Tag: ml
What Counts as AI‑Generated?
Posted by bsstahl on 2026-03-28 and Filed Under: tools
I still have the first camera I ever used - a 126 box camera, similar to a Hawekeye II, that was basically a toy even in its own era. I shot with black‑and‑white film because that's what a kid could afford, and it produced the kind of photos you'd expect from a plastic lens and a shutter that felt like it was powered by hope. One of those photos captured Thurman Munson, the Yankees catcher who would later die in a plane crash, making him something of a larger-than-life figure in my experience. It's not a great photo. It's grainy, off‑center, and full of the accidental foreground clutter you get when you're small, excited, and holding a camera that doesn't care about your artistic intent.
Recently, I ended up with three versions of that same moment:
- The original - a scan of the actual frame I shot as a kid.
- A cleaned‑up version - run through an AI tool that removed some shadows, centered Munson, and erased the stray arms of the people next to me.
- A colorized version - also AI‑assisted, adding color to a scene that never existed in color on film.
All three images are real in the sense that they correspond to something that actually happened, and all three are altered in the sense that every photograph is shaped by the tools available at the time. When I show any version of these images, I could be asked, Is it "AI‑generated"?

Unfortunately, that question really can't be answered without a lot more context. All 3 images used AI as part of the pipeline in some form or another, because depending on how you define AI, even the act of scanning the original likely used a model. The question we really need to answer is: what do we mean when we say something is "AI‑generated"?
The cleaned‑up version of this photo didn't invent anything. It didn't fabricate Munson's face or change the moment. It just did what darkroom techniques, Photoshop, and restoration tools have always done. The colorized version added something new, but colorization has existed for more than a century. The only difference is that a machine did the brushwork instead of a human. What about the original? It's still the moment I captured as a kid with a box camera. The digital version may have passed through modern software on its way to the screen, but the instant in time remains intact.
Even "true" photos can mislead, with or without AI
This is where things get tricky. Any still or moving image can create false impressions with the viewer. Strange lighting, unusual shadows, a frozen instant in time that doesn't really capture the essence of the situation. All of these things happen, and we've experienced them. How many times have you taken a photo of someone who was happy, but looked sad or angry in the shot? Was the dress blue or gold?
In my three images above, the event happened nearly entirely as presented in those photos. Despite that, any of these versions can still create false impressions in the mind of the viewer.
For example:
- It is possible that Munson is talking to someone, or perhaps yelling at them in a way not captured by this frame.
- When I took the picture, there may have been one or more other people just outside the frame, changing the context.
- The cleaned‑up version might imply the scene was less crowded than it really was, because the tool removed the arms of the people next to me.
- The colorized version might imply the grass at Yankee Stadium looked a certain way that day, when the original didn't capture that detail.
- The colorization might suggest Munson wore an undershirt of a particular shade, a detail the model had to invent.
None of these facts are necessarily germane to the image, but they absolutely can alter its interpretation. Still images can present scenes in a framing that doesn't completely do it justice, while AI can introduce confident, plausible details that were never in evidence, whether done maliciously or not.
This is why labeling matters. Not because AI involvement is inherently bad, but because, in most cases, viewers deserve to know which parts of an image are grounded in reality and which parts were reconstructed, inferred, or imagined. However, defining those rules is an area where a poor definition could let some people get away with anything while the rest of us end up having to tag everything as AI generated, turning the label into just more noise.
This isn't even touching the copyright issues
Everything above is about truth: what happened, what didn't, and what an image implies, but there's a whole separate dimension we haven't entered: copyright.
Questions like:
- What training data was used to create the model?
- Who owns the derivative works?
- When does enhancement become transformation?
- What rights do I retain over my own childhood photo once an AI model has touched it?
These aren't footnotes. They're large, unresolved questions that deserve their own analysis and probably their own regulatory framework. Mixing them into the "AI‑generated vs. not" debate only makes everything muddier. So for this post, I'm deliberately setting copyright aside; not because it's unimportant, but because it's too important to treat as a parenthetical.
The Hard Part Is Defining What Matters
The reasons why blanket rules about "AI‑generated content" fall apart are complicated. The line between "generated," "assisted," "enhanced," and "restored" isn't a line at all, it's a gradient. That doesn't mean we shouldn't regulate AI‑involved media. It means we need to regulate AI with language and intent that actually matches reality, and solves the real problems.
