Tag: presentation
The Return of the Valley .NET User Groups
Posted by bsstahl on 2025-11-04 and Filed Under: event
After a long pause, I’m excited to share some great news: the Valley of the Sun .NET user groups are officially restarting in 2026! As one of the organizers — and one of the speakers for our first event — I couldn’t be more thrilled to help bring our community back together.
We’ll be hosting quarterly meetups, alternating between:
- NWVDNUG (Northwest Valley .NET User Group)
- SEVDNUG (Southeast Valley .NET User Group)
Each event will be in-person at one location, with a livestream option for the other group — so no matter where you are, you’ll have a way to participate.
🚀 First Event: Tuesday, January 20, 2026 at ASU West Valley
To kick things off, Rob Richardson and I will be presenting:
“.NET Aspire Accelerator: Fast-Track to Cloud-Native Development”
This talk is a shortened version of the workshop Rob and I delivered in October 2025 in Porto, Portugal — tailored for our local community.
We’ll be live at the Arizona State University (ASU) West Valley campus, and the session will be streamed by the .NET Foundation’s NET Virtual User Group, making it accessible to developers across the Valley and around the world.
🔄 What’s Next?
The follow-up event will be in the SE Valley around April, continuing our quarterly rotation and hybrid format. We’re committed to making these meetups inclusive, energizing, and valuable for developers across the valley.
Meetup listings for January will be posted soon — on both the NWVDNUG and SEVDNUG pages — so keep an eye out and RSVP when they go live.
Thanks for being part of this community. I can’t wait to see familiar faces and meet new ones as we reboot and reconnect in 2026.
Tags: community development dotnet phoenix presentation speaking user-group
Simple Linear Regression
Posted by bsstahl on 2023-02-13 and Filed Under: development
My high-school chemistry teacher, Mrs. J, had a name for that moment when she could see the lightbulb go on over your head. You know, that instant where realization hits and a concept sinks-in and becomes part of your consciousness. The moment that you truly "Grok" a principle. She called that an "aha experience".
One of my favorite "aha experiences" from my many years as a Software Engineer, is when I realized that the simplest neural network, a model with one input and one output, was simply modeling a line, and that training such a model, was just performing a linear regression. Mind. Blown.
In case you haven't had this particular epiphany yet, allow me to go into some detail. I also discuss this in my conference talk, A Developer's Introduction to Artificial Intelligences.
Use Case: Predict the Location of a Train
Let's use the example of predicting the location of a train. Because they are on rails, trains move in 1-dimensional space. We can get a good approximation of their movement, especially between stops, by assuming they travel at a consistent speed. As a result, we can make a reasonably accurate prediction of a train's distance from a particular point on the rail, using a linear equation.
If we have sensors reporting the location and time of detection of our train, spread-out across our fictional rail system, we might be able to build a graph of these reports that looks something like this:
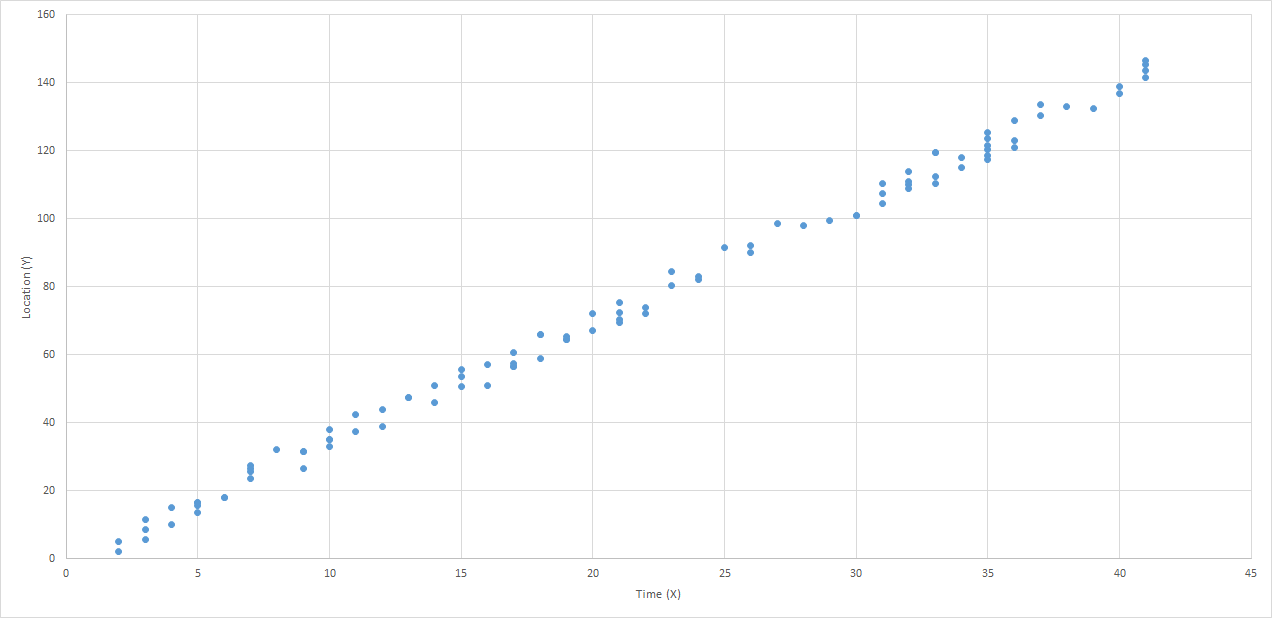
