Tag: abstraction
Meta-Abstraction -- You Ain't Gonna Need It!
Posted by bsstahl on 2020-05-18 and Filed Under: development
When we look at the abstractions in our applications, we should see a description of the capabilities of our applications, not the capabilities of the abstraction
Let’s start this discussion by looking at an example of a simple repository.
public interface IMeetingReadRepository
{
IEnumerable<Meeting> GetMeetings(DateTime start, DateTime end);
}
It is easy to see the capability being described by this abstraction – any implementation of this interface will have the ability to load a collection of Meeting objects that occur within a given timeframe. There are still some unknown details of the implementation, but the capabilities are described reasonably well.
Now let’s look at a different implementation of the Repository pattern.
public interface IReadRepository<T>
{
IEnumerable<T> Get(Func<T, bool> predicate);
}
We can still see that something is going to be loaded using this abstraction, we just don’t know what, and we don’t know what criteria will be used.
This 2nd implementation is a more flexible interface. That is, we can use this interface to describe many different repositories that do many different things. All we have described in this interface is that we have the ability to create something that will load an entity. In other words, we have described our abstraction but said very little about the capabilities of the application itself. In this case, we have to look at a specific implementation to see what it loads, but we still have no idea what criteria can be used to load it.
public class MeetingReadRepository : IReadRepository<Meeting>
{
IEnumerable<Meeting> Get(Func<Meeting, bool> predicate);
}
We could extend this class with a method that specifically loads meetings by start and end date, but then that method is not on the abstraction so it cannot be used without leaking the details of the implementation to the application. The only way to implement this pattern in a way that uses the generic interface, but still fully describes the capabilities of the application is to use both methods described above. That is, we implement the specific repository, using the generic repository – layering abstraction on top of abstraction, as shown below.
public interface IMeetingReadRepository : IReadRepository<Meeting>
{
IEnumerable<Meeting> GetMeetings(DateTime start, DateTime end);
}
public class MeetingReadRepository : IMeetingReadRepository
{
IEnumerable<Meeting> GetMeetings(DateTime start, DateTime end)
=> Get(m => m.Start >= start && m.Start < end)
// TODO: Implement
IEnumerable<Meeting> Get(Func<Meeting, bool> predicate)
=> throw new NotImplementedException();
}
Is this worth the added complexity? It seems to me that as application developers we should be concerned about describing and building our applications in the simplest, most maintainable and extensible way possible. To do so, we need seams in our applications in the form of abstractions. However, we generally do not need to build frameworks on which we build those abstractions. Framework creation is an entirely other topic with an entirely different set of concerns.
I think it is easy to see how quickly things can get overly-complex when we start building abstractions on top of our own abstractions in our applications. Using Microsoft or 3rd party frameworks is fine when appropriate, but there is generally no need to build your own frameworks, especially within your applications. In the vast majority of cases, YAGNI.
Did I miss something here? Do you have a situation where you feel it is worth it to build a framework, or even part of a framework, within your applications. Please let me know about it @bsstahl.
Tags: abstraction apps coding-practices development entity flexibility framework generics principle yagni interface
The Value of Flexibility
Posted by bsstahl on 2019-02-14 and Filed Under: development
Have you ever experienced that feeling you get when you need to extend an existing system and there is an extension point that is exactly what you need to build on?
For example, suppose I get a request to extend a system so that an additional action is taken whenever a new user signs-up. The system already has an event message that is published whenever a new user signs-up that contains all of the information I need for the new functionality. All I have to do is subscribe a new microservice to this event message, and have that service take the new action whenever it receives a message. Boom! Done.
Now think about the converse. The many situations we’ve all experienced where there is no extension point. Or maybe there is an extension mechanism in place but it isn’t quite right; perhaps an event that doesn’t fire on exactly the situation you need, or doesn’t contain the data you require for your use case and you have to build an entirely new data support mechanism to get access to the bits you need.
