Tag: code analysis
Code Coverage Teaches and Protects
Posted by bsstahl on 2016-10-14 and Filed Under: development
I often hail code coverage as a great tool to help improve your code base. Today, my use of Code Coverage taught me something about the new .NET Core tooling, and helped protect me from having to support useless code for the lifespan of my project.
In the code below, I used a common dependency injection pattern. That is, an IServiceProvider object holding my dependencies is passed-in to my object and stored as a member variable. When a dependency is needed, I retrieve that dependency from the service provider, and then take action on it. Since there is no guarantee that the dependency I need will have been placed in the container, I use some common guard logic to protect my code.
templates = _serviceProvider.GetService<IEnumerable<Template>>();
if ((templates==null) || (!templates.Any(s => s.TemplateType==ContactPage)))
throw new TemplateNotFoundException(TemplateType.ContactPage, string.Empty);
In this code, I first test that I was able to retrieve a collection of Template objects from the service provider, then verify that the type of Template I need is present in the collection. If either is not the case, an exception is thrown.
I had two tests that covered this section of code, one where the collection was not added to the service provider, the other where an empty collection was added. Both tests passed, however, it wasn't until I looked at the results of the Code Coverage that I realized that the 1st test wasn't doing what I thought it was doing. It turns out that there is actually no way to get a null collection object out of the Microsoft.Extensions.DependencyInjection.ServiceProvider object I am using for my .NET Core apps. That provider simply returns an empty collection if there isn't one in the container. Thus, my check for null was never matched and that branch of code was never executed.
Based on this new knowledge of the behavior of the IServiceProvider, I had a few options. I could:
- Rewrite my test to check for an empty collection. This option seems redundant to me since my check to see if the container holds the template I need is really what I care about.
- Leave the code as-is just in case the behavior of the container changes, accepting that I have what is currently unnecessary and untestable code in my application. I considered this option but it seems to me that a better defense against the unlikely event of a breaking change in the IServiceProvider implementation is described below in option 3.
- Create a new test that verifies the behavior on the ServiceProvider that an empty collection is returned if no collection is supplied to the container. I am not a big fan of this option since it requires me to test OPC (other people's code), and because the risk of this type of breaking change is, in my opinion, extremely low.
- Remove the guard code that tests for null and the test that supports it. Since the code is completely unnecessary, the test itself is redundant because it is, essentially identical to the test verifying that the template I need is in the collection.
I'm sure you've guessed by now that I selected option 4. I removed the guard code and the test from my solution. In doing so, I removed dead code that served no purpose, but would have to be supported through the life of the project.
For those who might be thinking something similar to, "It's nice that the coverage tooling helped you learn about your code, but using Code Coverage as a metric is actually a bad idea so I won't use Code Coverage at all", I'd like to remind you that any tool, such as a hammer or a car, can be abused. That doesn't mean we don't continue to use them, we just make certain that we use them properly. Code Coverage is a horrible way to measure a development team or effort, but it is an outstanding tool and should be used by the development team whenever possible to discover things about the code base.
Tags: abstraction agile assert code analysis code coverage coding-practices csharp ioc testing unit testing dotnet
TDD Helps Validate Your Tests
Posted by bsstahl on 2016-03-05 and Filed Under: development
One of the reasons to use TDD over test-later approaches is that you get a better validation of your tests.
When the first thing you do with a test or series of tests is to run them against code that does nothing but throw a NotImplementedException, you know exactly what to expect. That is, all tests should fail because the code under test threw a NotImplementedException. After that, you can take iterative steps to implement the code. Along the way, you should always see your tests fail in appropriate ways. Eventually, all of your tests should pass when the code is complete.
If tests start passing before they should, continue to fail when they shouldn’t, or fail for reasons that are different than what you’d expect at that point in the development process, you have a good indication that the test may not be doing what you want it to be doing. This additional information about the tests can be very helpful in making sure your unit tests are properly testing your code.
Think about what happens when you add tests after the code has already been written. Suppose you write a test for existing code, and it passes. What do you really know about the test? Is it working because it is adequately exercising your code? Did you forget to do an assert? Is it even testing the proper bit of code? Code coverage tools can help with some of this but they can only help if the code under test is not already touched by other tests. Stepping through the code in debug mode is another possibility, a third option is to comment out the code as if you were starting from scratch, effectively doing a TDD process without any of the other benefits of TDD.
What about when you write a test for previously written code, and the test fails? At this point, there are 2 possibilities:
- The code-under-test is broken
- The test is broken
You now have 2 variables in the equation, the code and the test, when you could have had only 1. To eliminate 1 of the variables, you have to again perform the TDD process without most of its benefits by commenting out the code and starting from ground zero.
Following a good TDD process is the best way to be confident that any test failures indicate problems in the code being tested, instead of the tests themselves.
