Tag: optimization
Simple Linear Regression
Posted by bsstahl on 2023-02-13 and Filed Under: development
My high-school chemistry teacher, Mrs. J, had a name for that moment when she could see the lightbulb go on over your head. You know, that instant where realization hits and a concept sinks-in and becomes part of your consciousness. The moment that you truly "Grok" a principle. She called that an "aha experience".
One of my favorite "aha experiences" from my many years as a Software Engineer, is when I realized that the simplest neural network, a model with one input and one output, was simply modeling a line, and that training such a model, was just performing a linear regression. Mind. Blown.
In case you haven't had this particular epiphany yet, allow me to go into some detail. I also discuss this in my conference talk, A Developer's Introduction to Artificial Intelligences.
Use Case: Predict the Location of a Train
Let's use the example of predicting the location of a train. Because they are on rails, trains move in 1-dimensional space. We can get a good approximation of their movement, especially between stops, by assuming they travel at a consistent speed. As a result, we can make a reasonably accurate prediction of a train's distance from a particular point on the rail, using a linear equation.
If we have sensors reporting the location and time of detection of our train, spread-out across our fictional rail system, we might be able to build a graph of these reports that looks something like this:
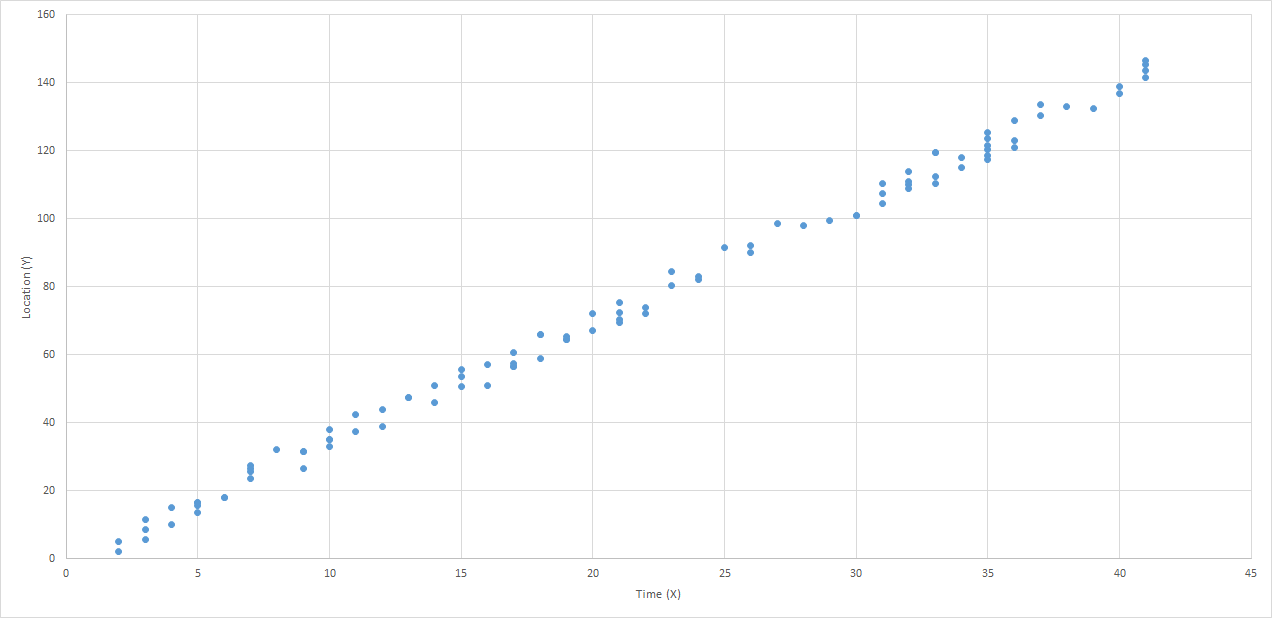
I think it is clear that this data can be represented using a "best-fit line". Certainly there is some error in the model, perhaps due to sensor or reporting errors, or maybe just to normal variance of the data. However, there can be no doubt that the best fit for this data would be represented as a line. In fact, there are a number of tools that can make it very easy to generate such a line. But what does that line really represent? To be a "best-fit", the line needs to be drawn in such a way as to minimize the differences between the values found in the data and the values on the line. Thus, the total error between the values predicted by our best-fit line, and the actual values that we measured, is as small as we can possibly get it.
A Linear Neural Network
A simple neural network, one without any hidden layers, consists of one or more input nodes, connected with edges to one or more output nodes. Each of the edges has a weight and each output node has a bias. The values of the output nodes are calculated by summing the product of each input connected to it, along with its corresponding weight, and adding in the output node's bias. Let's see what our railroad model might look like using a simple neural network.
