Tag: caching
You Got Your Policy in my Redis
Posted by bsstahl on 2021-04-22 and Filed Under: development
Using a distributed cache such as Redis is a proven method of improving the performance and reliability of our applications. As with any tool, use in accordance with best practices will help to reduce support time and outages, and give our customers the best possible experience.
As much as we’d like to believe that our cloud services are highly available and reliable, the fact is that no matter how much effort goes into their resilience, we will never get 100% availability from them. Even if it is just due to random Internet routing issues, we must take measures to protect our applications, our customers, and our support personnel, from these inevitable hiccups. There are a number of patterns we can use to make our cache access more resilient, and therefore less susceptible to these outages. There are also libraries we can use to implement these patterns, allowing us to declare policies for these patterns, and implement and compose them with ease.
These concepts are useful in all tool chains, with or without a policy library, and policy libraries are available for many common development languages. However, this article will focus on using the Polly library in C# for implementation. That said, I will attempt to describe the concepts, as much as possible, in terms that are accessible to developers using all tool chains. I have also used the Polly library generically. That is, any calls that result in data being returned could be used in place of the caching operations described here. In addition, for clients that use Microsoft’s IDisributedCache abstraction, there is a caching specific package, Polly.Caching.Distributed, that does all of these same things, but with a simplified syntax for caching operations.
Basic Cache-Retrieval
The most straightforward use-case for a caching client is to have the cache pre-populated by some other means so that the client only has to retrieve required values. In this situation, either the value is successfully retrieved from the cache, or some error condition occurs (perhaps a null returned or an Exception thrown). This usage, as described, is very simple, but can still provide a lot of value for our applications. Having low-latency access to data across multiple instances of our application can certainly improve the performance of our apps, but can also improve their reliability, depending on the original data source. We can even use the cache as a means for our services to own-their-own-data, assuming we take any long-term persistence needs into account.
It goes without saying however that this simple implementation doesn’t handle every circumstance on its own. Many situations exist where the data cannot all be stored in the cache. Even if the cache can be fully populated, there are circumstances, depending on the configuration, where values may need to be evicted. This pattern also requires each client to handle cache errors and misses on their own, and provides no short-circuiting of the cache during outage periods. In many cases, these types of situations are handled, often very differently, by the consuming clients. Fortunately, tools exist for many languages that allow us to avoid repeating the code to manage these situations by defining policies to handle them.
Using a Circuit-Breaker Policy
It is an unfortunate fact of distributed system development that our dependencies will be unavailable at times. Regardless of how reliable our networks and cloud dependencies are, we have to act like they will be unavailable, because sometimes they will be. One of the ways we have to protect our applications from these kinds of failures is to use a circuit-breaker.
A circuit-breaker allows us to specify conditions where the cache is not accessed by our client, but instead the cache-call fails immediately. This may seem counterintuitive, but in circumstances where we are likely in the middle of an outage, skipping the call to the cache allows us to fail quickly. This quick-failure protects the users from long timeout waits, and reduces the number of network calls in-process. Keeping the number of network calls low reduces the risk of having our pods recycled due to port-exhaustion problems, and allows our systems to recover from these outages gracefully.
To use a Polly circuit-breaker in C#, we first define the policy, then execute our request against the policy. For example, a sample policy to open the circuit-breaker under the configured conditions and log the change of state is shown below.

This code uses the static logger to log the state changes and has members (_circuitBreakerFailureThresholdPercentage, _circuitBreakerSamplingDuration, etc...) for the configuration values that specify the failure conditions. For example, we could configure this policy to open when 50% of our requests fail during a 15 second interval where we handle at least 20 requests. We could then specify to keep the circuit open for 1 minute before allowing traffic through again. A failure, in this policy, is defined at the top of the above expression as:
- When any Exception occurs (.Handle
() ) or - When a default result is returned such as a null (.OrResult(default(T)))
Once our policy is available, we can simply execute our cache requests in the context of that policy. So, if we call our cache on a dependency held in a _cacheClient member, it might look like the samples below with and without using a policy.
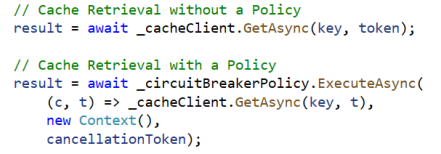
To use the policy, we call the same method as we would call without the policy, but do so within the ExecuteAsync method of the policy object. You might notice there is a Context object passed in to the policy. This allows information to be passed-around to the different sections of the policy. We will be using this later.
...the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
Executing our cache requests within the context of this policy allows the policy to keep track of the results of our requests and trigger the policy if the specified conditions are met. When this policy is triggered, the state of the circuit is automatically set to open and no requests are allowed to be serviced until the circuit is closed again. When either of these state transitions occur (Closed=>Open or Open=>Closed) the appropriate lambda is executed in the policy. Only logging is being done in this example, but the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
We can now protect our applications against outages. However, this does nothing to handle the situation where the data is not available in our cache. For this, we need a Failover (Fallback) policy.