Tags: code analysis code coverage coding-practices tdd testing unit testing
Conflict of Interest -- YAGNI vs. Standardization
Posted by bsstahl on 2014-07-28 and Filed Under: development
While working on the OSS project mentioned in my previous post, I have run across a dilemma where two of the principles I try to work by are in conflict. The two principles in question are:
- YAGNI - You aint gonna need it, which prescribes not coding anything unless the need already exists. This principle is a core of Test Driven Development of which I am a practitioner and a strong proponent.
- Standardization - Where components, especially those built for use by other developers, are implemented in a common way in order to shorten the learning curve of future developers who will use the component and to reduce implementation bugs.
I have run across this type of decision many times before and have noted the following:
- YAGNI is usually correct, if you don't need it now, you are unlikely to need it in the future.
- Standard implementations which are built incompletely tend to be implemented badly later because there tends to be more time pressure further along into projects, and because it is often implemented by someone other than the original programmer who may not be as familiar with the pattern.
- The fact that there is less time pressure early in projects is another great reason to respect YAGNI because if we are always writing unnecessary code early in projects, a project can quickly become late.
- Implementing code that is not currently required by the use-cases being built requires the addition of unit tests that are specific to the underlying functionality rather than user requested features. While often valuable, the very fact that we are writing such tests is a code smell.
- Since I use FxCop Code Analysis built-in to Visual Studio, not supplying all features of a standard implementation may require overriding one or more analysis rules.
Taking all of this into account, the simplest solution (which is usually the best) is to override the FxCop rules in the code, and continue without implementing the unneeded, albeit standard features.
Do you disagree with my decision? Tell me why @bsstahl.
Tags: yagni standardization coding-practices code analysis tdd unit testing
Demo Code for EF4Ent Sessions
Posted by bsstahl on 2011-06-26 and Filed Under: development
I previously posted the slides for my Building Enterprise Apps using Entity Framework 4 talk here. I can now post the source code for the completed demo application. That code, created for use in Visual Studio 2010 Ultimate, is available in zip format below. This is the same code that was demonstrated at Desert Code Camp 2011.1 and SoCalCodeCamp 2011 as well as the New Mexico .NET User’s Group (NMUG).
Tags: abstraction agile assembly code analysis code camp code contracts code sample coding-practices conference csharp enterprise library entity entity framework fxcop interface testing unit testing visual studio
Code Analysis Rules
Posted by bsstahl on 2011-06-07 and Filed Under: development
FxCop, the built-in code-analysis tool in Visual Studio, is the first thing I check when doing a code review. If Code Analysis is enabled for a project, setup properly, and its rules have not been overridden, this tool will help maintain consistency in the code, even if that code is worked on by multiple developers. FxCop also does a good job of identifying if some common mistakes have been made, such as not disposing of an IDisposable object, and can identify things that will help the compiler do its job better, such as ensuring that assemblies which expose public objects identify whether or not they are intended to be CLS compliant.
In order to get these benefits, code analysis must be enabled for each project and a rule set must be selected. Because adding code-analysis to existing assemblies can be a bit painful, it is recommended that you enable this analysis as soon as a project is created in Visual Studio. To enable code analysis for an assembly, select the project properties, go to the Code Analysis tab, and check the “Enable Code Analysis on Build (defines CODE_ANALYSIS constant)” box.
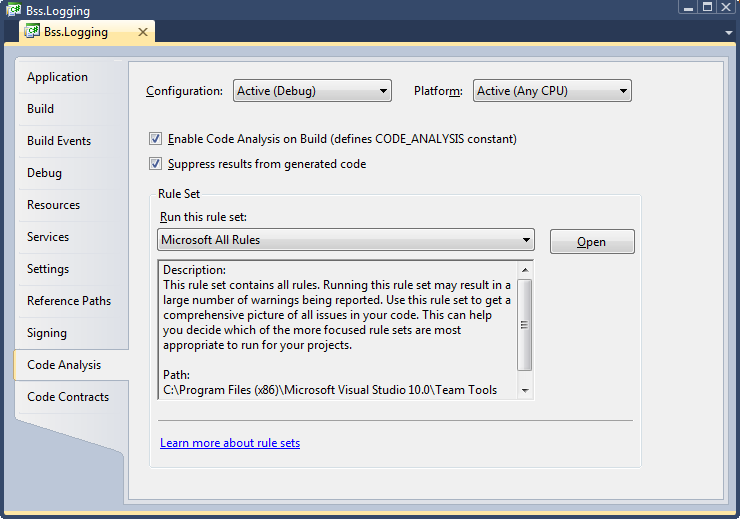
The default rule set that will be run during code analysis is called “Microsoft Minimum Recommended Rules”. This is a very small set of rules that is a good one to enable if you are starting to do code analysis on a previously coded assembly. If however, you are starting clean, I highly recommend starting with either the “Microsoft All Rules” rule set, or your own version of that set, since this rule set will provide the most benefit in all areas of analysis. To create your own rule sets, select the set you wish to modify and press the “Open” button next to the rule set drop-down. Once opened, you can make any changes you wish, and use the File –> Save-as menu item to save the rule set with a different file name. New rule sets will automatically appear in the drop-down menu. You can use the properties tab to update the Name and Description of the set, and the rules editor to enable or disable individual rules. You can also define, for each rule, whether failures are ignored, result in a warning, or generate a compilation error. I highly recommend setting all rules that you want to enforce to cause errors since they can always be overridden if necessary but will likely be missed if they only result in warnings.
