Tag: pattern
Introducing the Behavioral Layer
Posted by bsstahl on 2026-03-14 and Filed Under: development
Modern systems increasingly receive free‑text input, either from humans or from language models. These inputs can be ambiguous, incomplete, or phrased in ways the domain layer cannot act on directly. They are not the predictable, schema‑bound shapes that a traditional Anti‑Corruption Layer (ACL) is designed to translate. They require interpretation before any downstream component can reason about them. This is the realm of the Behavioral Layer.
What the Behavioral Layer Does
The Behavioral Layer is responsible for taking unstructured or highly variable inputs, such as those produced by a person or a language model, and producing a clean, normalized, and predictable shape that the rest of the system can trust. It is the architectural boundary where the system interprets intent before any downstream components have to reason about structure.
At a high level, the Behavioral Layer:
- Interprets what behavior the sender is attempting to invoke
- Normalizes inconsistently presented or incomplete inputs
- Detects structural and behavioral anomalies in the message
- Enriches the data with derived or inferred attributes
- Produces a stable output object that downstream components can rely on
The Behavioral Layer is defined by its responsibilities, not by any specific technology. You can implement it with deterministic rules, heuristics, or fine-tuned models. The architecture stays the same regardless of the tools you choose.
A Machine to Machine Example
To ground this in something concrete, consider a service that exposes an OpenAI‑compatible API for the purpose of intent determination and routing. This service is designed to accept natural language inside a structured request, classify the intent, and direct the call to the correct downstream system. Even in a machine to machine scenario, the request still contains unstructured text because the caller may be a human, a script, or an upstream LLM.
Here is an example of the kind of request this router might receive:
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are a plan selection assistant."
},
{
"role": "user",
"content": "please switch the user to the premium plan with the extras"
}
],
"user": "8821",
"source": "recommendation-service"
}
The outer structure is predictable, but the content is not. The router cannot forward this request until it determines what the caller is trying to do. The phrase premium plan with the extras is natural language, not an instruction the domain layer can act on. The router must identify the intent so it can send the request to the correct downstream service, which in this case is probably a plan or user service.
A Behavioral Layer implementation might produce something like this.
{
"userId": "8821",
"source": "recommendation-service",
"intent": "changePlan",
"confidence": "high",
"notes": [
{
"message": "The request refers to 'premium plan with the extras'."
}
]
}
The business logic within the router may take this input, determine which service is best suited to handle it, and route the original request to that service. The Behavioral Layer has taken a natural language request and expressed the sender's behavior in a structured form. It has identified what the caller is trying to do, surfaced any uncertainty, and produced a stable intent that the rest of the system can trust. Nothing about this output depends on domain rules or specific plan identifiers. The Behavioral Layer simply interprets the behavior contained in the text and turns it into a predictable shape that downstream components can build on. It has NOT concerned itself with mapping to the domain language, since this layer is not responsible for that. If additional mapping is required into the language of the domain, an anti-corruption or other mapping layer should be used to maintain the separation of concerns.
How It Works
The Behavioral Layer sits between the raw input and the ACL or domain layer. It receives whatever the outside world provides and applies a series of transformations that gradually reduce uncertainty.
A typical flow looks like this:
- Receive the raw input exactly as it arrived.
- Perform structural checks to understand what type of thing it might be.
- Apply behavioral checks to understand what the sender is trying to accomplish.
- Normalize fields, resolve aliases, and fill in missing but inferable information.
- Detect suspicious or incoherent combinations of attributes.
- Produce a Behavioral Output object that expresses the input in a clean, predictable shape.
Neither the ACL nor the domain layer ever sees the raw input. They only see the Behavioral Output, which keeps both layers small, deterministic, and easy to reason about.
How It Differs From a Traditional ACL
A traditional Anti-Corruption Layer protects the domain from other systems. It translates external models into internal ones, isolates upstream changes, and ensures that foreign concepts do not leak into the domain.
The Behavioral Layer protects the domain from ambiguous inputs. It resolves uncertainty, interprets intent, and produces a coherent behavioral shape before any translation or invariant enforcement occurs.
You can think of the responsibilities like this:
- Behavioral Layer: coherence
- ACL: translation and isolation
- Domain: correctness and invariants
The Behavioral Layer is not a variant of an ACL and not a replacement for one. It is a complementary layer that handles a different class of problems. The ACL expects structured, well-formed inputs. The Behavioral Layer exists precisely because real-world inputs often are not fully structured.