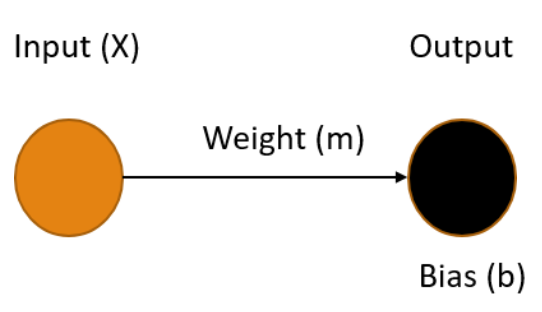
Ours is the simplest possible neural network, one input connected to one output, where our X value (time) is the input and the output Y is our prediction of the distance the train has traveled in that time. To make the best prediction we need to determine the values for the weight of the edge m and the bias of the output node b that produce the output that minimizes the errors in the model.
The process of finding the weights and biases values for a neural network that minimize the error is know as Training the model. Once these values are determined, we use the fact that we multiply the weight by the input (m * X) and add in the bias. This gives us an equation in the form:
Y = mX + b
You may recognize this as the slope-intercept form of the equation for a line, where the slope m represents the speed of the train, and the bias b represents the starting distance from the origin. Once our training process gives us values for m and b, we can easily plug-in any value for X and get a prediction for the location of our train.
Training a Model
Training an AI model is simply finding the set of parameters that minimize the difference between the predicted output and the actual output. This is key to understanding AI - it's all about minimizing the error. Error minimization is the exact same goal as we have when performing a linear regression, which makes sense since these regressions are predictive models on their own, they just aren't generally depicted as neural networks.
There are many ways to perform the error-minimization process. Many more complicated models are trained using an iterative optimization routine called Gradient Descent. Extremely simple models like this one often use a less complicated process such as Ordinary Least Squares. The goals are the same however, values for weights and biases in the model are found that minimize the error in the output, resulting in a model can make the desired predictions based on known inputs.
Regardless of the method used, the realization that training the simplest neural network results in a model of a line provided the "aha experience" I needed as the foundation for my understanding of Machine Learning models. I hope, by publishing this article, that others may also benefit from this recognition.
Tags: ai algorithms ml optimization presentation
The Value of Flexibility
Posted by bsstahl on 2019-02-14 and Filed Under: development
Have you ever experienced that feeling you get when you need to extend an existing system and there is an extension point that is exactly what you need to build on?
For example, suppose I get a request to extend a system so that an additional action is taken whenever a new user signs-up. The system already has an event message that is published whenever a new user signs-up that contains all of the information I need for the new functionality. All I have to do is subscribe a new microservice to this event message, and have that service take the new action whenever it receives a message. Boom! Done.
Now think about the converse. The many situations we’ve all experienced where there is no extension point. Or maybe there is an extension mechanism in place but it isn’t quite right; perhaps an event that doesn’t fire on exactly the situation you need, or doesn’t contain the data you require for your use case and you have to build an entirely new data support mechanism to get access to the bits you need.
The cost to “go live” is only a small percentage of the lifetime total cost of ownership. – Andy Kyte for Gartner Research, 30 March 2010
There are some conflicting principles at work here, but for me, these situations expose the critical importance of flexibility and extensibility in our application architectures. After all, maintenance and extension are the two greatest costs in a typical application’s life-cycle. I don’t want to build things that I don’t yet need because the likelihood is that I will never need them (see YAGNI). However, I don’t want to preclude myself from building things in the future by making decisions that cripple flexibility. I certainly don’t want to have to do a full system redesign ever time I get a new requirement.
For me, this leads to a principle that I like to follow:
I value Flexibility over Optimization
As with the principles described in the Agile Manifesto that this is modeled after, this does not eliminate the item on the right in favor of the item on the left, it merely states that the item on the left is valued more highly. This makes a ton of sense to me in this case because it is much easier to scale an application by adding instances, especially in these heady days of cloud computing, than it is to modify and extend it. I cannot add a feature by adding another instance of a service, but I can certainly overcome a minor or even moderate inefficiency by doing so. Of course, there is a cost to that as well, but typically that cost is far lower, especially in the short term, than the cost of maintenance and extension.
So, how does this manifest (see what I did there?) in practical terms?
For me, it means that I allow seams in my applications that I may not have a functional use for just yet. I may not build anything on those seams, but they exist and are available for use as needed. These include:
- Separating the tiers of my applications for loose-coupling using the Strategy and Repository patterns
- Publishing events in event-driven systems whenever it makes sense, regardless of the number of subscriptions to that event when it is created
- Including all significant data in event messages rather than just keys
There are, of course, dangers here as well. It can be easy to fire events whenever we would generally issue a logging message. Events should be limited to those in the problem domain (Domain Events), not application events. We can also reach a level of absurdity with the weight of each message. As with all things, a balance needs to be struck. In determining that balance, I value Flexibility over Optimization whenever it is reasonable and possible to do so.
Do you feel differently? If so, let me know @bsstahl.
Tags: abstraction agile coding-practices microservices optimization pattern principle flexibility yagni event-driven
Developer on Fire
Posted by bsstahl on 2018-12-13 and Filed Under: general
I was recently interviewed by Dave Rael (@raelyard) for his Developer on Fire Podcast. I had a great time talking with Dave about a lot of different things, both professional and personal, and got to name-drop just a few of the many people who have been a part of my journey over the years.