I think it is clear that this data can be represented using a "best-fit line". Certainly there is some error in the model, perhaps due to sensor or reporting errors, or maybe just to normal variance of the data. However, there can be no doubt that the best fit for this data would be represented as a line. In fact, there are a number of tools that can make it very easy to generate such a line. But what does that line really represent? To be a "best-fit", the line needs to be drawn in such a way as to minimize the differences between the values found in the data and the values on the line. Thus, the total error between the values predicted by our best-fit line, and the actual values that we measured, is as small as we can possibly get it.
A Linear Neural Network
A simple neural network, one without any hidden layers, consists of one or more input nodes, connected with edges to one or more output nodes. Each of the edges has a weight and each output node has a bias. The values of the output nodes are calculated by summing the product of each input connected to it, along with its corresponding weight, and adding in the output node's bias. Let's see what our railroad model might look like using a simple neural network.
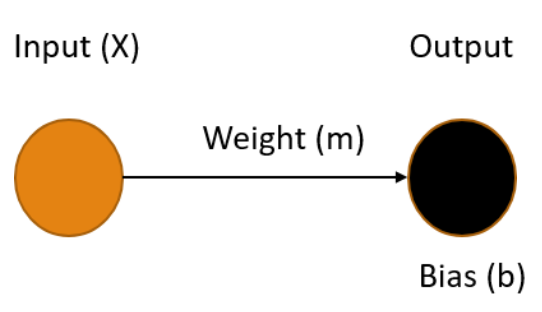
Ours is the simplest possible neural network, one input connected to one output, where our X value (time) is the input and the output Y is our prediction of the distance the train has traveled in that time. To make the best prediction we need to determine the values for the weight of the edge m and the bias of the output node b that produce the output that minimizes the errors in the model.
The process of finding the weights and biases values for a neural network that minimize the error is know as Training the model. Once these values are determined, we use the fact that we multiply the weight by the input (m * X) and add in the bias. This gives us an equation in the form:
Y = mX + b
You may recognize this as the slope-intercept form of the equation for a line, where the slope m represents the speed of the train, and the bias b represents the starting distance from the origin. Once our training process gives us values for m and b, we can easily plug-in any value for X and get a prediction for the location of our train.
Training a Model
Training an AI model is simply finding the set of parameters that minimize the difference between the predicted output and the actual output. This is key to understanding AI - it's all about minimizing the error. Error minimization is the exact same goal as we have when performing a linear regression, which makes sense since these regressions are predictive models on their own, they just aren't generally depicted as neural networks.
There are many ways to perform the error-minimization process. Many more complicated models are trained using an iterative optimization routine called Gradient Descent. Extremely simple models like this one often use a less complicated process such as Ordinary Least Squares. The goals are the same however, values for weights and biases in the model are found that minimize the error in the output, resulting in a model can make the desired predictions based on known inputs.
Regardless of the method used, the realization that training the simplest neural network results in a model of a line provided the "aha experience" I needed as the foundation for my understanding of Machine Learning models. I hope, by publishing this article, that others may also benefit from this recognition.
Tags: ai algorithms ml optimization presentation
South Florida Code Camp 2019
Posted by bsstahl on 2019-03-03 and Filed Under: event
Thanks again to all the organizers, speakers and attendees of the 2019 South Florida Code Camp. As always, it was an amazing and fun experience.