If you are building a "modular monolith", where all functionality is crammed into a single deployment unit, you can manage both sets of fuctionality (translation and behavioral) in a single place, however you probably don't want to mash them together so they can be more completely separated if it becomes appropriate.
Why is it Called the Behavioral Layer
The name comes from the nature of the inputs it handles. At this boundary, the system is not reacting to a schema. It is reacting to behavior. A person behaves unpredictably when typing a request. A language model behaves unpredictably when generating a response. A third-party system behaves unpredictably when sending a payload that almost matches your expectations.
The Behavioral Layer exists to interpret that behavior.
It focuses on what the sender is trying to do, not how the sender structures the data. It resolves intent, ambiguity, and variability before any translation or invariant enforcement occurs. The name fits because it describes the responsibility: making sense of behavior so the rest of the system does not have to.
Implementation Options
You can build a Behavioral Layer using several strategies, depending on your constraints and the variability of your inputs.
Deterministic Rules
This is the simplest approach. You define explicit rules for classification, normalization, and enrichment. It works well when the input space is small and predictable. It may work in more complex spaces with the help of a rules-engine or similar logic framework.
- Pros: transparent, easy to test, easy to reason about
- Cons: brittle when inputs vary widely or evolve over time
Heuristics and Pattern Matching
This approach uses scoring, thresholds, and pattern recognition to handle more variability without committing to full machine learning.
- Pros: flexible, adaptable, still deterministic
- Cons: harder to maintain, can drift into complexity
Fine-Tuned Language Models
A small, purpose-built model can classify intent, normalize fields, and map ambiguous inputs into structured forms with far more reliability than hand-written rules.
- Pros: handles real-world variability, reduces rule complexity, improves resilience
- Cons: requires training data, monitoring, and versioning discipline
The Behavioral Layer does not require a language model. LLMs and other probabilistic models simply make it easier to implement the layer when the input space becomes too variable for deterministic approaches.
Use Case 2: Human Input
The earlier example showed how a machine to machine request can contain natural language inside a structured API call. The same problem appears when a human interacts with the system. A user may type a request in their own words, combine multiple actions in a single message, or omit details that downstream components require. The Behavioral Layer handles this variability by interpreting what the user is trying to do and expressing that behavior in a predictable shape.
Imagine a system that receives inbound support messages from users. The messages can arrive through email, chat, or a mobile app. Users may not follow a template. They may combine multiple requests in one message. They may use synonyms, shorthand, or incomplete phrasing.
A raw message might look like:
"Hey, can you change my home address to the new one on file and also switch my plan to the premium thing"
The Behavioral Layer would:
- Translate the sender information into discrete fields
- Detect that the message contains two distinct intents
- Normalize "premium thing" into a known plan identifier
- Extract the address reference and map it to the stored address record
As shown below, this layer might also interpret normalized data that it has access to. For example, if the list of plans is accessible to the Behavioral Layer, it might add an indication that "premium thing" is not an exact match to a known plan. This is one of the places however where some judgement is required because, depending on the circumstances, that functionality might be better left to an ACL or the Domain.
The Behavioral layer would consider the input above along with the email metadata and might produce an output object similar to the one shown below:
{
userIds: [
"email": "sampleuser@cognitiveinheritance.com",
"eMailName": "Sample User",
"dkimDomain": "cognitiveinheritance.com",
"spfDomain": "sendgrid.net"
],
intents: [
{ type: "updateAddress", addressId: "home" },
{ type: "changePlan", planId: "premiumPlan" }
],
confidence: "high",
anomalies: [
{ "fieldName": "planId", "value": "'premium thing' not an exact match to plan name" }
]
}
The ACL or domain layer now has a clean, predictable structure to work with. It does not need to parse free‑form text or guess what the user meant. The Behavioral Layer has already done that work.
What Comes Next
This post introduces the Behavioral Layer as an architectural concept and distinguishes it from a traditional ACL. In the next article, we will look at how fine‑tuned language models can assist with the transformations inside the layer. We will walk through how to build small, purpose‑built models using Microsoft Foundry, how to train them on your domain, and how to integrate them into a reliability‑first architecture.
Tags: architecture ddd responsibility pattern
You Got Your Policy in my Redis
Posted by bsstahl on 2021-04-22 and Filed Under: development
Using a distributed cache such as Redis is a proven method of improving the performance and reliability of our applications. As with any tool, use in accordance with best practices will help to reduce support time and outages, and give our customers the best possible experience.