I also took the opportunity to talk about a few things that have been on my mind:
- The upcoming AZGiveCamp Event scheduled for March 2019
- Some of the giants on whose shoulders we stand
- A few of the technologies that are making me happy right now:
- A couple of resources I learn from:
- brilliant.org
- The works of David McRaney
I hope you enjoy this interview and find something of value in it. If so, please let me know about it @bsstahl.
Tags: ai azgivecamp community givecamp podcast blazor webassembly optimization algorithms
Desert Code Camp – October 2017
Posted by bsstahl on 2017-10-16 and Filed Under: event
Another great Desert Code Camp is in the books. A huge shout-out to all of the organizers, speakers & attendees for making the event so awesome.
I was privileged to be able to deliver two talks during this event:
A Developer’s Survey of AI Techniques: Artificial Intelligence is far more than just machine learning. There are a variety of tools and techniques that systems use to make rational decisions on our behalf. In this survey designed specifically for software developers, we explore a variety of these methods using demo code written in c#. You will leave with an understanding of the breadth of AI methodologies as well as when and how they might be used. You will also have a library of sample code available for reference.
- Code Samples: GitHub Repo
- Slide Deck: PDF
AI that can Reason "Why": One of the big problems with Artificial Intelligences is that while they are often able to give us the best possible solution to a problem, they are rarely able to reason about why that solution is the best. For those times where it is important to understand the why as well as the what, Hybrid AI systems can be used to get the best of both worlds. In this introduction to Hybrid AI systems, we'll design and build one such system that can solve a complex problem for us, and still provide information about why each decision was made so we can evaluate those decisions and learn from our AI's insights.
- Code Samples: GitHub Repo
- Slide Deck: PDF
Please feel free to contact me @bsstahl with any questions or comments on these or any of my presentations.
Tags: ai algorithms code camp code sample community conference optimization presentation professional development phoenix slides speaking
An Example of a Hybrid AI Implementation
Posted by bsstahl on 2017-10-13 and Filed Under: development
I previously wrote about a Hybrid AI system that combined logical and optimization methods of problem solving to identify the best solution to an employee shift assignment problem. This implementation was notable in that a hybrid approach was used so that the optimal solution could be found, but the system could still indicate to the users why a particular assignment was, or wasn’t, included in the results.
I recently published to GitHub a demo of a similar system. I use this demo in my presentation Building AI Solutions that can Reason Why. The code demonstrates the hybridization of multiple AI techniques by creating a solution that iteratively applies a combinatorial optimization engine. Different results are obtained by varying the methods of applying the constraints in that model. In the final (4th) demo method, an iterative process is used to identify what the shortcomings of the final product are, and why they are necessary.
These demos use the Conference Scheduler AI project to build a valid schedule.
There are 4 examples, each of which reside in a separate test method:
ScheduleWithNoRestrictions()
The 1st method in BasicExamplesDemo.cs shows an unconstrained model where only the hardest of constraints are excluded. That is, the only features of the schedule that are considered by the scheduler are those that are absolute must-haves. Since there are fewer hard constraints, it is relatively easy to satisfy all the requirements of this model.
ScheduleWithHardConstraints()
The 2nd method in BasicExamplesDemo.cs shows a fully constrained model where all constraints are considered must-haves. That is, the only schedules that will be considered for our conference are those that meet all of the scheduling criteria. As you might imagine, this can be difficult to do, in this case resulting in No Feasible Solution being found. Because we use a combinatorial optimization model, the system gives us no clues as to which of the constraints cause the infeasibility, or what to do that might allow it to find a solution.
ScheduleWithTimePreferencesAsAnOptimization()
The 3rd method in BasicExamplesDemo.cs shows the solution when the true must-haves are considered hard constraints but preferences are not. The AI attempts to optimize the solution by satisfying as many of the soft constraints (preferences) as possible. This results in an imperfect, but possibly best case schedule, but one where we have little insight as to what preferences were not satisfied, and almost no insight as to why.
AddConstraintsDemo()
The final demo, and the only method in AddConstraintsDemo.cs, builds on the 3rd demo, where the true must-haves are considered hard constraints but preferences are not. Here however, instead of attempting to optimize the soft constraints, the AI iteratively adds the preferences as hard constraints, one at a time, re-executing the solution after each to make sure the problem has not become infeasible. If the solution has become infeasible, that fact is recorded along with what was being attempted. Then that constraint is removed and the process continues with the remaining constraints. This Hybrid process still results in an imperfect, but best-case schedule. This time however, we not only know what preferences could not be satisfied, we have a good idea as to why.
The Hybrid Process
The process of iteratively executing the optimization, adding constraints one at a time, is show in the diagram below. It is important to remember that the order in which these constraints are added here is critical since constraining the solution in one way may limit the feasibility of the solution for future constraints. Great care must be taken in selecting the order that constraints are added in order to obtain the best possible solution.
