomes even simpler to understand if we add a method extending Int called Days that returns a Timespan, like this:
public static TimeSpan Days(this int value)
{
return TimeSpan.FromDays(value);
}
allowing our expression to become:
var results = new EnumerableStack().Questions.Where(Asked.InLast(30.Days());
Walking through the Process
In my conference sessions, Simplify Your API: Creating Maintainable and Discoverable Code, I walk through this process on the FluentStack demo code. We take a query created against the StackOverflow OData API that starts off looking like this:
var questions = new StackOverflowService.Entities(new Uri(_serviceRoot))
.Posts.Where(p => p.Parent == null && p.AcceptedAnswerId != null
&& p.CreationDate > DateTime.UtcNow.Subtract(TimeSpan.FromDays(30))
&& p.Tags.Contains("<odata>"));
and convert it, one step at a time, to this:
var questions = new FluentStack().Questions.WithAcceptedAnswer()
.Where(Asked.InLast(30.Days)).TaggedWith("odata");
a query that is much simpler, easier to understand, easier to create and easier to maintain. The sample code on GitHub, referenced above, and available at https://github.com/bsstahl/SimpleAPI, contains the FluentStack.sln example which shows how to simplify an API created with an OData source. It also contains the EnumerableStack.sln project which walks through the same process on a purely enumerable data source, that is, an implementation that will work with any collection.
Sound Off
Have you used these tools to simplify an API for downstream programmers? Do you have other techniques that you use to do the same, similar, or additional things to make your APIs better? If so, send it to me @bsstahl and let's keep the conversation going.
Tags: api coding-practices code sample development generics presentation services skill speaking visual studio soa
Introducing TestHelperExtensions
Posted by bsstahl on 2015-08-26 and Filed Under: development
TL;DR Version
I've released a new Open-Source library of extension methods that can be used to create more effective unit and integration tests. This library is called TestHelperExtensions. The source code is available on GitHub (pull requests welcome), a .NET 4 package is available via NuGet, and the documentation is available here. The goal is to allow anyone to have access to the same set of test helpers I have been using, and building up, for many years.
The Story
I have been giving Test Driven Development (TDD) sessions at code camps and conferences for a number of years. During those sessions, I spend a lot of time in code, building up a test suite for a production application, and demonstrating the process I use for TDD. Part of this process is using a set of extension methods to perform common tasks, such as generating test data, and doing comparisons of DateTime values. Many people have asked for access to this library during these sessions and my answer has always been the same, "you can grab it from the sample code". Now, I've decided to make it easier for anyone to include it in their projects via NuGet, and to allow the community the opportunity to extend and modify the library on GitHub.
Going Forward
I still have a small backlog of features I'd like to add to this tool. After that, It's up to you what happens with it. If you have a feature suggestion, please let me know. @bsstahl is the best place to start a conversation about this, or any development topic with me. You can also create an issue on GitHub, or simply submit a pull request. I'd love to hear how you are using this library, and anything that can be done to make it more effective for you.
Tags: agile community development framework open source tdd testing unit testing visual studio
Are you Ready for the Next Episode?
Posted by bsstahl on 2015-06-29 and Filed Under: development
In the last episode of “Refactoring my App Development Mojo”, I explained how I had discovered my passion for building Windows Store applications by using a hybrid solution of HTML5 with very minimal JavaScript, bound to a view-model written in C# running as a Windows Runtime Component, communicating with services written in C# using WCF. The goal was to do as much of the coding as possible in the technologies I was very comfortable with, C# and HTML, and minimize the use of those technologies which I had never gotten comfortable with, namely JavaScript and XAML.
While this was an interesting and somewhat novel approach, it turned out to have a few fairly significant drawbacks:
- Using this hybrid approach meant there were two runtimes that had to be initialized and operating during execution, a costly drain on system resources, especially for mobile devices.
- Applications built using this methodology would run well on Windows 8 and 8.1 machines, as well as Windows Phone devices, but not on the web, or on Android or iDevices.
- The more complex the applications became, the more I hand to rely on JavaScript anyway, even despite putting as much logic as possible into the C# layers.