As much as we’d like to believe that our cloud services are highly available and reliable, the fact is that no matter how much effort goes into their resilience, we will never get 100% availability from them. Even if it is just due to random Internet routing issues, we must take measures to protect our applications, our customers, and our support personnel, from these inevitable hiccups. There are a number of patterns we can use to make our cache access more resilient, and therefore less susceptible to these outages. There are also libraries we can use to implement these patterns, allowing us to declare policies for these patterns, and implement and compose them with ease.
These concepts are useful in all tool chains, with or without a policy library, and policy libraries are available for many common development languages. However, this article will focus on using the Polly library in C# for implementation. That said, I will attempt to describe the concepts, as much as possible, in terms that are accessible to developers using all tool chains. I have also used the Polly library generically. That is, any calls that result in data being returned could be used in place of the caching operations described here. In addition, for clients that use Microsoft’s IDisributedCache abstraction, there is a caching specific package, Polly.Caching.Distributed, that does all of these same things, but with a simplified syntax for caching operations.
Basic Cache-Retrieval
The most straightforward use-case for a caching client is to have the cache pre-populated by some other means so that the client only has to retrieve required values. In this situation, either the value is successfully retrieved from the cache, or some error condition occurs (perhaps a null returned or an Exception thrown). This usage, as described, is very simple, but can still provide a lot of value for our applications. Having low-latency access to data across multiple instances of our application can certainly improve the performance of our apps, but can also improve their reliability, depending on the original data source. We can even use the cache as a means for our services to own-their-own-data, assuming we take any long-term persistence needs into account.
It goes without saying however that this simple implementation doesn’t handle every circumstance on its own. Many situations exist where the data cannot all be stored in the cache. Even if the cache can be fully populated, there are circumstances, depending on the configuration, where values may need to be evicted. This pattern also requires each client to handle cache errors and misses on their own, and provides no short-circuiting of the cache during outage periods. In many cases, these types of situations are handled, often very differently, by the consuming clients. Fortunately, tools exist for many languages that allow us to avoid repeating the code to manage these situations by defining policies to handle them.
Using a Circuit-Breaker Policy
It is an unfortunate fact of distributed system development that our dependencies will be unavailable at times. Regardless of how reliable our networks and cloud dependencies are, we have to act like they will be unavailable, because sometimes they will be. One of the ways we have to protect our applications from these kinds of failures is to use a circuit-breaker.
A circuit-breaker allows us to specify conditions where the cache is not accessed by our client, but instead the cache-call fails immediately. This may seem counterintuitive, but in circumstances where we are likely in the middle of an outage, skipping the call to the cache allows us to fail quickly. This quick-failure protects the users from long timeout waits, and reduces the number of network calls in-process. Keeping the number of network calls low reduces the risk of having our pods recycled due to port-exhaustion problems, and allows our systems to recover from these outages gracefully.
To use a Polly circuit-breaker in C#, we first define the policy, then execute our request against the policy. For example, a sample policy to open the circuit-breaker under the configured conditions and log the change of state is shown below.

This code uses the static logger to log the state changes and has members (_circuitBreakerFailureThresholdPercentage, _circuitBreakerSamplingDuration, etc...) for the configuration values that specify the failure conditions. For example, we could configure this policy to open when 50% of our requests fail during a 15 second interval where we handle at least 20 requests. We could then specify to keep the circuit open for 1 minute before allowing traffic through again. A failure, in this policy, is defined at the top of the above expression as:
- When any Exception occurs (.Handle
() ) or - When a default result is returned such as a null (.OrResult(default(T)))
Once our policy is available, we can simply execute our cache requests in the context of that policy. So, if we call our cache on a dependency held in a _cacheClient member, it might look like the samples below with and without using a policy.
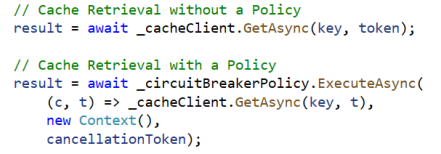
To use the policy, we call the same method as we would call without the policy, but do so within the ExecuteAsync method of the policy object. You might notice there is a Context object passed in to the policy. This allows information to be passed-around to the different sections of the policy. We will be using this later.
...the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
Executing our cache requests within the context of this policy allows the policy to keep track of the results of our requests and trigger the policy if the specified conditions are met. When this policy is triggered, the state of the circuit is automatically set to open and no requests are allowed to be serviced until the circuit is closed again. When either of these state transitions occur (Closed=>Open or Open=>Closed) the appropriate lambda is executed in the policy. Only logging is being done in this example, but the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
We can now protect our applications against outages. However, this does nothing to handle the situation where the data is not available in our cache. For this, we need a Failover (Fallback) policy.