There are cases where labeling is essential, but most of it is context specific. If I am posting a picture of a conference talk I gave, I wouldn't feel right adding fake participants in the crowd, but I'd often be fine with editing someone out who asked me to, depending on the reason for doing so. I might not feel the same way if the photograph was being published as part of a story in the news. However, there are some things that should probably always be disclosed:
- Images of things that never happened should be labeled as such.
- Images containing people that don't exist must be disclosed.
- Images where people or evidence is added absolutely require clear disclosure, even if they are believed to be 'real'.
- AI‑assisted reconstructions, such as those built from text descriptions after the fact, should be labeled in way that allows viewers understand what's real and what's assumed.
Those distinctions matter because they speak to truth, provenance, and the potential for harm, and they remain just as important whether AI is part of the process or not.
But my three images of Thurman Munson? They're all the same moment, they differ only in the tools used to reveal it. In most contexts, there is no meaningful change made by these manipulations.
There are already existing sets of rules we can lean on here. The National Press Photographers Association has a Code of Ethics for visual journalists that includes the following:
Editing should maintain the integrity of the photographic image's content and context. Do not manipulate images or add or alter sound in any way that can mislead viewers or misrepresent subjects.
I would ask you, "Does my manipulation of this image mislead viewers or misrepresent subjects?"
This Code of Ethics also includes composition and subject matter rules such as:
- Resist being manipulated by staged photo opportunities
- Be complete and provide context when photographing or recording subjects
- While photographing subjects, do not intentionally contribute to, alter, or seek to alter or influence events
- Do not pay sources or subjects or reward them materially for information or participation
- Do not accept gifts, favors, or compensation from those who might seek to influence coverage
All of which suggests that the editing of images, the part that can be done using AI, is just a small part of the harm that can be done through visual means, albeit one that scales better than most.
Here's the part we can't ignore
AI, in some form, is nearly always involved now. Not the headline‑grabbing generative models that synthesize faces or fabricate events, but the quiet, invisible systems inside scanners, cameras, phones, and photo apps, the ones nobody notices because they don't feel like AI. Processes like sharpening, noise reduction, auto‑contrast, white‑balance correction, lens‑distortion fixes and de‑mosaicing filters are all part of many of the image capture mechanisms we use every day. Other domains have similar tools used for autocorrect, predictive-text, grammar correction, spellcheck, voice-to-text, spam filtering and recommendations. These are all machine‑learning (ML) systems doing work behind the scenes.
So the question can't be "Was AI used?" The questions must be more akin to "What kind of AI was used, how was it used, and to what effect?". These questions need to be answered in the full context of the situation, because the truth of this photo is simple, AI didn't create it, it actually happened. The tools just helped me see it more clearly, but they can also help someone else see something that was never there. Outside of this one childhood snapshot, it's rarely even that simple.
Knowing the difficulty in categorizing these three versions of a childhood photo as 'AI-generated' or not, it is obvious that we can't build policy around such a binary definition. We need rules that focus on intent, impact, and what claims are being made, not on whether a model was somewhere in the toolchain. We will drill into more detail on how we can craft regulations that take these items into account in future posts.
Tags: ai ethics legislation ml opinion
Simple Linear Regression
Posted by bsstahl on 2023-02-13 and Filed Under: development
My high-school chemistry teacher, Mrs. J, had a name for that moment when she could see the lightbulb go on over your head. You know, that instant where realization hits and a concept sinks-in and becomes part of your consciousness. The moment that you truly "Grok" a principle. She called that an "aha experience".
One of my favorite "aha experiences" from my many years as a Software Engineer, is when I realized that the simplest neural network, a model with one input and one output, was simply modeling a line, and that training such a model, was just performing a linear regression. Mind. Blown.
In case you haven't had this particular epiphany yet, allow me to go into some detail. I also discuss this in my conference talk, A Developer's Introduction to Artificial Intelligences.
Use Case: Predict the Location of a Train
Let's use the example of predicting the location of a train. Because they are on rails, trains move in 1-dimensional space. We can get a good approximation of their movement, especially between stops, by assuming they travel at a consistent speed. As a result, we can make a reasonably accurate prediction of a train's distance from a particular point on the rail, using a linear equation.
If we have sensors reporting the location and time of detection of our train, spread-out across our fictional rail system, we might be able to build a graph of these reports that looks something like this:
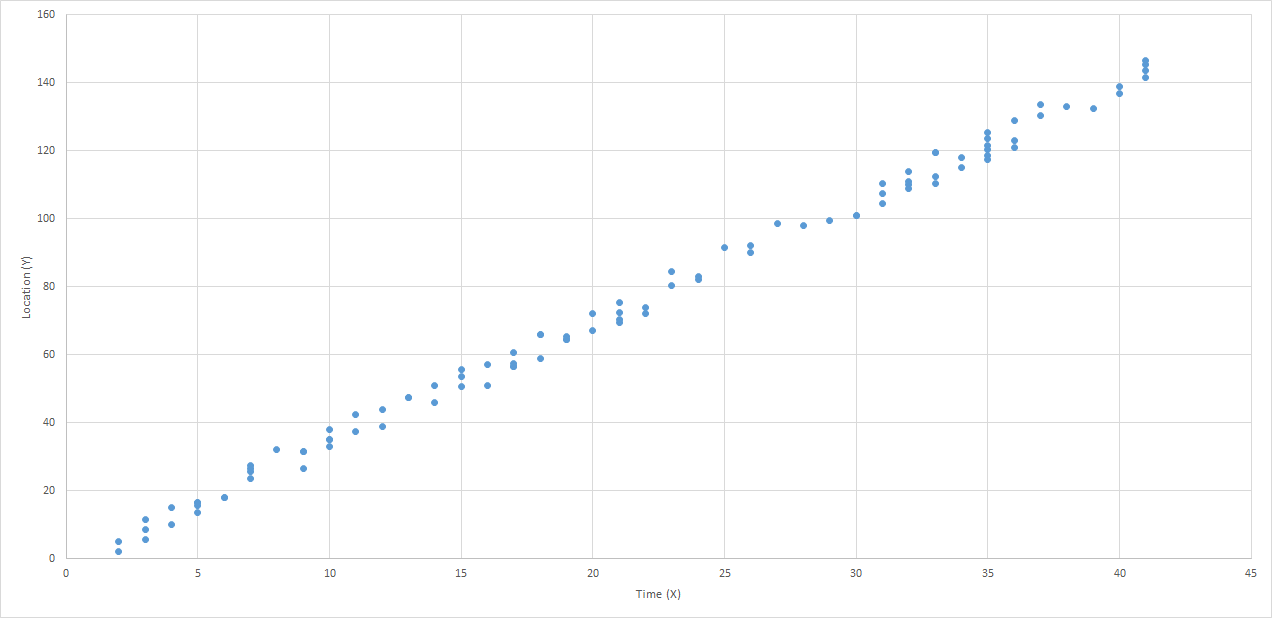
I think it is clear that this data can be represented using a "best-fit line". Certainly there is some error in the model, perhaps due to sensor or reporting errors, or maybe just to normal variance of the data. However, there can be no doubt that the best fit for this data would be represented as a line. In fact, there are a number of tools that can make it very easy to generate such a line. But what does that line really represent? To be a "best-fit", the line needs to be drawn in such a way as to minimize the differences between the values found in the data and the values on the line. Thus, the total error between the values predicted by our best-fit line, and the actual values that we measured, is as small as we can possibly get it.
A Linear Neural Network
A simple neural network, one without any hidden layers, consists of one or more input nodes, connected with edges to one or more output nodes. Each of the edges has a weight and each output node has a bias. The values of the output nodes are calculated by summing the product of each input connected to it, along with its corresponding weight, and adding in the output node's bias. Let's see what our railroad model might look like using a simple neural network.
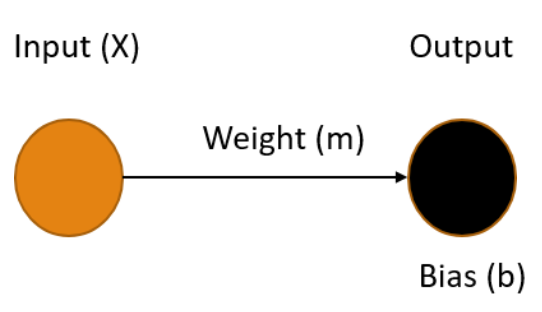
Ours is the simplest possible neural network, one input connected to one output, where our X value (time) is the input and the output Y is our prediction of the distance the train has traveled in that time. To make the best prediction we need to determine the values for the weight of the edge m and the bias of the output node b that produce the output that minimizes the errors in the model.
The process of finding the weights and biases values for a neural network that minimize the error is know as Training the model. Once these values are determined, we use the fact that we multiply the weight by the input (m * X) and add in the bias. This gives us an equation in the form:
Y = mX + b
You may recognize this as the slope-intercept form of the equation for a line, where the slope m represents the speed of the train, and the bias b represents the starting distance from the origin. Once our training process gives us values for m and b, we can easily plug-in any value for X and get a prediction for the location of our train.
Training a Model
Training an AI model is simply finding the set of parameters that minimize the difference between the predicted output and the actual output. This is key to understanding AI - it's all about minimizing the error. Error minimization is the exact same goal as we have when performing a linear regression, which makes sense since these regressions are predictive models on their own, they just aren't generally depicted as neural networks.
There are many ways to perform the error-minimization process. Many more complicated models are trained using an iterative optimization routine called Gradient Descent. Extremely simple models like this one often use a less complicated process such as Ordinary Least Squares. The goals are the same however, values for weights and biases in the model are found that minimize the error in the output, resulting in a model can make the desired predictions based on known inputs.
Regardless of the method used, the realization that training the simplest neural network results in a model of a line provided the "aha experience" I needed as the foundation for my understanding of Machine Learning models. I hope, by publishing this article, that others may also benefit from this recognition.
Tags: ai algorithms ml optimization presentation
Troubleshooting Information for Machinelearning-ModelBuilder Issue #1027
Posted by bsstahl on 2021-04-03 and Filed Under: tools
Update: The issue has been resolved. There was an old version of the Extension installed on failing systems that was causing problems with Visual Studio Extensions. Even though the version of the Extension showed as the correct one, an old version was being used. A reinstall of Visual Studio was needed to fix the problem.
There appears to be a problem with the Preview version of the ModelBuilder tool for Visual Studio. This issue has been logged on GitHub and I am documenting my findings here in the hope that they will provide some insight into the problem. I will update this post when a solution or workaround is found.
I want to be clear that this problem is in a preview version, where problems like this are expected. I don't want the team working on this tooling to think that I am being reproachful of their work in any way. In fact, I want to compliment them and thank them for what is generally an extremely valuable tool.
To reproduce this problem, use this Data File to train an Issue Classification or Text Classification model in the ModelBuilder tool by using the Key column to predict the Value column. The keys have intelligence built into them that are valid predictors of the Value (I didn't design this stuff).
Machines that are unable to complete this task get a error stating Specified label column 'Value' was not found. with a stack trace similar to this.
This process seems to work fine on some machines and not on others. I have a machine that it works on, and one that it fails on, so I will attempt to document the differences here.
The first thing I noticed is that the experience within the tool is VERY DIFFERENT even though it is using the exact same version of the Model Builder.
From the machine that is able to train the model