The slides for my presentation are online Intro to WebAssembly and Blazor and the Blazor Chutes & Ladders Simulation sample code can be found in my AIDemos GitHub Repo.
Tags: assembly blazor code camp code sample development framework introduction microsoft presentation
Three Awesome Months
Posted by bsstahl on 2019-02-26 and Filed Under: event
The next few months are going to be absolutely amazing. We've got some great events coming up in March and April right here in the Valley of the Sun. In addition, I currently have 4 conferences scheduled in 4 different countries on 2 continents.
AZGiveCamp IX - Presented by Quicken Loans - March 8th-10th
The most important occasion coming up is the 9th AZGiveCamp Hackathon of Help. This year, we're very fortunate to have Quicken Loans presenting our event and hosting it at their new facility in downtown Phoenix. At AZGiveCamp, Arizona's finest technologists will put their skills to work creating software for some great local charity organizations. We help them help our community by using our skills to create tools that help them further their mission.
Visual Studio 2019 Arizona Launch - April 16th
Another fun event for developers in the valley is the Visual Studio 2019 Arizona Launch event being hosted at Galvanize. We'll have some great speakers talking about how Visual Studio 2019 is a more productive, modern, and innovative environment for building software.
Around the World
In March, I'll be visiting opposite ends of the east coast of North America.
First, on March 2nd, I'll be attending the always amazing South Florida Code Camp in Fort Lauderdale. This event is right up there with the biggest community conferences in the country and is always worth attending. This will be the 7th year I've presented at SoFlaCC. If you're in the area I hope you'll attend.
Later in March, I cross the border into Canada to attend ConFoo Montreal. This will be my first trip ever to Montreal so I hope the March weather is kind to this 35 year Phoenix resident. The event runs from March 13th - 15th and there will be 2 Canadiens games during the time I am there so I should be able to get to at least one of them.
In May I get to do a short tour of Europe, spending 2 weeks at conferences in Budapest, Hungary (Craft Conference), and Marbella, Spain (J on the Beach). While I have done some traveling in Europe before, I have never been to Spain or Hungary so I am really looking forward to experiencing the history and culture that these two cities have to offer.
Keep up With Me
I maintain a list of my presentations, both past and upcoming, on the Community Speaker page of this blog. I also try to document my conference experiences @bsstahl. If you are going to be attending any of these events, please be sure to ping me and let me know.
Tags: azgivecamp charity code camp conference givecamp microsoft nonprofit phoenix presentation schedule speaking user group visual studio
SoCalCodeCamp Slide Decks
Posted by bsstahl on 2018-11-10 and Filed Under: event
The slide decks for my two talks at SoCalCodeCamp USC from November 10, 2018 are below.
- Intro to WebAssembly Using Blazor – SGM-124 at 1:30 pm
- Building .NET Applications for any Cloud with Cloud Foundry – GFS-207 at 4:00 pm
Thanks to all of the organizers and attendees of this always amazing event.
Tags: blazor cloud cloud foundry code camp community conference open source presentation slides speaking wasm webassembly
Intro to WebAssembly Using Blazor
Posted by bsstahl on 2018-09-26 and Filed Under: event
I will be speaking tonight, 9/26/2018 at the Northwest Valley .NET User Group and tomorrow, 9/27/2018 at the Southeast Valley .NET User Group. I will be speaking on the subject of WebAssembly. The talk will go into what WebAssembly programs look and act like, and how they run, then explore how we as .NET developers can write WebAssembly programs with Microsoft’s experimental platform, Blazor.
Want to run your .NET Standard code directly in the browser on the client-side without the need for transpilers or browser plug-ins? Well, now you can with WebAssembly and Blazor.
WebAssembly (WASM) is the W3C specification that will be used to provide the next generation of development tools for the web and beyond. Blazor is Microsoft's experiment that allows ASP.Net developers to create web pages that do much of the scripting work in C# using WASM.
Come join us as we explore the basics of WebAssembly and how WASM can be used to run existing C# code client side in the browser. You will walk away with an understanding of what WebAssembly and Blazor can do for you and how to immediately get started running your own .NET code in the browser.
The slide deck for these presentations can be found here IntroToWasmAndBlazor-201809.pdf.