Using a Failover Policy to Fall-Back to the System of Record
Many use-cases for caching involve holding frequently or recently retrieved values in the cache to avoid round-trips to a relational or other data source. This pattern speeds access to these data items while still allowing the system to gather and cache the information if it isn’t already in the cache.
Many policy libraries have methods to handle this pattern as well. A Polly policy describing this pattern is shown below.
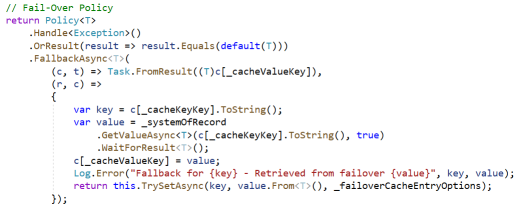
And to access the cache using this policy, we might use code like this.
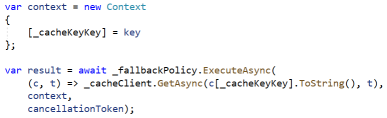
You’ll notice that the code to update the cache is specified in the policy itself (the 2nd Lambda). Like the circuit-breaker, this policy responds when any Exception is thrown or a default value (i.e. null) is returned. Unlike the circuit-breaker however, this policy executes its code every time there is a miss or error, not just when thresholds have been exceeded. You’ll also notice that, in the calling code, a Context object is defined and the cache key value is added to that property bag. This is used in the handling mechanism to access the value from the System of Record and to update the cache with that value. Once the value has been updated in the cache, it is returned to the caller by being pulled back out of the property bag by the 1st Lambda expression in the policy.
We’ll need to be careful here that we set the _failoverCacheEntryOptions appropriately for our use-case. If we allow our values to live too long in the cache without expiring, we can miss changes, or cause other values to be ejected from the cache. As always, be thoughtful with how long to cache the values in your use-case. We also do nothing here to handle errors occurring in the fallback system. You’ll want to manage those failures appropriately as well.
We can now declare a policy to fail-over to the system of record if that is appropriate for our use-case, but this policy doesn’t do anything to protect our systems from outages like our circuit-breaker example does. This is where our policy libraries can really shine, in their ability to combine policies.
Wrapping It Up - Combining Multiple Policies using Policy Wrappers
One of the real advantages of using a policy library like Polly is the ability to chain policies together to form complex reliability logic. Before going too deep into how we can use this to protect our cache-based applications, let’s look at the code to combine the two policies defined above, the Circuit-Breaker and Fallback policies. The code inside the CreateFallbackPolicy and CreateCircuitBreakerPolicy methods are just the return statements shown above that create each policy.
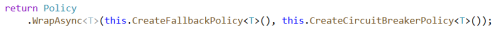
These policies are executed in the order specified, which means that the last one specified is the one closest to the cache itself. This is important because, if our circuit is open, we want the Fallback policy to handle the request and fail-over to the system of record. If we were to reverse this order, opening the circuit would mean that the Fallback policy is never executed because the Circuit Breaker policy would block it.
This combined policy, as shown above, does everything we need from a cache client for our most common use-cases.
- Returns the value from the cache on cache-hit
- Returns the value from the backup system (system of record) on cache-miss
- Populates the cache with values retrieved from the backup system on cache-miss
- Opens the circuit for the specified time if our failure thresholds are reached, indicating an outage
- Gives us the opportunity to perform other recovery logic, such as resetting the Multiplexer, when the circuit is opened
- Closes the circuit again after the specified timeframe
- Gives us the opportunity to to perform other logic as needed when the circuit is closed
In many cases our applications have implemented some or all of this logic themselves, whether it is in custom clients or abstractions like Queries or Repositories. If these applications are working well, and adequately protecting our systems and our customers from the inevitable failures experienced by distributed systems, there is certainly no need to change them. However, for systems that are experiencing problems when outages occur, or those being built today, I highly recommend considering using a policy library such as Polly to implement these reliability measures.
Tags: development reliability caching pattern
The Value of Flexibility
Posted by bsstahl on 2019-02-14 and Filed Under: development
Have you ever experienced that feeling you get when you need to extend an existing system and there is an extension point that is exactly what you need to build on?
For example, suppose I get a request to extend a system so that an additional action is taken whenever a new user signs-up. The system already has an event message that is published whenever a new user signs-up that contains all of the information I need for the new functionality. All I have to do is subscribe a new microservice to this event message, and have that service take the new action whenever it receives a message. Boom! Done.