On top of these drawbacks, I now feel like it is time for me to get over my fear of moving to JavaScript. Yes, it is weakly typed (at least for now). Yes, its implementation of many object-oriented concepts leave a lot to be desired (at least for now), yes, it can sometimes make you question your own logical thinking, or even your sanity, with how it handles certain edge-cases. All that being said however, JavaScript, in some form, is the clear winner when it comes to web applications. There is no question that, if you are building standard front-ends for you applications, you need JavaScript.
So, it seems that it is time for me to move to a more standard front-end development stack. I need one that is cross-platform, ideally providing a good deployment story for web, PC, tablet & phone, and supporting all major platforms including Android, iDevices & Windows phones and tablets. It also needs to be standards-based, and work using popular frameworks so that my apps can be kept up-to-date with the latest technology.
I believe I have found this front-end platform in Apache Cordova. Cordova takes HTML5/JavaScript/CSS3 apps that can already work on the web, and builds them into hybrid apps that can run on virtually any platform including iPhones and iPads, Android phones and tablets, and Windows PCs, phones and tablets. Cordova has built-in support in Visual Studio 2015, which I have been playing with for a little while and seems to have real promise. There is also the popular Ionic Framework for building Cordova apps which I plan to learn more about over the next few weeks.
I’ll keep you informed of my progress and let you know if this does indeed turn out to be the best way for me to build apps. Stay tuned.
Tags: development device framework html5 ionic javascript open source phone standardization visual studio xaml windows apache cordova
Visual Studio Unit Test Generator
Posted by bsstahl on 2013-08-05 and Filed Under: development
As a follow-up to my posts here and here on the missing “Create Unit Test” feature in VS2012, I point you to this post from the Visual Studio ALM & TFS blog announcing the Release Candidate of their new Unit Test Generator for Visual Studio. According to the post, this extension
“…adds the “create unit test” feature back, with a focus on automating project creation, adding references and generating stubs, extensibility, and targeting of multiple test frameworks.”
I am installing the extension now and will comment on how well it works for my TDD workflow in a future post.
Tags: visual studio unit testing testing tdd
Regain Access to the CreateUnitTests Command in VS2012
Posted by bsstahl on 2012-12-27 and Filed Under: development
I previously expressed my annoyance here and here (starting at 01:02:06) about the lack of the Create Unit Tests feature in Visual Studio 2012, similar to the one in Visual Studio 2010. It is interesting that none of the Microsoft people I’ve spoken to on the issue were able to provide me with a reasonable work-around, but apparently, intrueder, a commenter at Stack Overflow, has. It turns out that the functionality was not removed from the Visual Studio product, just from the context menu. Therefore, we can give ourselves access to the command again by assigning a keyboard shortcut to it. The steps to do so are as follows:
- In Visual Studio 2012, select Options from the Tools menu on the top menu bar.
- In the Environment section of the dialog, select Keyboard. This will show you a list of commands and their keyboard shortcuts if they have one.
- In the Show commands containing box, type CreateUnitTests. You should see the command window filter down to the EditorContextmenus.CodeWindow.CreateUnitTests command, which will be highlighted.
- If there is anything shown in the Shortcuts for selected command drop-down, you are already done. You can use whatever key sequence is listed to access the command as described below.
- If there is nothing shown, you’ll need to assign a keyboard shortcut. Press the key sequence you’d like to use while in the Press shortcut keys text box. If that shortcut is already assigned, the Shortcut currently used by drop-down will change to show how the key sequence is currently used. You may have to try several key combinations before you find one that you are comfortable using, especially if you use a product like Resharper which maps a bunch of additional shortcuts on top of the Visual Studio default key mappings.
- Once you decide on a key sequence and those keys (or key) appear in the Press shortcut keys text box, press the Assign button to map the sequence to the command. You can now use that key sequence to access the CreateUnitTests command as described below.
Now that a shortcut is setup, all you have to do is place the cursor within the scope that you want to create unit tests for (a namespace, class or method) and invoke the key sequence. The command should be activated as it was in Visual Studio 2010. I have been using this for a little while and it is working quite well for me, but I don’t make use of nearly all of the features of this command. I’ll be interested to hear if you have any troubles using this tool in this way. You can contact me @bsstahl if you have any comments.