Tags: apps community csharp framework html5 introduction microsoft presentation phoenix speaking user group ux wasm webassembly w3c
Desert Code Camp – October 2017
Posted by bsstahl on 2017-10-16 and Filed Under: event
Another great Desert Code Camp is in the books. A huge shout-out to all of the organizers, speakers & attendees for making the event so awesome.
I was privileged to be able to deliver two talks during this event:
A Developer’s Survey of AI Techniques: Artificial Intelligence is far more than just machine learning. There are a variety of tools and techniques that systems use to make rational decisions on our behalf. In this survey designed specifically for software developers, we explore a variety of these methods using demo code written in c#. You will leave with an understanding of the breadth of AI methodologies as well as when and how they might be used. You will also have a library of sample code available for reference.
- Code Samples: GitHub Repo
- Slide Deck: PDF
AI that can Reason "Why": One of the big problems with Artificial Intelligences is that while they are often able to give us the best possible solution to a problem, they are rarely able to reason about why that solution is the best. For those times where it is important to understand the why as well as the what, Hybrid AI systems can be used to get the best of both worlds. In this introduction to Hybrid AI systems, we'll design and build one such system that can solve a complex problem for us, and still provide information about why each decision was made so we can evaluate those decisions and learn from our AI's insights.
- Code Samples: GitHub Repo
- Slide Deck: PDF
Please feel free to contact me @bsstahl with any questions or comments on these or any of my presentations.
Tags: ai algorithms code camp code sample community conference optimization presentation professional development phoenix slides speaking
An Example of a Hybrid AI Implementation
Posted by bsstahl on 2017-10-13 and Filed Under: development
I previously wrote about a Hybrid AI system that combined logical and optimization methods of problem solving to identify the best solution to an employee shift assignment problem. This implementation was notable in that a hybrid approach was used so that the optimal solution could be found, but the system could still indicate to the users why a particular assignment was, or wasn’t, included in the results.
I recently published to GitHub a demo of a similar system. I use this demo in my presentation Building AI Solutions that can Reason Why. The code demonstrates the hybridization of multiple AI techniques by creating a solution that iteratively applies a combinatorial optimization engine. Different results are obtained by varying the methods of applying the constraints in that model. In the final (4th) demo method, an iterative process is used to identify what the shortcomings of the final product are, and why they are necessary.
These demos use the Conference Scheduler AI project to build a valid schedule.
There are 4 examples, each of which reside in a separate test method:
ScheduleWithNoRestrictions()
The 1st method in BasicExamplesDemo.cs shows an unconstrained model where only the hardest of constraints are excluded. That is, the only features of the schedule that are considered by the scheduler are those that are absolute must-haves. Since there are fewer hard constraints, it is relatively easy to satisfy all the requirements of this model.
ScheduleWithHardConstraints()
The 2nd method in BasicExamplesDemo.cs shows a fully constrained model where all constraints are considered must-haves. That is, the only schedules that will be considered for our conference are those that meet all of the scheduling criteria. As you might imagine, this can be difficult to do, in this case resulting in No Feasible Solution being found. Because we use a combinatorial optimization model, the system gives us no clues as to which of the constraints cause the infeasibility, or what to do that might allow it to find a solution.
ScheduleWithTimePreferencesAsAnOptimization()
The 3rd method in BasicExamplesDemo.cs shows the solution when the true must-haves are considered hard constraints but preferences are not. The AI attempts to optimize the solution by satisfying as many of the soft constraints (preferences) as possible. This results in an imperfect, but possibly best case schedule, but one where we have little insight as to what preferences were not satisfied, and almost no insight as to why.
AddConstraintsDemo()
The final demo, and the only method in AddConstraintsDemo.cs, builds on the 3rd demo, where the true must-haves are considered hard constraints but preferences are not. Here however, instead of attempting to optimize the soft constraints, the AI iteratively adds the preferences as hard constraints, one at a time, re-executing the solution after each to make sure the problem has not become infeasible. If the solution has become infeasible, that fact is recorded along with what was being attempted. Then that constraint is removed and the process continues with the remaining constraints. This Hybrid process still results in an imperfect, but best-case schedule. This time however, we not only know what preferences could not be satisfied, we have a good idea as to why.
The Hybrid Process
The process of iteratively executing the optimization, adding constraints one at a time, is show in the diagram below. It is important to remember that the order in which these constraints are added here is critical since constraining the solution in one way may limit the feasibility of the solution for future constraints. Great care must be taken in selecting the order that constraints are added in order to obtain the best possible solution.