Now think about the converse. The many situations we’ve all experienced where there is no extension point. Or maybe there is an extension mechanism in place but it isn’t quite right; perhaps an event that doesn’t fire on exactly the situation you need, or doesn’t contain the data you require for your use case and you have to build an entirely new data support mechanism to get access to the bits you need.
The cost to “go live” is only a small percentage of the lifetime total cost of ownership. – Andy Kyte for Gartner Research, 30 March 2010
There are some conflicting principles at work here, but for me, these situations expose the critical importance of flexibility and extensibility in our application architectures. After all, maintenance and extension are the two greatest costs in a typical application’s life-cycle. I don’t want to build things that I don’t yet need because the likelihood is that I will never need them (see YAGNI). However, I don’t want to preclude myself from building things in the future by making decisions that cripple flexibility. I certainly don’t want to have to do a full system redesign ever time I get a new requirement.
For me, this leads to a principle that I like to follow:
I value Flexibility over Optimization
As with the principles described in the Agile Manifesto that this is modeled after, this does not eliminate the item on the right in favor of the item on the left, it merely states that the item on the left is valued more highly. This makes a ton of sense to me in this case because it is much easier to scale an application by adding instances, especially in these heady days of cloud computing, than it is to modify and extend it. I cannot add a feature by adding another instance of a service, but I can certainly overcome a minor or even moderate inefficiency by doing so. Of course, there is a cost to that as well, but typically that cost is far lower, especially in the short term, than the cost of maintenance and extension.
So, how does this manifest (see what I did there?) in practical terms?
For me, it means that I allow seams in my applications that I may not have a functional use for just yet. I may not build anything on those seams, but they exist and are available for use as needed. These include:
- Separating the tiers of my applications for loose-coupling using the Strategy and Repository patterns
- Publishing events in event-driven systems whenever it makes sense, regardless of the number of subscriptions to that event when it is created
- Including all significant data in event messages rather than just keys
There are, of course, dangers here as well. It can be easy to fire events whenever we would generally issue a logging message. Events should be limited to those in the problem domain (Domain Events), not application events. We can also reach a level of absurdity with the weight of each message. As with all things, a balance needs to be struck. In determining that balance, I value Flexibility over Optimization whenever it is reasonable and possible to do so.
Do you feel differently? If so, let me know @bsstahl.
Tags: abstraction agile coding-practices microservices optimization pattern principle flexibility yagni event-driven
A Requirement for AI Systems
Posted by bsstahl on 2017-05-24 and Filed Under: development
I've written and spoken before about the importance of using the Strategy Pattern to create maintainable and testable systems. Strategies are even more important, almost to the level of necessity, when building AI systems.
The Strategy Pattern is to algorithms what the Repository Pattern is to data stores, a useful and well-known abstraction for loose-coupling. — Barry Stahl (@bsstahl) January 6, 2017
The Strategy Pattern is an abstraction tool used to maintain loose-coupling between an application and the algorithm(s) that it uses to do its job. Since the algorithms used in AI systems have many different ways they could be implemented, it is important to abstract the implementation from the system that uses it. I tend to work with systems that use combinatorial optimization methods to solve their problems, but there are many ways for AIs to make decisions. Machine Learning is one of the hottest methods right now but AI systems can also depend on tried-and-true object-oriented logic. The ability to swap algorithms without changing the underlying system allows us the flexibility to try multiple methods before settling on a specific implementation, or even to switch-out implementations as scenarios or situations change.
When I give conference talks on building AI Systems using optimization methods, I always encourage the attendees to create a "naïve" solution first, before spending a lot of effort to build complicated logic. This allows the developer to understand the problem better than he or she did before doing any implementation. Creating this initial solution has another advantage though, it allows us to define the Strategy interface, giving us a better picture of what our application truly needs. Then, when we set-out to build a production-worthy engine, we do so with the knowledge of exactly what we need to produce.
There is also another component of many AIs that can benefit from the use of the Strategy pattern, and that is the determination of user intent. Many implementations of AI will include a user interaction, perhaps through a text-based interface as in a chatbot or a voice interface such as a personal assistant. Each cloud provider has their own set of services designed to determine the intent of the user based on the text or voice input. Each of these implementations has its own strengths and weaknesses. It is beneficial to be able to swap those mechanisms out at will, along with the ability to implement a "naïve" user intent solution during development, and the ability to mock user intent for testing. The strategy pattern is the right tool for this job as well.
As more and more of our applications depend heavily on algorithms, we will need to make a concerted effort to abstract those algorithms away from our applications to maintain loose-coupling and all of the benefits that loose-coupling provides. This is why I consider the Strategy Pattern to be a necessity when developing Artificial Intelligence solutions.