The cost to “go live” is only a small percentage of the lifetime total cost of ownership. – Andy Kyte for Gartner Research, 30 March 2010
There are some conflicting principles at work here, but for me, these situations expose the critical importance of flexibility and extensibility in our application architectures. After all, maintenance and extension are the two greatest costs in a typical application’s life-cycle. I don’t want to build things that I don’t yet need because the likelihood is that I will never need them (see YAGNI). However, I don’t want to preclude myself from building things in the future by making decisions that cripple flexibility. I certainly don’t want to have to do a full system redesign ever time I get a new requirement.
For me, this leads to a principle that I like to follow:
I value Flexibility over Optimization
As with the principles described in the Agile Manifesto that this is modeled after, this does not eliminate the item on the right in favor of the item on the left, it merely states that the item on the left is valued more highly. This makes a ton of sense to me in this case because it is much easier to scale an application by adding instances, especially in these heady days of cloud computing, than it is to modify and extend it. I cannot add a feature by adding another instance of a service, but I can certainly overcome a minor or even moderate inefficiency by doing so. Of course, there is a cost to that as well, but typically that cost is far lower, especially in the short term, than the cost of maintenance and extension.
So, how does this manifest (see what I did there?) in practical terms?
For me, it means that I allow seams in my applications that I may not have a functional use for just yet. I may not build anything on those seams, but they exist and are available for use as needed. These include:
- Separating the tiers of my applications for loose-coupling using the Strategy and Repository patterns
- Publishing events in event-driven systems whenever it makes sense, regardless of the number of subscriptions to that event when it is created
- Including all significant data in event messages rather than just keys
There are, of course, dangers here as well. It can be easy to fire events whenever we would generally issue a logging message. Events should be limited to those in the problem domain (Domain Events), not application events. We can also reach a level of absurdity with the weight of each message. As with all things, a balance needs to be struck. In determining that balance, I value Flexibility over Optimization whenever it is reasonable and possible to do so.
Do you feel differently? If so, let me know @bsstahl.
Tags: abstraction agile coding-practices microservices optimization pattern principle flexibility yagni event-driven
A Requirement for AI Systems
Posted by bsstahl on 2017-05-24 and Filed Under: development
I've written and spoken before about the importance of using the Strategy Pattern to create maintainable and testable systems. Strategies are even more important, almost to the level of necessity, when building AI systems.
The Strategy Pattern is to algorithms what the Repository Pattern is to data stores, a useful and well-known abstraction for loose-coupling. — Barry Stahl (@bsstahl) January 6, 2017
The Strategy Pattern is an abstraction tool used to maintain loose-coupling between an application and the algorithm(s) that it uses to do its job. Since the algorithms used in AI systems have many different ways they could be implemented, it is important to abstract the implementation from the system that uses it. I tend to work with systems that use combinatorial optimization methods to solve their problems, but there are many ways for AIs to make decisions. Machine Learning is one of the hottest methods right now but AI systems can also depend on tried-and-true object-oriented logic. The ability to swap algorithms without changing the underlying system allows us the flexibility to try multiple methods before settling on a specific implementation, or even to switch-out implementations as scenarios or situations change.
When I give conference talks on building AI Systems using optimization methods, I always encourage the attendees to create a "naïve" solution first, before spending a lot of effort to build complicated logic. This allows the developer to understand the problem better than he or she did before doing any implementation. Creating this initial solution has another advantage though, it allows us to define the Strategy interface, giving us a better picture of what our application truly needs. Then, when we set-out to build a production-worthy engine, we do so with the knowledge of exactly what we need to produce.
There is also another component of many AIs that can benefit from the use of the Strategy pattern, and that is the determination of user intent. Many implementations of AI will include a user interaction, perhaps through a text-based interface as in a chatbot or a voice interface such as a personal assistant. Each cloud provider has their own set of services designed to determine the intent of the user based on the text or voice input. Each of these implementations has its own strengths and weaknesses. It is beneficial to be able to swap those mechanisms out at will, along with the ability to implement a "naïve" user intent solution during development, and the ability to mock user intent for testing. The strategy pattern is the right tool for this job as well.