From the machine having the failure

Everything seems to be different. The headline text, the options that can be chosen, and the graphics (or lack thereof). My first reaction when I saw this was to double-check that both machines are actually using the same version of the Model Builder tool.
Verifying the Version of the Tool
Spoiler alert: To the best I am able to verify, both machines are using the same version of the tool.
From the machine that is able to train the model

From the machine having the failure

My next thought is that I'm not looking at the right thing. Perhaps, ML.NET Model Builder (Preview) is not the correct Extension, or maybe the UI for this Extension is loaded separately from the Extension. I can't be sure, but I can't find anything that suggests this is really the case. Perhaps the dev team can give me some insight here.
Verifying the Region Settings of the Machine
While these versions are clearly the same, it is obvious from the graphics that the machines have different default date formats. Even though there are no dates in this data file, and both machines were using US English, I changed the Region settings of the problem machine to match that of the functional machine. Predictably, this didn't solve the problem.
From the machine that is able to train the model

From the machine having the failure - Original Settings

From the machine having the failure - Updated Settings

Checking the Versions of Visual Studio
The biggest difference between the two machines that I can think of, now that the region settings match, is the exact version & configuration of Visual Studio. Both machines have Visual Studio Enterprise 2019 Preview versions, but the working machine has version 16.9.0 Preview 1.0 while the failing machine uses version 16.10.0 Preview 1.0. You'll have to forgive me for not wanting to "upgrade" my working machine to the latest preview of Visual Studio, just in case that actually is the problem, though I suspect that is not the issue.
From the machine that is able to train the model

From the machine having the failure

There are also differences in the installed payloads within Visual Studio between the 2 machines. Files containing information about the installations on each of the machines can be found below. These are the files produced when you click the Copy Info button from the Visual Studio About dialog.
From the machine that is able to train the model
Visual Studio Payloads - Functional Machine
From the machine having the failure
Visual Studio Payloads - Problem Machine
Windows Version
Another set of differences involve the machines themselves and the versions of Windows they are running. Both machines are running Windows 10, but the working machine runs a Pro sku, while the problem machine uses an Enterprise sku. Additionally, the machines have different specs, though they are consistent in that they are both underpowered for what I do. I'm going to have to remedy that.
I've included some of the key information about the machines and their OS installations in the files below. None of it seems particularly probative to me.
From the machine that is able to train the model
System and OS - Functional Machine
From the machine having the failure
System and OS - Problem Machine
Other Things to Check
There are probably quite a number of additional differences I could look at between the 2 machines. Do you have any ideas about what else I could check to give the dev team the tools they need to solve this problem?