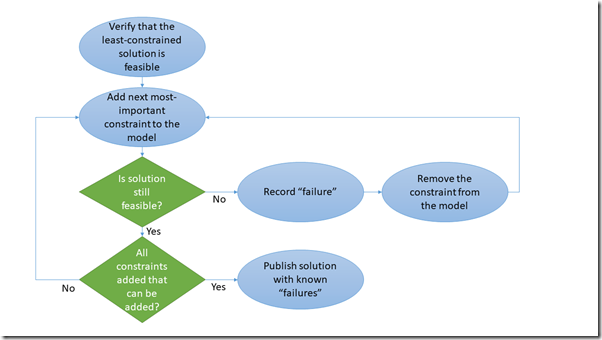
The steps are as follows:
- Make sure we can solve the problem without any of the soft constraints. If the problem doesn’t have any feasible solutions at the start of the process, we are certainly not going to find any by adding constraints.
- Add a constraint to the solution. Do so by selecting the next most important constraint in order. In the case of our conference schedule, we are adding in speaker preferences for when they speak. These preferences are being added in the order that they were requested (first-come first-served).
- Verify that there is still at least 1 feasible solution to the problem after the constraint is added. If no feasible solutions can be found:
- Remove the constraint.
- Record the details of the constraint.
- Record the current state of the model.
- Repeat steps 2 & 3 until all constraints have been tried.
- Publish the solution
- The resulting schedule
- The constraints that could not be added. This tells us what preferences could not be accommodated.
- The state of the model at the time the failed constraints were tried. This give us insight as to why the constraints could not be satisfied.
Note: The sample data in these demos is very loosely based on SoCalCodeCamp San Diego from the summer of 2017. While some of the presenters names and presentations come roughly from the publicly available schedule, pretty much everything else has been fictionalized to make for a compelling demo, including the appearances by some Microsoft rock stars, and the "requests" of the various presenters.
If you have any questions about this code, or about how Hybrid AIs can be used to provide more information about the solutions to problems than strictly optimization or probabilistic models, please contact me @bsstahl.
Tags: ai algorithms code camp code sample coding-practices conference open source optimization presentation
Scalable Decision Making
Posted by bsstahl on 2017-06-01 and Filed Under: development
I recently had a developer colleague return from an AI conference and tell me something along the lines of "…all they really showed were algorithms, nothing that really learned." Unfortunately, there is this common misconception, even among people in the software community, that to have an AI, you need Machine Learning. Now don't get me wrong, Machine Learning is an amazing technique and it has been used to create many real breakthroughs in Software Engineering. But, to have AI you don't need Machine Learning, you simply need a system that makes decisions that otherwise would need to be made by humans. That is, you need a machine to act rationally. There are many ways to accomplish this goal. I have explored a few methods in this forum in the past, and will explore more in the future. Today however, I want to discuss the real value proposition of AI. That is, the ability to make decisions at scale.
The value in AI comes not from how the decisions are made, but from the ability to scale those decisions.
I see 4 types of scale as key in evaluating the value that Artificial Intelligences may bring to a problem. They are the solution space, the data requirements, the problem space and the volume. Let's explore each of these types of scale briefly.
Solution Space
The solution space consists of all of the possible answers to a question. It is the AIs job to evaluate the different options and determine the best decision to make under the circumstances. As the number of options increases, it becomes more and more important for the decisions to be made in an automated, scalable way. Artificial Intelligences can add real value when solving problems that have very large solution spaces. As an example, let's look at the scheduling of conference sessions. A very small conference with 3 sessions and 3 rooms during 1 timeslot is easy to schedule. Anyone can manually sort both the sessions and rooms by size (expected and actual) and assign the largest room to the session where the most people are expected to attend. 3 sessions and 3 rooms has only 6 possible answers, a very small solution space. If, on the other hand, our conference has 450 sessions spread out over 30 rooms and 15 timeslots, the number of possibilities grows astronomically. There are 450! (450 factorial) possible combinations of sessions, rooms and timeslots in that solution space, far too many for a person to evaluate even in a lifetime of trying. In fact, that solution space is so large that a brute-force algorithm that evaluates every possible combination for fitness, may never complete either. We need to depend on combinatorial optimization techniques and good heuristics to manage these types of decisions, which makes problems with a large solution space excellent candidates for Artificial Intelligence solutions.
Data Requirements
The data requirements consist of all of the different data elements needed to make the optimal decision. Decisions that require only a small number of data elements can often be evaluated manually. However, when the number of data elements to be evaluated becomes unwieldy, a problem becomes a good candidate for an Artificial Intelligence. Consider the problem of comparing two hitters from the history of baseball. Was Mark McGwire a better hitter than Mickey Mantle? We might decide to base our decision on one or two key statistics. If so, we might say that McGwire was a better hitter than Mantle because his OPS is slightly better (.982 vs .977). If, however we want to build a model that takes many different variables into account, hopefully maximizing the likelihood of making the best determination, we may try to include many of the hundreds of different statistics that are tracked for baseball players. In this scenario, an automated process has a better chance of making an informed, rational decision.
Problem Space
The problem space defines how general the decision being made can be. The more generalized an AI, the more likely it is to be applicable to any given situation, the more value it is likely to have. Building on our previous example, consider these three problems:
- Is a particular baseball hitter better than another baseball hitter?
- Is a particular baseball player better than another baseball player (hitter or pitcher)?
- Is a particular baseball player a better athlete than a particular soccer player?