As more and more of our applications depend heavily on algorithms, we will need to make a concerted effort to abstract those algorithms away from our applications to maintain loose-coupling and all of the benefits that loose-coupling provides. This is why I consider the Strategy Pattern to be a necessity when developing Artificial Intelligence solutions.
Tags: abstraction algorithms ai cloud coding-practices decision interface pattern testing unit testing
Testing the Untestable with Microsoft Fakes
Posted by bsstahl on 2017-03-20 and Filed Under: development
It is fairly easy these days to test code in isolation if its dependencies are abstracted by a reusable interface. But what do we do if the dependency cannot easily be referenced via such an interface? Enter Shims, from the Microsoft Fakes Framework(formerly Moles). Shims allow us to isolate our testing from any dependent methods, including methods in assemblies we do not control, even if those methods are not exposed through a reusable interface. To see how easy it is, follow along with me through this example.
In this sample code on GitHub, we are building a repository for an application that currently gets its data from a file exported from a system that tracks scheduled meetings. It is very likely that the system will, in the future, expose a more modern interface for that data so we have isolated the data storage using a simple Repository interface that has one method. This method, called GetMeetings returns a collection of Meeting entities that start during the specified date range. The method will return an empty collection if no data is found matching the specified criteria, and could throw either of 2 custom errors, a PermissionsExceptionwhen the user does not have the proper permissions to access the information, and a DataUnavailableException for when the data source is unavailable for any other reason, such as a network outage or if the data file cannot be located.
It is important to point out why a custom exception should be thrown when the data file is not found, rather than allowing the FileNotFoundException to bubble-up. If we allow the implementation-specific exception to bubble, we have exposed an implementation detail to the caller. That is, the calling code is now aware of the fact that this is a file system implementation. If code is written in a client that traps for FileNotFoundException, then the repository implementation is swapped-out for a SQL server implementation, the client code will have to change to handle the new types of errors that could be thrown by that implementation. This violates the Dependency Inversion principle, the “D” from the SOLID principles. By exposing only a custom exception, we are hiding those implementation details from the caller.
Downstream clients can easily test code that uses this repository without having to actually access the repository implementation because we have exposed the IMeetingSourceRepository interface. However, it is a bit more difficult to actually test the repository implementation itself. We have a few options here:
- Create data files that hold known data samples and load those files during unit testing.
- Create a wrapper around the System.IO namespace that exposes an interface, such as in the System.IO.Abstractions project.
- Don’t test any code that requires reaching-out to the file system.
Since I am of the opinion that 100% code coverage is both reasonable, and desirable (although not a measurable goal), I will summarily dispose of option 3 for the purpose of this analysis. I have used option 2 many times in my life, and while employing wrapper code is a valid and reasonable solution, it adds additional code to my production deployments that is very limited in terms of what it adds to the loose-coupling of my solution since I already am loosely-coupled to this implementation via the IMeetingSourceRepository interface.
Even though it is far from a perfect solution (many would consider them more integration tests than unit tests), I initially selected option 1 for this implementation. That is, I created data files and deployed them along with my tests. You can see the test files I created in the Data folder of the MeetingSystem.Data.FileSystem.Test project. These files are deployed alongside my tests using the DeploymentItem directive that decorates the Repository_GetMeetings_Should class of the test project. Using this method, I was able to create tests that:
- Verify that the correct # of meetings are returned from a file
- Verify that meetings are properly filtered by the StartDateTime of the meeting
- Validate the data elements returned from the file
- Validate that the proper custom exception is thrown if a FileNotFoundException is thrown by the underlying code
So we have verified nearly everything we need to test in our implementation. We’ve verified that the data is returned properly, and that one of our custom exceptions is being returned. But what about the PermissionsException? We were able to simulate a FileNotFoundException in our tests by just using a bad filename, but how do we test for a permissions problem? The ReadAllText method of the File object from System.IO will throw a System.Security.SecurityException if the file cannot be read due to a permissions problem. We need to trap this exception and throw our own exception, but how can we validate that we have successfully done so and that the functionality remains intact through future refactoring? How can we simulate a permissions exception on a file that we have enough permission on to deploy to a test folder? Enter Shims from the Microsoft Fakes Framework.