Using a Failover Policy to Fall-Back to the System of Record
Many use-cases for caching involve holding frequently or recently retrieved values in the cache to avoid round-trips to a relational or other data source. This pattern speeds access to these data items while still allowing the system to gather and cache the information if it isn’t already in the cache.
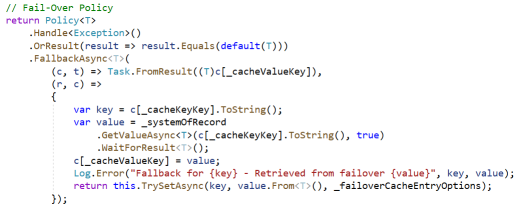
Many policy libraries have methods to handle this pattern as well. A Polly policy describing this pattern is shown below.
And to access the cache using this policy, we might use code like this.
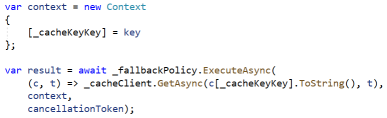
You’ll notice that the code to update the cache is specified in the policy itself (the 2nd Lambda). Like the circuit-breaker, this policy responds when any Exception is thrown or a default value (i.e. null) is returned. Unlike the circuit-breaker however, this policy executes its code every time there is a miss or error, not just when thresholds have been exceeded. You’ll also notice that, in the calling code, a Context object is defined and the cache key value is added to that property bag. This is used in the handling mechanism to access the value from the System of Record and to update the cache with that value. Once the value has been updated in the cache, it is returned to the caller by being pulled back out of the property bag by the 1st Lambda expression in the policy.
We’ll need to be careful here that we set the _failoverCacheEntryOptions appropriately for our use-case. If we allow our values to live too long in the cache without expiring, we can miss changes, or cause other values to be ejected from the cache. As always, be thoughtful with how long to cache the values in your use-case. We also do nothing here to handle errors occurring in the fallback system. You’ll want to manage those failures appropriately as well.
We can now declare a policy to fail-over to the system of record if that is appropriate for our use-case, but this policy doesn’t do anything to protect our systems from outages like our circuit-breaker example does. This is where our policy libraries can really shine, in their ability to combine policies.
Wrapping It Up - Combining Multiple Policies using Policy Wrappers
One of the real advantages of using a policy library like Polly is the ability to chain policies together to form complex reliability logic. Before going too deep into how we can use this to protect our cache-based applications, let’s look at the code to combine the two policies defined above, the Circuit-Breaker and Fallback policies. The code inside the CreateFallbackPolicy and CreateCircuitBreakerPolicy methods are just the return statements shown above that create each policy.
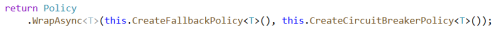
These policies are executed in the order specified, which means that the last one specified is the one closest to the cache itself. This is important because, if our circuit is open, we want the Fallback policy to handle the request and fail-over to the system of record. If we were to reverse this order, opening the circuit would mean that the Fallback policy is never executed because the Circuit Breaker policy would block it.
This combined policy, as shown above, does everything we need from a cache client for our most common use-cases.
- Returns the value from the cache on cache-hit
- Returns the value from the backup system (system of record) on cache-miss
- Populates the cache with values retrieved from the backup system on cache-miss
- Opens the circuit for the specified time if our failure thresholds are reached, indicating an outage
- Gives us the opportunity to perform other recovery logic, such as resetting the Multiplexer, when the circuit is opened
- Closes the circuit again after the specified timeframe
- Gives us the opportunity to to perform other logic as needed when the circuit is closed
In many cases our applications have implemented some or all of this logic themselves, whether it is in custom clients or abstractions like Queries or Repositories. If these applications are working well, and adequately protecting our systems and our customers from the inevitable failures experienced by distributed systems, there is certainly no need to change them. However, for systems that are experiencing problems when outages occur, or those being built today, I highly recommend considering using a policy library such as Polly to implement these reliability measures.
Tags: development reliability caching pattern
Enterprise Library Overview
Posted by bsstahl on 2006-05-08 and Filed Under: event development
In this excellent session, Rob Bagby gave a warp-1 overview of much of the .NET Enterprise Library (Application Blocks). Some key points of the talk were:
- Config files for all blocks are now unified
- Crypto block provides Hashing & Encryption functionality
- Logging block provides a number of canned sinks including EventLog, DB, Text, MSMQ, Email and WMI
- A good resource on the Caching block is at http://www.ronjacobs.com
Of course, there were many other interesting items which I am unable to document here due to my mild case of brain disfunctionality, but again, I will post links to the slide-decks as I get them.