It is relatively easy to compare apples to apples. I can compare one hitter to another fairly easily by simply comparing known statistics after adjusting for any inconsistencies (such as what era or league they played in). The closer the comparison and the more statistics they have in common, the more likely I am to be able to build a model that is highly predictive of the optimum answer and thus make the best decisions. Once I start comparing apples to oranges, or even cucumbers, the waters become much more muddied. How do I build a model that can make decisions when I don't have direct ways to compare the options?
AIs today are still limited to fairly small problem spaces, and as such, they are limited in scope and value. Many breakthroughs are being made however that allow us to make more and more generalizable decisions. For example, many of the AI "personal assistants" such as Cortana and Siri use a combination of different AIs depending on the problem. This makes them something of an AI of AIs and expands their capabilities, and thus their value, considerably.
Volume
The volume of a problem describes the way we usually think of scale in software engineering problems. That is, it is the number of times the program is used to reach a decision over a given timeframe. Even a very simple problem with small solution and problem spaces, and very simple data needs, can benefit from automation if the decision has to be made enough times in a rapid succession. Let's use a round-robin load balancer on a farm of 3 servers as an example. Round Robin is a simple heuristic for load balancing that attempts to distribute the load among the servers by deciding to send the traffic to each machine in order. The only data needed for this decision is the knowledge of what machine was selected during the last execution. There are only 3 possible answers and the problem space is very small and well understood. A person could easily make each decision without difficulty as long as the volume remains low. As soon as the number of requests starts increasing however, a person would find themselves quickly overwhelmed. Even when the other factors are small in scale, high-volume decisions make very good candidates for AI solutions.
These 4 factors describing the scale of a problem are important to consider when attempting to determine if an automated Artificial Intelligence solution is a good candidate to be a part of a solution. Once it has been decided that an AI is appropriate for a problem, we can then look at the options for implementing the solution. Machine Learning is one possible candidate for many problems, but certainly not all. Much more on that in future articles.
Do you agree that the value in AI comes not from how the decisions are made, but from the ability to scale those decisions? Did I miss any scale factors that should be considered when determining if an AI solution might be appropriate? Sound off in the Fediverse @bsstahl.
Tags: ai algorithms optimization solution
A.I. That Can Explain "Why"
Posted by bsstahl on 2016-12-15 and Filed Under: development
One of my favorite authors among Software Architects, IBM Fellow Grady Booch, made this reference to AlphaGo, IBM’s program built to play the board game Go, in April of 2016:
"...there are things neural networks can't easily do and likely never will. AlphaGo can't reason about why it made a particular move." – Grady Booch
Grady went on to refer to the concept of “Hybrid A.I.” as a means of developing systems that can make complex decisions requiring the processing of huge datasets, while still being able to explain the rationale behind those decisions.
While not exactly the type of system Grady was describing, it reminded me of a solution I was involved with creating that ultimately became a hybrid of an iterative, imperative system and a combinatorial optimization engine. The resulting solution was able to both determine the optimum solution for a problem with significant data requirements, while still being able to provide information to support the decision, both to prove it was correct, and to help the users learn how to best use it.
The problem looked something like this:
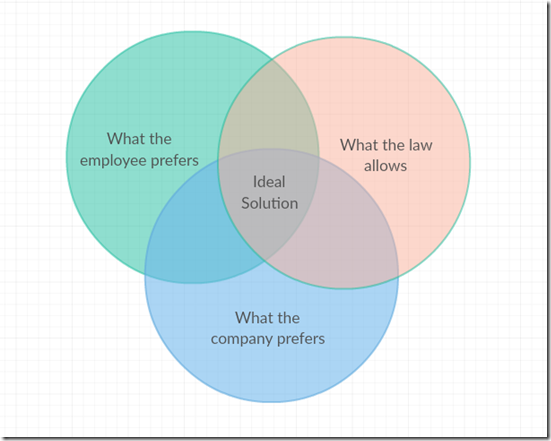
There are many possible ways to allocate work assignments among employees. Some of those allocations would not be legal, perhaps because the employee is not qualified for that assignment, or because of time limits on how much he or she can work. Other options may be legal, but are not ideal. The assignment may be sub-optimal for the employee who may have a schedule conflict or other preference against that particular assignment, or for the company which may not be able to easily fill the assignment with anyone else.
The complexity in this problem comes from the fact that this diagram is different for each employee to be assigned. Each employee has their own set of preferences and legalities, and the preferences of the company are probably different for each employee. It is likely that many employees will not be able to get an assignment that falls into the “Ideal Solution” area of the drawing. If there were just a few employees and a supervisor was making these decisions, that person would have to explain his or her rationale to the employees who did not get the assignments they wanted, or to the bosses if company requirements could not be met. If an optimization solution made the decisions purely on the basis of a mathematical model, we could be guaranteed the best solution based on our criteria, but would have no way to explain how one person got an assignment that another wanted, or why company preferences were ignored in any individual case.