Instead of having our tests actually reach-out to the file system and actually try to load a file, we can intercept calls to the System.IO.File.ReadAllText method and have those calls execute some delegate code instead. This code, which we write in our test methods, can be specific to each test and exist only within the context of the test. As a result, we are not deploying any additional code to production, while still thoroughly validating our code. In fact, using this methodology, I could re-implement my previous tests, including my test data in the tests themselves, making these tests better unit tests. I could then reserve tests that actually reach out to files for integration test libraries that are run less frequently, and perhaps even behind the scenes.
Note: If you wish to follow-along with these instructions, you can grab the code from the DemoStart branch of the GitHub repo, rather than the Master branch where this is already done.
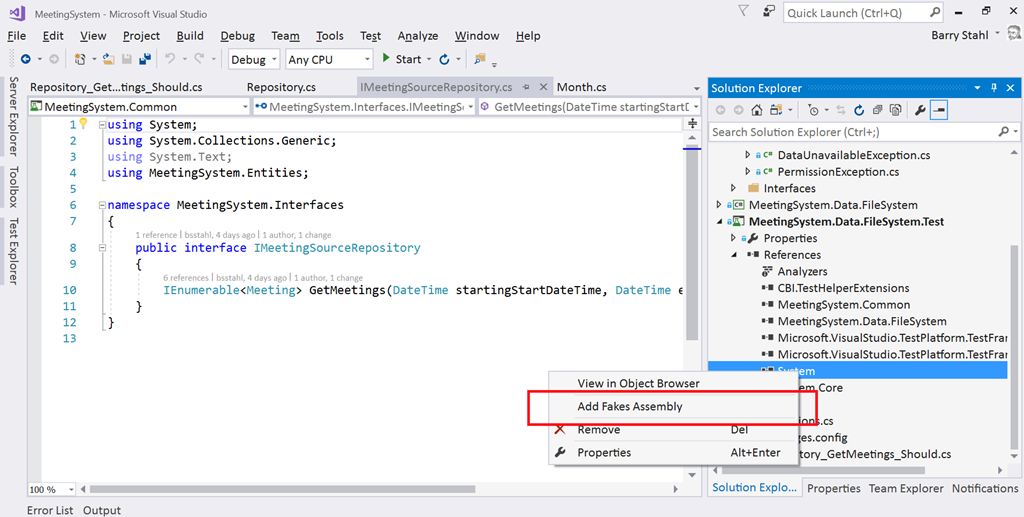
To use Shims, we first have to create a Fakes Assembly. This is done by right-clicking on the System reference in the test project from Visual Studio 2017, and selecting “Add Fakes Assembly” (full framework only – not yet available for .NET Core assemblies). Be sure to do this in the test project since we don’t want to actually deploy the Fakes assembly in our production code. Using the add fakes assembly menu item does 2 things:
- Adds a reference to Microsoft.QualityTools.Testing.Fakes assembly
- Creates 2 .fakes XML files in the Fakes folder within the test project. These items are built into corresponding fakes dll files that are deployed with the test project and used to provide stub and shim objects that mimic the objects in the selected assemblies. These fake objects reside in the same namespace as their “real” counterparts, except with “Fakes” on the end. Thus, our fake File object will reside in the System.IO.Fakes namespace.
The next step in using shims is to create a ShimsContext within a Using statement. Any method calls that execute within this context can be intercepted and replaced by our delegates. For example, a test that replaces the call to ReadAllText with a method that returns a single line of constant data can be seen below.
Methods on shim objects are referenced through properties of the fake object. These properties are of type FakesDelegate.Func and match the signature of the method being shimmed. The return data type is also appended to the property name so that each item’s signature can be represented with a different property name. In this case, the ReadAllText method of the File object is represented in the System.IO.Fakes.File object as a property called ReadAllTextString, of type FakesDelegate.Func<string, string>, since the method takes a string parameter (the path of the file), and returns a string (the text contents of the file). If we assign a method delegate to this property, that method will be executed in place of the call to System.IO.File.ReadAllText whenever ReadAllText is called within the ShimContext.