Tags: visual studio unit testing tdd
The Missing “Create Unit Test” feature in Visual Studio 2012
Posted by bsstahl on 2012-09-16 and Filed Under: development
I am loving many of the improvements made in Visual Studio 2012. The performance and overall user experience of the test runner has improved tremendously from Visual Studio 2010 and the IDE is generally a joy to use. Unfortunately, I can’t use it. It is missing one of the key features I use in my development workflow, that is, the “Create Unit Test” option. This function, in VS2010, generates the stub of unit tests based on the interfaces of the selected methods. It is hard for me to imagine why this feature was left out of Visual Studio 2012, but it needs to be put back in immediately.
Please let Microsoft know how you feel about the absence of this feature in VS2012 by voting the feature request up on UserVoice.
Tags: visual studio unit testing tdd
Code Sample for My TDD Kickstart Sessions
Posted by bsstahl on 2012-02-13 and Filed Under: development
The complete, working application for my .NET TDD Kickstart sessions can be found here.
Unzip the files into a solution folder and open the Demo.sln solution in a version of Visual Studio 2010 that has Unit Testing capability (Professional, Premium or Ultimate). Immediately, you should be able to compile the whole solution, and successfully execute the tests in the Bss.QueueMonitor.Test and Bss.Timing.Test libraries.
To get the tests in the other two test libraries (Bss.QueueMonitor.Data.EF.Test & Bss.QueueMonitor.IntegrationTest) to pass, you will need to create the database used to store the monitored data in the data-tier and integration tests, and enable MSMQ on your system so that a queue to be monitored can be created for the Integration test.
The solution is configured to use a SQLExpress database called TDDDemo. You can use any name or SQL implementation you like, you’ll just need to update the configuration of all of the test libraries to use the new connection. The script to execute in the new database to create the table needed to run the tests can be found in the Bss.QueueMonitor.Data.EF library and is called QueueDepthModel.edmx.sql.
You can install Message Queuing on computers running Windows 7 by using Programs and Features in the Control Panel. You do not need to create any specific queue because the integration test creates a queue for each test individually, then deletes the queue when the test is complete.
If you have any questions or comments about this sample, please start a conversation in the Fediverse @bsstahl or Contact Me.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di event framework ioc tdd testing unit testing visual studio
.NET TDD Kickstart
Posted by bsstahl on 2012-01-26 and Filed Under: event development
I head out to Fullerton tomorrow for the start of my .NET TDD Kickstart world tour. 
In this session, the speaker and the audience will "pair up" for a coding session which will serve as an introduction to Test Driven Development in an Agile environment. We will use C#, Visual Studio and Rhino Mocks to unit test code to be built both with and without dependencies. We will also highlight some of the common issues encountered during TDD and discuss strategies for overcoming them.
I will be presenting this session at numerous venues around the country this year, including, so far:
- Southern California Code Camp – Fullerton in January
- South Florida Code Camp – Ft. Lauderdale in February
- New Mexico .NET User’s Group – Albuquerque in March
- Twin Cities Code Camp – Minneapolis in April
If you are interested in having me present this or another session at your event, please contact me.
There is much more than an hour’s worth of material to be presented, so instead of trying to rush through everything I want to talk about during this time, I’ve instead taken some questions from this presentation and posted them below. Please contact me if you have any additional questions, need clarification, or if you have an suggestions or additions to these lists.
Update: I have moved the FAQ list here to allow it to be maintained separately from this post.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di framework ioc tdd testing unit testing visual studio
Demo Code for EF4Ent Sessions
Posted by bsstahl on 2011-06-26 and Filed Under: development
I previously posted the slides for my Building Enterprise Apps using Entity Framework 4 talk here. I can now post the source code for the completed demo application. That code, created for use in Visual Studio 2010 Ultimate, is available in zip format below. This is the same code that was demonstrated at Desert Code Camp 2011.1 and SoCalCodeCamp 2011 as well as the New Mexico .NET User’s Group (NMUG).
Tags: abstraction agile assembly code analysis code camp code contracts code sample coding-practices conference csharp enterprise library entity entity framework fxcop interface testing unit testing visual studio
Code Analysis Rules
Posted by bsstahl on 2011-06-07 and Filed Under: development
FxCop, the built-in code-analysis tool in Visual Studio, is the first thing I check when doing a code review. If Code Analysis is enabled for a project, setup properly, and its rules have not been overridden, this tool will help maintain consistency in the code, even if that code is worked on by multiple developers. FxCop also does a good job of identifying if some common mistakes have been made, such as not disposing of an IDisposable object, and can identify things that will help the compiler do its job better, such as ensuring that assemblies which expose public objects identify whether or not they are intended to be CLS compliant.