The resulting hybrid approach started by eliminating illegal options, and then looking at the most important detail and assigning the best fit for that detail to the solution set. That is, if the most important feature to the model was the wishes of the most senior employee, that employee’s request would be added to the solution. The optimization engine would then be run to be sure that a feasible solution was still available. As long as an answer could still be found that didn’t violate any of the hard constraints, the selection was fixed in the solution and the next employee’s wishes addressed. If a feasible solution could not be found using the selected option, that selection would be recorded along with the result of the optimization and the state of the model at the time of processing. This allows the reasoning behind each decision to be exposed to the users.
A very simplified diagram of the process is shown below.
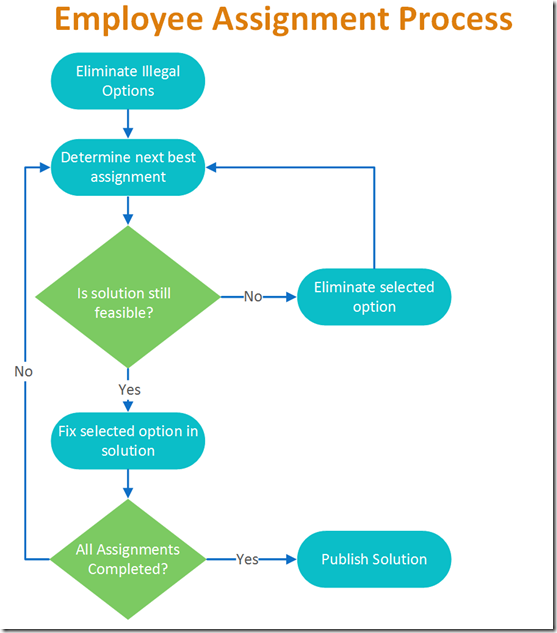
Each time the green diamond testing “Is the solution still feasible?” is hit, the optimization model is run to verify that a solution can be found. It is this hybrid process, the iterative execution of a combinatorial solution engine, that gives this tool its ability to both answer the question of how to do things, while also being able to answer the question of why it needs to be done this way.
Like Grady, I expect we will see many more examples of these types of hybrids in the very near future.
Tags: ai algorithms decision optimization solution
Optimization for Developers
Posted by bsstahl on 2016-10-15 and Filed Under: development
The slide deck for my presentation on Optimization for Developers (A Developer’s Guide to Finding Optimal Solutions) can be found here. I hope that if you attended one of my code camp sessions on the topic, you enjoyed it and found it valuable. I am happy to accept any feedback via @bsstahl.
Tags: ai algorithms development dynamic skill math optimization
A Busy October and November
Posted by bsstahl on 2016-10-05 and Filed Under: event
The next two months are packed with tons of great technical events that I am really looking forward to. Below are some of the events that I am involved with and will be attending between now and the end of November. I hope to run into you at these events. If you see me, please don’t hesitate to say “hi”. I do love to talk tech.
Desert Code Camp – Phoenix AZ – October 8th 2016
Desert Code Camp makes its triumphant return from hiatus this weekend at Chandler-Gilbert Community College in the south-east valley. I will be delivering my talk, “A Developer’s Guide to Finding Optimal Solutions” which is an introduction to combinatorial optimization designed specifically for software developers, at 9:45 am in room CHO-110.
IT/DevConnections – Las Vegas NV– October 10th-13th 2016
One of my favorite large conferences of the year is IT/DevConnections in Las Vegas. This year marks my 4th attendance at this event, the 2nd as a speaker. I will be delivering the talk, “Dynamic Optimization – One Algorithm All Programmers Should Know”, a programmer’s introduction to Dynamic Programming, at 2:15 pm on October 13th in Brislecone 2 at the Aria Resort.
Atlanta Code Camp – Atlanta GA – October 15th 2016
This year marks my 2nd attendance at the Atlanta Code Camp. My 1st experience there, last year when I presented on Dynamic Programming, was a big part of the inspiration for drilling deeper into the topic of combinatorial optimization. As such, I return to Atlanta this year with my new talk on the subject, “A Developer’s Guide to Finding Optimal Solutions”.
NWVDNUG & SEVDNUG – Phoenix AZ – Oct 26th and 27th
It is not yet confirmed as of this publication but I have a really great, internationally renown speaker lined-up for the Northwest Valley and Southeast Valley .NET User Groups this month. Final arrangements are currently being made so keep an eye on meetup.com for each group for the details to be published as soon as they are finalized.
SoCalCodeCamp – Los Angeles CA, November 12th – 13th 2016
I have attended many instances of the Southern California Code camp, but this will only be my 2nd time at the Los Angeles incarnation of this event. My 1st time there, last year, I was struck by the old-school beauty of the old school campus and facilities at USC when I presented my talk on Dynamic Programming. This year, I will follow that up with my new, more general overview on the subject of finding optimal solutions.
NWVDNUG & SEVDNUG – Phoenix AZ – Nov 16th and 17th
Our good friend Jeremy Clark (blog, twitter) makes his annual tour of the Valley’s .NET User Groups to talk to us, once again, about many of the things you need to know about .NET and Software Engineering to make your development better. Jeremy will give a different talk each night so be sure to sign-up at the meetup sites and come to both meetings.