In the gist shown above, the variable p represents the input parameter and will hold the path specified in the test (in this case “April2017.abc”). The return value for our delegate method comes from the constant string dataFile. We can put anything we want here. We can replace the delegate with a call to an anonymous method, or with a call to an existing method. We can return a value gleaned from an external source, or, as is needed for our permissions test, throw an exception.
For the purposes of our test to verify that we throw a PermissionsException when a SecurityException is thrown, we can replace the value of the ReadAllTextString property with our delegate which throws the exception we need to test for, as seen here:
System.IO.Fakes.ShimFile.ReadAllTextString =
p => throw new System.Security.SecurityException("Test Exception");
Then, we can verify in our test that our custom exception is thrown. The full working example can be seen by grabbing the Master branch of the GitHub repo.
What can you test with these Shim objects that you were unable to test before? Tell me about it @bsstahl.
Tags: abstraction assembly code sample framework fakes interface moles mstest solid tdd testing unit testing visual studio
Demo Code for Testing in Visual Studio 2017
Posted by bsstahl on 2017-03-16 and Filed Under: event
The demo code for my presentation on Testing in Visual Studio 2017 at the VS2017 Launch event can be found on GitHub. There are 2 branches to this repository, the Main branch which holds the completed demo, and the DemoStart branch which holds the starting point of the demonstration in case you would like to implement the sample yourself.
The demo shows how Microsoft Fakes (formerly Moles) can be used to create tests against code that does not implement a reusable interface. This can be done without having to resort to integration style tests or writing extra wrapper code just to implement an interface. During my launch presentation, I also use this code to demonstrate the use of Intellitest (formerly Pex) to generate exploratory tests.
Tags: abstraction code sample coding-practices community conference development di interface microsoft moles mstest pex phoenix presentation tdd testing unit testing visual studio
Code Coverage Teaches and Protects
Posted by bsstahl on 2016-10-14 and Filed Under: development
I often hail code coverage as a great tool to help improve your code base. Today, my use of Code Coverage taught me something about the new .NET Core tooling, and helped protect me from having to support useless code for the lifespan of my project.
In the code below, I used a common dependency injection pattern. That is, an IServiceProvider object holding my dependencies is passed-in to my object and stored as a member variable. When a dependency is needed, I retrieve that dependency from the service provider, and then take action on it. Since there is no guarantee that the dependency I need will have been placed in the container, I use some common guard logic to protect my code.
templates = _serviceProvider.GetService<IEnumerable<Template>>();
if ((templates==null) || (!templates.Any(s => s.TemplateType==ContactPage)))
throw new TemplateNotFoundException(TemplateType.ContactPage, string.Empty);
In this code, I first test that I was able to retrieve a collection of Template objects from the service provider, then verify that the type of Template I need is present in the collection. If either is not the case, an exception is thrown.
I had two tests that covered this section of code, one where the collection was not added to the service provider, the other where an empty collection was added. Both tests passed, however, it wasn't until I looked at the results of the Code Coverage that I realized that the 1st test wasn't doing what I thought it was doing. It turns out that there is actually no way to get a null collection object out of the Microsoft.Extensions.DependencyInjection.ServiceProvider object I am using for my .NET Core apps. That provider simply returns an empty collection if there isn't one in the container. Thus, my check for null was never matched and that branch of code was never executed.
Based on this new knowledge of the behavior of the IServiceProvider, I had a few options. I could:
- Rewrite my test to check for an empty collection. This option seems redundant to me since my check to see if the container holds the template I need is really what I care about.
- Leave the code as-is just in case the behavior of the container changes, accepting that I have what is currently unnecessary and untestable code in my application. I considered this option but it seems to me that a better defense against the unlikely event of a breaking change in the IServiceProvider implementation is described below in option 3.