In order to get these benefits, code analysis must be enabled for each project and a rule set must be selected. Because adding code-analysis to existing assemblies can be a bit painful, it is recommended that you enable this analysis as soon as a project is created in Visual Studio. To enable code analysis for an assembly, select the project properties, go to the Code Analysis tab, and check the “Enable Code Analysis on Build (defines CODE_ANALYSIS constant)” box.
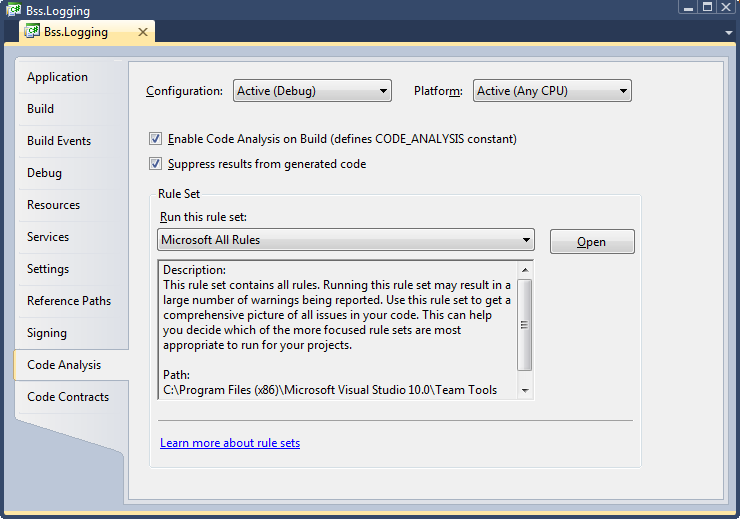
The default rule set that will be run during code analysis is called “Microsoft Minimum Recommended Rules”. This is a very small set of rules that is a good one to enable if you are starting to do code analysis on a previously coded assembly. If however, you are starting clean, I highly recommend starting with either the “Microsoft All Rules” rule set, or your own version of that set, since this rule set will provide the most benefit in all areas of analysis. To create your own rule sets, select the set you wish to modify and press the “Open” button next to the rule set drop-down. Once opened, you can make any changes you wish, and use the File –> Save-as menu item to save the rule set with a different file name. New rule sets will automatically appear in the drop-down menu. You can use the properties tab to update the Name and Description of the set, and the rules editor to enable or disable individual rules. You can also define, for each rule, whether failures are ignored, result in a warning, or generate a compilation error. I highly recommend setting all rules that you want to enforce to cause errors since they can always be overridden if necessary but will likely be missed if they only result in warnings.
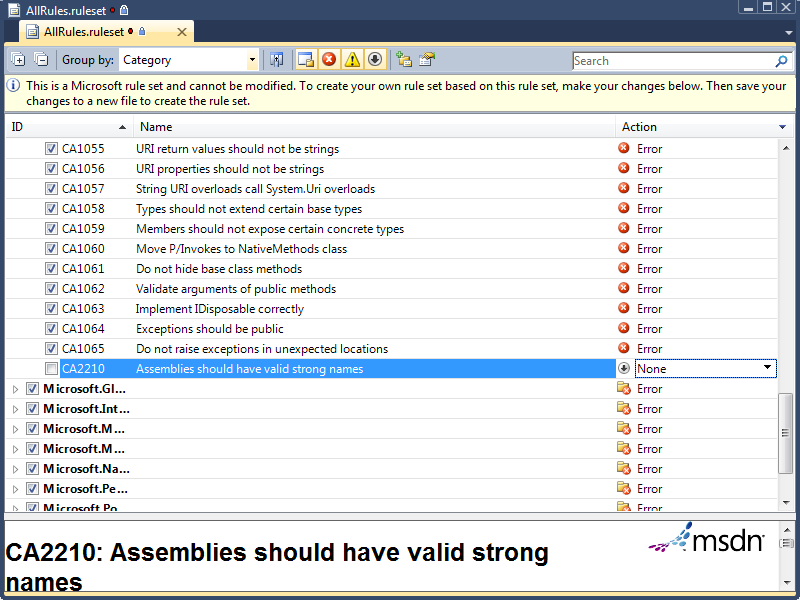
For my projects, I use one of several rule sets that I have set up, all of which are slight modifications to the “Microsoft All Rules” rule set. I will detail the rule set changes I make and overrides that I allow in each set of circumstances below. I encourage you to experiment with these rule sets to determine the optimum configuration for your projects.