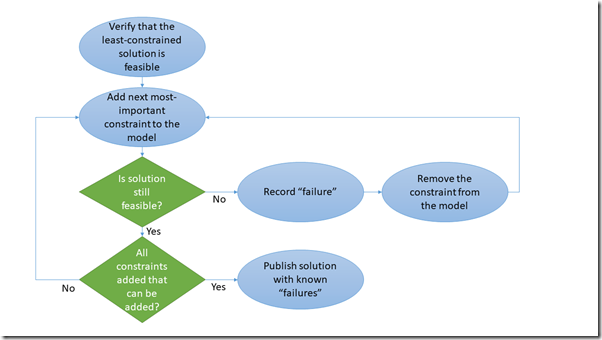
The steps are as follows:
- Make sure we can solve the problem without any of the soft constraints. If the problem doesn’t have any feasible solutions at the start of the process, we are certainly not going to find any by adding constraints.
- Add a constraint to the solution. Do so by selecting the next most important constraint in order. In the case of our conference schedule, we are adding in speaker preferences for when they speak. These preferences are being added in the order that they were requested (first-come first-served).
- Verify that there is still at least 1 feasible solution to the problem after the constraint is added. If no feasible solutions can be found:
- Remove the constraint.
- Record the details of the constraint.
- Record the current state of the model.
- Repeat steps 2 & 3 until all constraints have been tried.
- Publish the solution
- The resulting schedule
- The constraints that could not be added. This tells us what preferences could not be accommodated.
- The state of the model at the time the failed constraints were tried. This give us insight as to why the constraints could not be satisfied.
Note: The sample data in these demos is very loosely based on SoCalCodeCamp San Diego from the summer of 2017. While some of the presenters names and presentations come roughly from the publicly available schedule, pretty much everything else has been fictionalized to make for a compelling demo, including the appearances by some Microsoft rock stars, and the "requests" of the various presenters.
If you have any questions about this code, or about how Hybrid AIs can be used to provide more information about the solutions to problems than strictly optimization or probabilistic models, please contact me @bsstahl.
Tags: ai algorithms code camp code sample coding-practices conference open source optimization presentation
Building AI Solutions with Google OR-Tools
Posted by bsstahl on 2017-09-28 and Filed Under: development
My presentation from the #NDCSydney conference has been published on YouTube.
We depend on Artificial Intelligences to solve many types of problems for us. Some of these problems have more than one possible solution. Handling those problems with more than one solution while building a modern AI system is something every developer will be asked to do over the course of his or her career. Figuring out the best way to utilize the capacity of a device or machine, finding the shortest path between two points, or determining the best way to schedule people or events are all problems where mathematical optimization techniques and tooling can be used to quickly and efficiently find solutions.
This session is a software developers introduction to using mathematical optimization in Artificial Intelligence. In it, we will explore some of the foundational techniques for solving these types of problems, and use the open-source Google OR-Tools to put them to work in our AI systems. Since this is a session for developers, we'll keep it in terms that work best for us. That is, we'll go heavy on the code and lighter on the math.
Tags: ai algorithms code sample community conference decision development presentation professional development speaking
A Developer’s Survey of AI Techniques
Posted by bsstahl on 2017-06-22 and Filed Under: event
The slide deck for my talk “A Developer’s Survey of AI Techniques” can be found here, while the demo code can be found on GitHub.
The talk explores some of the different techniques used to create Artificial Intelligences using the example of a Chutes & Ladders game. Various AIs are developed using different strategies for playing a variant of the game, using different techniques for deciding where on the game board to move.
If you would like me to deliver this talk, or any of my talks, at your User Group or Conference, please contact me.
Tags: ai code sample community decision development presentation professional development slides speaking user group
Microservices Presentation
Posted by bsstahl on 2017-05-06 and Filed Under: event
The slide deck for my presentation “Examples of Microservice Architectures” can be found here.
There isn't one clear answer to the question "what does a micro-service architecture look like?" so it can be very enlightening to see some existing implementations. In this presentation, we will look at 2 different applications that would not traditionally be thought of as candidates for a service-oriented approach. We'll look at how they were implemented and what benefits the micro-services architecture brought to the table for each application.