- Create a new test that verifies the behavior on the ServiceProvider that an empty collection is returned if no collection is supplied to the container. I am not a big fan of this option since it requires me to test OPC (other people's code), and because the risk of this type of breaking change is, in my opinion, extremely low.
- Remove the guard code that tests for null and the test that supports it. Since the code is completely unnecessary, the test itself is redundant because it is, essentially identical to the test verifying that the template I need is in the collection.
I'm sure you've guessed by now that I selected option 4. I removed the guard code and the test from my solution. In doing so, I removed dead code that served no purpose, but would have to be supported through the life of the project.
For those who might be thinking something similar to, "It's nice that the coverage tooling helped you learn about your code, but using Code Coverage as a metric is actually a bad idea so I won't use Code Coverage at all", I'd like to remind you that any tool, such as a hammer or a car, can be abused. That doesn't mean we don't continue to use them, we just make certain that we use them properly. Code Coverage is a horrible way to measure a development team or effort, but it is an outstanding tool and should be used by the development team whenever possible to discover things about the code base.
Tags: abstraction agile assert code analysis code coverage coding-practices csharp ioc testing unit testing dotnet
Using Target-Specific Code in a Portable Library
Posted by bsstahl on 2013-06-27 and Filed Under: development
On at least 2 occasions recently, I have heard speakers tell their audience that you cannot reference a target-specific .NET library (such as a .NET Framework 4.5 library) from a Portable Class Library. While this is technically true, it doesn't tell nearly the whole story. Even though we can't reference target-specific libraries, we can still USE these libraries. We can call their methods and access their properties under the right circumstances. We can gain access to these libraries via an abstraction. My preferred method of doing this is known as Dependency Injection.
I'm going to give some quick background on PCLs and DI before getting into the details of how they can be used in this context. If you are familiar with Dependency Injection and .NET Portable Class Libraries you can skip these sections.
.NET Portable Class Libraries (PCLs)
Portable Class Libraries are .NET assemblies designed to be used by multiple target platforms in the .NET application space. You can specify which targets you want to be able to use, such as .NET 4.5, Silverlight 4, Windows Phone 8, etc. The compiler then does the work to limit the APIs you have at your disposal in that library to only the intersection of all of the selected targets. This guarantees that any code written in that library will work in all of those targets, but no target-specific (device-specific) functionality will be available. These libraries are great for business-logic and other platform-independent services but are not useable for code that requires direct access to device features like the UI, camera, GPS, etc. This code can be compiled and tested once, and then accessed from any of the selected target contexts.
Dependency Injections (DI)
Dependency Injection is a way of maintaining loose-coupling between application components. Instead of having a piece of code have a direct knowledge of one of its dependencies, the code only has knowledge of an abstraction of that dependency, usually an interface. Since the client is unaware of the implementation and only has knowledge of the abstraction, the implementation of the dependency can change, and as long as it maintains compliance to the interface, the client code is unaware of the change and continues to function normally. The correct dependency must then be "injected" into the calling code prior to being used. The client only knows that the dependency implements the needed interface, but is unaware of the actual implementation. This becomes extremely useful in unit-testing since a fake dependency such as a mock data-provider can be injected by the test context, allowing the tests to focus on the layer being tested without having to test the dependencies as well. While this is not nearly the only reason to use DI, it is an example of an excellent benefit of its use.
Injecting Target-Specific Code into PCLs
Let's suppose we have a .NET Portable Class Library that implements the business logic of our application. We want the application to be able to run on the web under ASP.NET, on Windows 8 as a Modern Windows Store App, and on Windows Phone 8. We built the PCL using these specific targets so we know (the compiler guarantees) that this code will run in any of those platforms. However, this code needs to get its data from somewhere, and that somewhere is different depending on what environment we are running in. In ASP.Net for example, we may want to get the data from Session State, or from a back-end SQL Server, while in Windows Phone 8 and Windows 8 we want to use their (different) implementations of isolated storage. We can accomplish this by defining an interface that is usable by all 3 targets in a PCL. We can then create our 3 different implementations of the storage library using target-specific code and inject the appropriate one into the constructor of one or more of the classes in the business-logic PCL. This injection can be done directly by the parent application, which is going to be target-specific so it would have knowledge of which target is needed, or it can be done indirectly using a DI Container such as Microsoft Unity.