All Projects
- Modify the “Microsoft All Rules” rule set so that all rules result in an error. The easiest way to do this is to use the “group by” drop-down to order all rules by “Target Type”. The only type found here should be “Managed Code”. With this single group collapsed, use the Action drop-down to select “Error” for all rules.
Entity Framework Projects
- The Entity Framework requires navigation properties of entities to be read-write, a violation of rule CA2227, “Collection properties should be read only”. For projects utilizing the Entity Framework, as well as those designed for use within the entity framework (such as entity POCO libraries), the action of this rule may be set to “Warning” to prevent compilation errors whenever entities with navigation properties are built.
Projects Deployed to Internal Company Servers (and not GAC’ed)
- Assemblies that will not be deployed to the GAC and will remain on secure, internal servers do not need to have a strong name. Thus, rule CA2210, “Assemblies should have valid strong names”, can be permanently over-ridden or have its action set to “None”.
Non-Localized Projects
- For projects that are never to be localized to a foreign culture, you can set the action for rule CA1303, “Do not pass literals as localized parameters”, back to “Warning”. I find this rule to be especially incorrect when I am writing logging code within my methods (unless using aspect-orientation) because the logging code also serves as functional code-comments if the literals are included in the method calls.
Console Applications
- Many console apps ignore the command-line parameters passed-in to the main method, a violation of rule CA1801, “Review Unused Parameters”. Most of the time, this rule is valuable since you don’t want to have parameters to methods that are never used, however, since we cannot change the parameters to the main method of a console app, but may not wish to use them, this rule can be set to generate a warning in console applications, or can be simply overridden for the parameters to the main method of each console app. This rule may also be violated temporarily when a method has been stubbed but not yet implemented. In that case, the rule should be overridden in code similar to rule CA1822 below.
Other (More Temporary) Modifications
- Rule CA1822, “Mark members as static”, is violated when a method in a class does not use any of the other non-static members of the class. This is always true when the method has not yet been implemented (is only a stub). Prior to the method being implemented, this rule should be overridden in code. The override should be removed from the code once the method has been implemented.
- Rule CA1040, “Avoid empty interfaces” is often violated temporarily in TDD/BDD because interfaces may be created without methods and then be built-up as needed by the use-case. Prior to the interface being defined, this rule should be overridden in code. The override should be removed from the code once the interface has been defined.
I have found using Code Analysis to be a good way to improve the maintainability of my applications, especially when the app is being worked on by multiple members of a project team. The FxCop tool, built into Visual Studio’s Ultimate and Premium editions, is one of a number of tools and techniques I use to keep my code as maintainable and extensible as possible, resulting in the lowest possible total cost of ownership (TCO). In future articles, I will explore additional tools and techniques I use for this purpose.
Tags: code analysis assembly entity framework fxcop logging strong name visual studio
PDC Day 1
Posted by bsstahl on 2003-10-29 and Filed Under: event
Day 1 of the 2003 PDC was mainly architectural overviews of many of the up-and-coming features of the new Microsoft platforms and tools. The Keynote by Bill Gates and Jim Allchin gave many of us our first look at the new features of Longhorn, the code-name for Microsofts next generation operating system. The three key features of Longhorn that were demonstrated were: Indigo - the tools to implement application architectures built on the services model, WinFS - file system improvments that will allow us to organize and view data in new and innovative ways, and Avalon - the presentation engine that takes advantage of Indigo and WinFS (among other things). More details of this presentation are available here from Microsoft.

Afternoon breakout sessions included an Architectural overview of Whidbey, the code name for the next generation of Visual Studio .NET development tool. I also was lucky enough to see what was possibly the best presentation I have ever seen. This presentation, given by Don Box and entitled "Indigo": Services and the Future of Distributed Applications is a must-see and will hopefully be made available on Microsoft's website. Don related this history of object-oriented development to the current enhancements of the services architecture, and presented key guidelines for developing using this architecture, both now and in the future.
Tomorrow, I intend to look further under the covers of a number of these technologies including Whidbey, Indigo, Avalon, and possibly Yukon, the code-name for the next generation SQL server.