Tags: community conference optimization phoenix professional development schedule
A Software Developer's View of Dynamic Programming
Posted by bsstahl on 2016-07-01 and Filed Under: development
Dynamic Programming (DP) is a mathematical tool that can be used to efficiently solve certain types of problems and is a must-have in any software developer's toolbox. A lot has been written about this process from a mathematician's perspective but there are very few resources out there to help software developers who want to implement this technique in code. In this article and the companion conference talk "Dynamic Optimization - One Algorithm All Programmers Should Know", I attempt to demystify this simple tool so that developer's can implement it for their customers.
What is Combinatorial Optimization?
Mathematical or Combinatorial Optimization is the process of finding the best available solution to a problem by minimizing or eliminating undesirable factors and maximizing desirable ones. For example, we might want to find the best path through a graph that represents the roads and intersections of our city. In this case, we might want to minimize the distance travelled, or the estimated amount of time it will take to travel that distance. Other examples of optimization problems include determining the best utilization of a machine or device, optimal assignment of scarce resources, and a spell-checker determining the most likely word being misspelled.
We want to make sure that we do not conflate combinatorial optimization with code optimization. It is certainly important to have efficient code when running an optimization algorithm, however there are very different techniques for optimizing code than for optimizing the solution to a problem. Code optimization has to do with the efficiency of the implementation whereas combinatorial optimization deals with the efficiency of the algorithm itself. Efficiency in both areas will be critical for solving problems in large domains.
What is Dynamic Programming?
Ultimately, DP is just a process, a methodology for solving optimization problems that can be defined recursively 1. It is really about a way of attacking a problem that, if it were addressed naïvely, might not produce the best possible answer, or might not even converge to a solution in an acceptable amount of time. Dynamic Programming provides a logical approach to these types of problems through a 2-step process that has the effect of breaking the problem into smaller sub-problems and solving each sub-problem only once, caching the results for later use 2.
The steps in the process are as follows:
- Fill out the cache by determining the value of each sub-problem, building each answer based on the value of the previous answers
- Use the values in the cache to answer questions about the problem
Since we fill-out the entire cache for each problem 3, we can be 100% certain that we know what the best possible answers to the questions are because we have explored all possibilities.
Dynamic Programming in Action
Let's look at one of the canonical types of problems that can be solved using Dynamic Programming, the knapsack problem. A knapsack problem occurs in any situation where you have a limited capacity that can be consumed by a number of different possible options. We need to look for the best fit and optimize for the maximum based on the definition of value in our problem. This class of problem gets its name from the story of the archeologist in the collapsing ruin. She has a knapsack that can hold a known weight without tearing and she needs to use it to rescue artifacts from the ruin before it collapses entirely. She wants to maximize the value of artifacts she can save, without exceeding the capacity of her knapsack, because it would then tear and she wouldn't be able to carry anything.
We can solve this type of problem using Dynamic Programming by filling-out a table that holds possible capacities, from 0 to the capacity of our known knapsack, and each of the possible items to use to fill that space, as shown below.
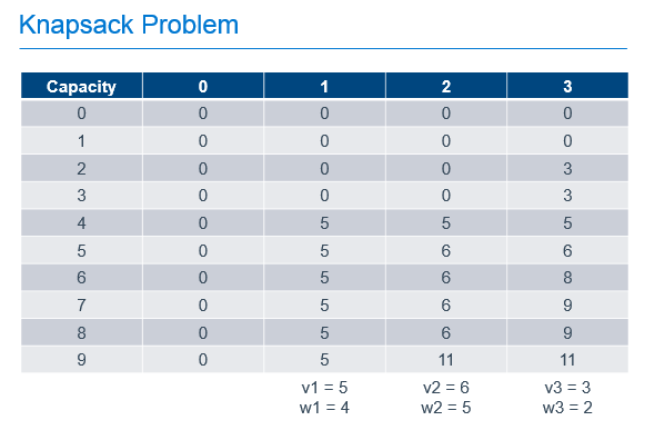
In this example, there are 3 items with weights of 4, 5 and 2. These items have values of 5, 6 and 3 respectively and can be placed in a knapsack with capacity of 9. The leftmost column of the table represents the capacities of knapsacks from 0, up to and including the capacity of our knapsack. The next column represents the best value we would get in the knapsack if we had the option of putting 0 items in our knapsack. The next, the best value if we had the option of taking the 1st item, the next column, the option to take the 2nd item on top of any previous items, and so forth until we complete the table. As you can see, the most value we can get in our knapsack with the option of picking from these 3 items is 11, as found in the last row of the last column. That is, the cell that represents a knapsack with our known capacity, with the option to chose from all of the items.