A sample app that is available in the 3 targets previously described may look something like this. The business-logic and domain layers (interfaces, exceptions, entities, etc) are both PCLs and exist for use in all 3 targets. The UI layer and Infrastructure layers (in this case, storage) are target-specific and require a separate implementation for each target platform. A system designed in this way can maximize the use of common, shared code while still making platform specific features available in a type-safe way.
If you are interested in seeing this implementation done live, you can come to one of my Code Camp talks on the subject, or request me as a speaker for your User Group by Contacting Me.
Tags: abstraction pcl device phone dotnet dependency injection windows
Code Sample for My TDD Kickstart Sessions
Posted by bsstahl on 2012-02-13 and Filed Under: development
The complete, working application for my .NET TDD Kickstart sessions can be found here.
Unzip the files into a solution folder and open the Demo.sln solution in a version of Visual Studio 2010 that has Unit Testing capability (Professional, Premium or Ultimate). Immediately, you should be able to compile the whole solution, and successfully execute the tests in the Bss.QueueMonitor.Test and Bss.Timing.Test libraries.
To get the tests in the other two test libraries (Bss.QueueMonitor.Data.EF.Test & Bss.QueueMonitor.IntegrationTest) to pass, you will need to create the database used to store the monitored data in the data-tier and integration tests, and enable MSMQ on your system so that a queue to be monitored can be created for the Integration test.
The solution is configured to use a SQLExpress database called TDDDemo. You can use any name or SQL implementation you like, you’ll just need to update the configuration of all of the test libraries to use the new connection. The script to execute in the new database to create the table needed to run the tests can be found in the Bss.QueueMonitor.Data.EF library and is called QueueDepthModel.edmx.sql.
You can install Message Queuing on computers running Windows 7 by using Programs and Features in the Control Panel. You do not need to create any specific queue because the integration test creates a queue for each test individually, then deletes the queue when the test is complete.
If you have any questions or comments about this sample, please start a conversation in the Fediverse @bsstahl or Contact Me.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di event framework ioc tdd testing unit testing visual studio
.NET TDD Kickstart
Posted by bsstahl on 2012-01-26 and Filed Under: event development
I head out to Fullerton tomorrow for the start of my .NET TDD Kickstart world tour. 
In this session, the speaker and the audience will "pair up" for a coding session which will serve as an introduction to Test Driven Development in an Agile environment. We will use C#, Visual Studio and Rhino Mocks to unit test code to be built both with and without dependencies. We will also highlight some of the common issues encountered during TDD and discuss strategies for overcoming them.
I will be presenting this session at numerous venues around the country this year, including, so far:
- Southern California Code Camp – Fullerton in January
- South Florida Code Camp – Ft. Lauderdale in February
- New Mexico .NET User’s Group – Albuquerque in March
- Twin Cities Code Camp – Minneapolis in April
If you are interested in having me present this or another session at your event, please contact me.
There is much more than an hour’s worth of material to be presented, so instead of trying to rush through everything I want to talk about during this time, I’ve instead taken some questions from this presentation and posted them below. Please contact me if you have any additional questions, need clarification, or if you have an suggestions or additions to these lists.
Update: I have moved the FAQ list here to allow it to be maintained separately from this post.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di framework ioc tdd testing unit testing visual studio
Order Matters in the Rhino Mocks Fluent Interface
Posted by bsstahl on 2012-01-16 and Filed Under: development
I noticed something interesting with Rhino Mocks today while testing some demo code:
Rhino.Mocks.Expect.Call(myDependency.MyMethod(param1)).Return(result).Repeat.Times(5);
behaves as I anticipated; it expects the call to MyMethod to be repeated 5 times and returns the value of result all 5 times. Meanwhile:
Rhino.Mocks.Expect.Call(myDependency.MyMethod(param1)).Repeat.Times(5).Return(result);
also has the expectation of 5 executions, but it returns the value of result only once. The other 4 executions return 0.