Tags: coding-practices community conference development presentation services soa microservices
Demo Code for Testing in Visual Studio 2017
Posted by bsstahl on 2017-03-16 and Filed Under: event
The demo code for my presentation on Testing in Visual Studio 2017 at the VS2017 Launch event can be found on GitHub. There are 2 branches to this repository, the Main branch which holds the completed demo, and the DemoStart branch which holds the starting point of the demonstration in case you would like to implement the sample yourself.
The demo shows how Microsoft Fakes (formerly Moles) can be used to create tests against code that does not implement a reusable interface. This can be done without having to resort to integration style tests or writing extra wrapper code just to implement an interface. During my launch presentation, I also use this code to demonstrate the use of Intellitest (formerly Pex) to generate exploratory tests.
Tags: abstraction code sample coding-practices community conference development di interface microsoft moles mstest pex phoenix presentation tdd testing unit testing visual studio
Is a Type an Implementation of an Interface?
Posted by bsstahl on 2016-11-17 and Filed Under: development
One of the techniques I recommend highly in my Simplify Your API talk is the use of extension methods to hide the complexity of lower-level API functionality. A good example of a place to use this methodology came-up last night in a great Reflection talk by Jeremy Clark (Twitter, Blog) at the NorthWest Valley .NET User Group.

Jeremy was demonstrating a method that would spin-through an assembly and load all classes within that assembly that implemented a particular interface. The syntax to do the checks on each type were just a bit more obtuse than Jeremy would have liked them to be. As we left that talk, I only half-jokingly told Jeremy that I was going to write him an extension method to make that activity simpler. Being a man of my word, I present the code below to do just that.
Tags: assembly api class code sample coding-practices community csharp development extension method framework generics interface presentation professional development reflection user group
Simplify Your API
Posted by bsstahl on 2015-10-12 and Filed Under: development
If you are building an API for other Developers to use, you will find out two things very quickly:
- Developers don't read documentation (you probably already know this).
- If your API depends on its documentation to get developers to understand and discover its features, it is likely that it will not be used.
Fortunately, there are some simple mechanisms for wrapping complex APIs and making their functionality both easy to use, and highly discoverable. An API that uses tools like IntelliSense in Visual Studio to make its features discoverable by the downstream developer is far more likely to be adopted then one that doesn't. In recent years, additions to the C# language have made creating a Domain Specific Language that uses a fluent syntax for nearly any API into a simple process.
Create the Context
The 1st step in simplifying any API is to provide a single starting point for the downstream developer to interact with. In most cases, the best practice is to use the façade pattern to define a context that holds our entity collections. Each collection of entities becomes a property on the context object. These properties all return an IQueryable<Entity>. For example, in the EnumerableStack demo solution on GitHub (https://github.com/bsstahl/SimpleAPI), I created an object Bss.EnumerableStack.Data.EnumerableStack to provide this functionality. It has two properties, Posts and Questions, each of which returns an IQueryable<Post>. It is these properties that will be used to access the data from our API.
The context object, on top of becoming the single point of entry for downstream developers, also hides any complexities in the construction logic of the underlying data source. That is, if there is any configuration or other setup required to access the upstream data provider (such as web service access or database connections), much of the complexity of that construction can be hidden from the API user. A good example of this can be seen in the FluentStack demo solution from the same GitHub repository. There, the Bss.FluentStack.Data.OData.FluentStack context object wraps the functionality of constructing the connection to the StackOverflow OData web service.
Extend Our Language
Now that we have data to access, it's time for us to extend our domain specific language to provide tools to make accessing this data simpler for the API caller. We can use Extension methods on IQueryable<Entity> to create custom filters for our data. By creating extension methods that accept IQueryable<Entity> as a parameter and return the same, we can create methods that can be chained together to form a fluent syntax that will perform complex filtering. For example, in the EnumerableStack solution , the Questions, WithAcceptedAnswer and TaggedWith methods found in the Bss.EnumerableStack.Data.Extensions module, can all be used to execute queries on the data exposed by the properties of our context object, as shown below:
var results = new EnumerableStack().Posts.WithAcceptedAnswer().TaggedWith("odata");
In this case, both the WithAcceptedAnswer and TaggedWith filters are applied to the data. The best part about these methods are that they are visible in Intellisense (once the namespace has been brought into scope with a Using statement) making the functionality easy to discover and use.