To calculate each of these cells, we build on the values calculated earlier in the process. For the 1st column, it is easy. If we can chose no items, the value of the items in our knapsack is always 0. The rest of the cells are calculated by determining the greater of the following 2 values:
- The value if we didn't take the current item, which is always the value of the same capacity knapsack from the previous column
- The value if we took the current item, which is the value of the current item, added to the value of the knapsack from the previous column if the weight of the current item were removed
So, for the cell in the column labeled "1" with a knapsack capacity of 6, we take the greater of:
- 0, since we wouldn't have any items in the knapsack if we chose not to take the item
- 5, the value of the current item, added to the value of the other items in the knapsack, which was previously empty
For the cell in column "2" with a knapsack capacity of 9, we take the greater of:
- 5, which is the value of the knapsack with capacity 9 from column "1" indicating that we didn't take the 2nd item
- 11, which is the value of the current item added to the best value of the knapsack with capacity 4 (subtract the weight of our current item from the capacity of the current knapsack) with the option of taking only the previous items.
Each cell in the table can be filled out by doing these simple calculations, 1 addition and 1 comparison, using the values previously calculated as shown in the annotated table below.
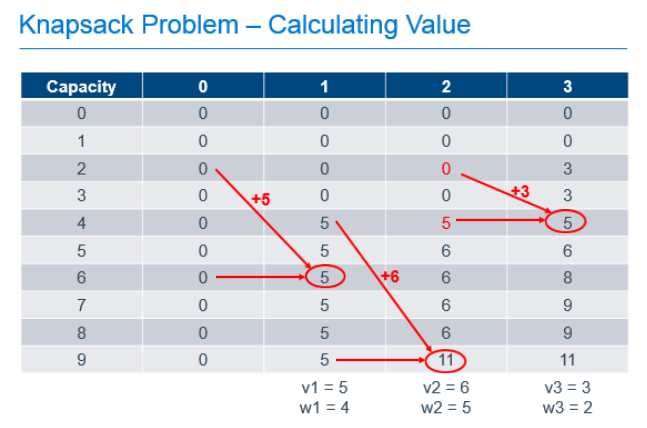
So we've filled out the table and know, from the cell in the bottom right that the maximum value we can get from this knapsack with these items is 11. Great, but that only answers the question of maximum value, it doesn't tell us which items are chosen to achieve this value. To determine that, we need to work backward from the known best value.
Starting at the known best value in the bottom-right cell, we can look one cell to the left to see that the value there is the same. Since we know that taking an item would increase the value of the knapsack, we can know that we must not have chosen to take the item in the last column. We can then repeat the process from there. From the bottom cell in the column labeled "2", we can look left and see that the value in the previous column did change, so we know we need to take the item in column "2" to get our maximum value. Since we know that item 2 had a weight of 5, we can subtract that from the capacity of our knapsack, and continue the process from that point, knowing that we now only have 4 more units of capacity to work with. Comparing the item in the column labeled "1" and a knapsack capacity of 4 with the value of the equivalent knapsack in column "0", we can see that we need to include item 1 in our knapsack to get the optimum result.
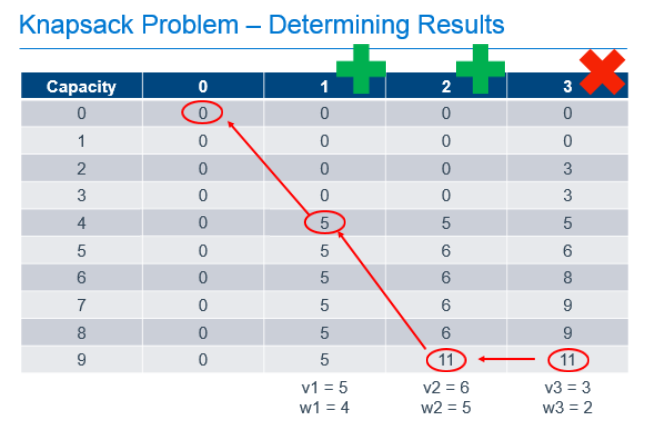
What did we actually do here?
There is no magic here. All we did was take a problem that we could describe in a recursive way, and implement a process that used easy calculations that built upon the results of previous calculations, to fill-out a data cache that allowed us to answer the two primary questions of this problem:
- What is the maximum value of the knapsack with capacity 9 and the option to take the 3 previously described items up to the capacity of the knapsack?
- Which items of the 3 do we need to take to achieve the maximum value described in question
You can probably see that if both axes of this table, the capacity of the knapsack, and the number of items we can chose from, are extremely large, we may run into memory or processing-time constraints when implementing this solutions. As a result, this may not be the best methodology for solving problems where both the capacity of the knapsack and the number of items is extremely high. However, if either is a reasonable number, Dynamic Programming can produce a result that is guaranteed to be the optimum solution, in a reasonable amount of time.
Continue the Conversation
I am happy to answer questions or discuss this further. Ping me @bsstahl with your comments or questions. I'd love to hear from you. I am also available to deliver a talk to your conference or user group on this or other topics. You can contact me here.
Footnotes
In mathematical terms, DP is useful for solving problems that exhibit the characteristics of Overlapping Subproblems and Optimal Substructure. If a problem is able to be described recursively, it will usually exhibit these traits, but the use of the recursion concept here is a generalization to put the problem in software developer's terms.
The process of storing a value for later use is known in mathematics as memoization, an operation which, for all intents and purposes, is equivalent to caching.
Variants of certain DP algorithms exist where the process can be cut-off under certain conditions prior to fully populating the cache. These variants are not discussed here.