When I think about it now, it makes sense, but it wasn't the behavior I originally expected.
Tags: abstraction tdd testing mocks
Demo Code for EF4Ent Sessions
Posted by bsstahl on 2011-06-26 and Filed Under: development
I previously posted the slides for my Building Enterprise Apps using Entity Framework 4 talk here. I can now post the source code for the completed demo application. That code, created for use in Visual Studio 2010 Ultimate, is available in zip format below. This is the same code that was demonstrated at Desert Code Camp 2011.1 and SoCalCodeCamp 2011 as well as the New Mexico .NET User’s Group (NMUG).
Tags: abstraction agile assembly code analysis code camp code contracts code sample coding-practices conference csharp enterprise library entity entity framework fxcop interface testing unit testing visual studio
Desert Code Camp Presentation
Posted by bsstahl on 2011-04-02 and Filed Under: event development
Thanks to all of the organizers, speakers, sponsors and attendees of Desert Code Camp 2011.1. This is the first time that I’ve presented at a Code Camp and it was a fantastic experience for me. My session, Building Enterprise Apps using Entity Framework 4, was very well attended with 35 people cramming, standing-room-only, into a room with a capacity of 28 (please don’t tell the Fire Marshall). The demos went very well (everything worked as it was supposed to) and the feedback I’ve gotten so far was entirely positive.
I will be posting some additional information from the session shortly, including the sample code and the changes I make to the Microsoft All Rules code analysis ruleset, but I wanted to get the session slides up as quickly as possible.
If you have any additional feedback on the session, please feel free to contact me here, in the Fediverse @bsstahl or by email as shown in the slide deck.
DCC 2011.1 -- Building Enterprise Apps using Entity Framework 4
Tags: abstraction agile coding-practices community conference encapsulation entity entity framework provider unit testing us airways pluralsight
Developer Ignite in Chandler
Posted by bsstahl on 2009-07-13 and Filed Under: event development
I will be speaking at the Developer Ignite event in Chandler on July 22nd. The topic of my talk will be "Simplicity Through Abstraction" during which I will be giving a very high-level overview of using Dependency Injection as an Inversion-of-Control methodology to create simplicity in software architecture.
While putting my presentation together I have found a number of items that I wanted to include in my presentation, but simply can't due to the obvious constraints of a 5-minute presentation. Some of these items won't even get a mention, others will be mentioned only in passing. I include them here as a list of topics for me to discuss in future posts to this blog. Hopefully this will occur, at least in part, prior to the ignite event so that there will be a set of resources available to those at the event who were previously unfamiliar with these techniques and wish to explore them further.
These topics include:
- IoC Containers
- Dealing with Provider-Specific requirements
- Configuration as a dependency
- Local providers for external dependencies
- Providers as application tiers
- Testing at the provider level
- Top Down Design [Added: 7/12/2009]
If you have a topic that you are particularly interested in, or have any questions about IoC, Dependency Injection, or Providers that you would like me to answer, please use the comments or contact me @bsstahl.
Tags: ignite di ioc abstraction indirection interface tdd
Presentation Proposal - Developer Ignite Phoenix
Posted by bsstahl on 2009-06-26 and Filed Under: event
I just submitted the following proposal for a talk at Developer Ignite Phoenix which will be held July 22, 2009 at Gangplank in Chandler.
Simplicity Through Abstraction
The goal of this presentation is to explore, at a very high level, one methodology for software developers and architects to create software that is simple and maintainable, and thus has a lower total-cost-of-ownership (TCO).
Using abstraction via the provider pattern allows us to create software that is more testable, easier to map (find the piece of code that does X), and easier to understand at a component level. We can use providers to develop systems that have fewer bugs, and are more maintainable then tightly-coupled systems. As a result, these abstractions can significantly reduce costs for most systems, especially in the area of system maintenance.
I look forward to seeing you there.