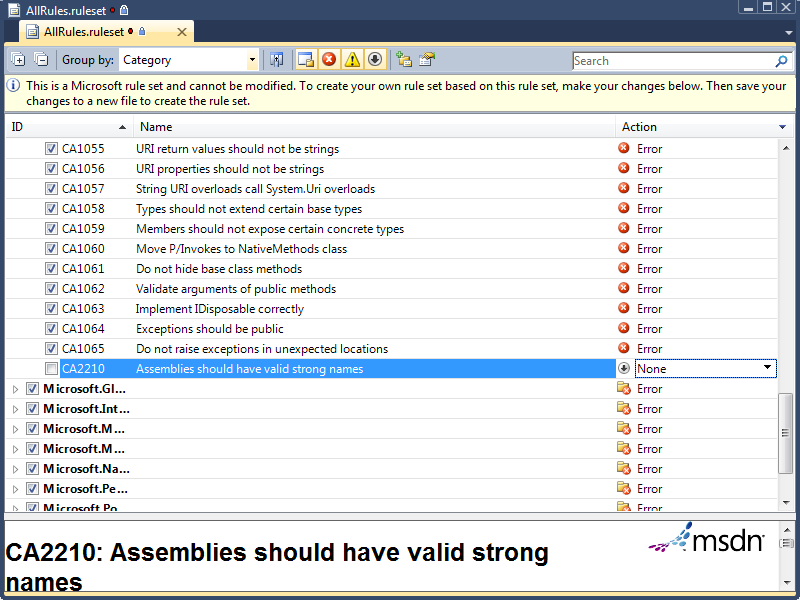
For my projects, I use one of several rule sets that I have set up, all of which are slight modifications to the “Microsoft All Rules” rule set. I will detail the rule set changes I make and overrides that I allow in each set of circumstances below. I encourage you to experiment with these rule sets to determine the optimum configuration for your projects.
All Projects
- Modify the “Microsoft All Rules” rule set so that all rules result in an error. The easiest way to do this is to use the “group by” drop-down to order all rules by “Target Type”. The only type found here should be “Managed Code”. With this single group collapsed, use the Action drop-down to select “Error” for all rules.
Entity Framework Projects
- The Entity Framework requires navigation properties of entities to be read-write, a violation of rule CA2227, “Collection properties should be read only”. For projects utilizing the Entity Framework, as well as those designed for use within the entity framework (such as entity POCO libraries), the action of this rule may be set to “Warning” to prevent compilation errors whenever entities with navigation properties are built.
Projects Deployed to Internal Company Servers (and not GAC’ed)
- Assemblies that will not be deployed to the GAC and will remain on secure, internal servers do not need to have a strong name. Thus, rule CA2210, “Assemblies should have valid strong names”, can be permanently over-ridden or have its action set to “None”.
Non-Localized Projects
- For projects that are never to be localized to a foreign culture, you can set the action for rule CA1303, “Do not pass literals as localized parameters”, back to “Warning”. I find this rule to be especially incorrect when I am writing logging code within my methods (unless using aspect-orientation) because the logging code also serves as functional code-comments if the literals are included in the method calls.
Console Applications
- Many console apps ignore the command-line parameters passed-in to the main method, a violation of rule CA1801, “Review Unused Parameters”. Most of the time, this rule is valuable since you don’t want to have parameters to methods that are never used, however, since we cannot change the parameters to the main method of a console app, but may not wish to use them, this rule can be set to generate a warning in console applications, or can be simply overridden for the parameters to the main method of each console app. This rule may also be violated temporarily when a method has been stubbed but not yet implemented. In that case, the rule should be overridden in code similar to rule CA1822 below.
Other (More Temporary) Modifications
- Rule CA1822, “Mark members as static”, is violated when a method in a class does not use any of the other non-static members of the class. This is always true when the method has not yet been implemented (is only a stub). Prior to the method being implemented, this rule should be overridden in code. The override should be removed from the code once the method has been implemented.
- Rule CA1040, “Avoid empty interfaces” is often violated temporarily in TDD/BDD because interfaces may be created without methods and then be built-up as needed by the use-case. Prior to the interface being defined, this rule should be overridden in code. The override should be removed from the code once the interface has been defined.
I have found using Code Analysis to be a good way to improve the maintainability of my applications, especially when the app is being worked on by multiple members of a project team. The FxCop tool, built into Visual Studio’s Ultimate and Premium editions, is one of a number of tools and techniques I use to keep my code as maintainable and extensible as possible, resulting in the lowest possible total cost of ownership (TCO). In future articles, I will explore additional tools and techniques I use for this purpose.