Another big advantage of creating these extension methods is that they can hide the complexity of the lower level API. Here, the WithAcceptedAnswer method is wrapping a where clause that filters for those posts that have an AcceptedAnswerId property that is non-null. It may not be obvious to a downstream API consumer that the definition of a post with an "accepted answer" is one where the AcceptedAnswerId has a value. Our API hides that implementation detail and allows the consumer to simply request what is needed. Similarly, the TaggedWith method hides the fact that the StackOverflow API stores tags in lower-case, within angle-brackets, and with all tags on a post joined into a single string. To search for tags, the consumer would need to know this, and take all appropriate actions when searching for a tag if we didn't hide that complexity in the TaggedWith method.
Simplify Query Predicates
A predicate is a function that accepts an entity as a parameter, and returns a boolean value. These functions are often used in the Where clause of a query to indicate which objects should be included in the result set. For example, in the query below
var results = new EnumerableStack().Posts.Where(p => p.Parent == null);
the function expression p => p.Parent == null is a predicate that returns true if the Parent property of the entity is null. For each entity passed to the function, the value of that property is tested, and if null, the entity is included in the results of the query. Here we are using a Lambda Expression to provide a delegate to our function. One of the coolest things about Linq is that we can now represent this expression in a variable of type Expression<Func<Entity, bool>>, that is, a Lambda expression of a function that takes an Entity and returns a boolean. This is pretty awesome because if we can store it in a variable, we can pass it around and enable extension methods like this one, as found in the Asked class of the Bss.EnumerableStack.Data library:
public static Expression<Func<Post, bool>> InLast(TimeSpan span)
{
return p => p.CreationDate > DateTime.UtcNow.Subtract(span);
}
This method accepts a TimeSpan object and returns the Lambda Expression type useable as a predicate. The input TimeSpan is subtracted from the current DateTime UTC value, and compared to the CreationDate property of a Post entity. If the creation date of the Post is later than 30-days prior to the current date, the function returns true. Since this InLast method is static on a class called Asked, we can use it like this:
var results = new EnumerableStack().Questions.Where(Asked.InLast(TimeSpan.FromDays(30));
Which will return questions that were asked in the last 30 days. This becomes even simpler to understand if we add a method extending Int called Days that returns a Timespan, like this:
public static TimeSpan Days(this int value)
{
return TimeSpan.FromDays(value);
}
allowing our expression to become:
var results = new EnumerableStack().Questions.Where(Asked.InLast(30.Days());
Walking through the Process
In my conference sessions, Simplify Your API: Creating Maintainable and Discoverable Code, I walk through this process on the FluentStack demo code. We take a query created against the StackOverflow OData API that starts off looking like this:
var questions = new StackOverflowService.Entities(new Uri(_serviceRoot))
.Posts.Where(p => p.Parent == null && p.AcceptedAnswerId != null
&& p.CreationDate > DateTime.UtcNow.Subtract(TimeSpan.FromDays(30))
&& p.Tags.Contains("<odata>"));
and convert it, one step at a time, to this:
var questions = new FluentStack().Questions.WithAcceptedAnswer()
.Where(Asked.InLast(30.Days)).TaggedWith("odata");
a query that is much simpler, easier to understand, easier to create and easier to maintain. The sample code on GitHub, referenced above, and available at https://github.com/bsstahl/SimpleAPI, contains the FluentStack.sln example which shows how to simplify an API created with an OData source. It also contains the EnumerableStack.sln project which walks through the same process on a purely enumerable data source, that is, an implementation that will work with any collection.
Sound Off
Have you used these tools to simplify an API for downstream programmers? Do you have other techniques that you use to do the same, similar, or additional things to make your APIs better? If so, send it to me @bsstahl and let's keep the conversation going.
Tags: api coding-practices code sample development generics presentation services skill speaking visual studio soa
Speaking Engagements for October 2015
Posted by bsstahl on 2015-09-30 and Filed Under: event
I am really looking forward to October because I have 3 awesome events that I’ll be speaking, and learning, at:
- The first event for the month is Code Camp NYC in Manhattan on October 10th. I have attending this event once before and loved it. I’m really looking forward to being there again.
- Next up is Atlanta Code Camp on October 24th. This will be my 1st time at this event, and my 1st time in Atlanta in many years. Hopefully, people will have some helpful suggestions for what to see and do when I am not at the Code Camp.
- Finally, I’ll be speaking at .NET Group – Southern Nevada’s .NET User Group in Las Vegas on October 29th. I’ve spoken in Las Vegas at the Code Camp there before, but have never had the privilege of attending their user group.
I have several other event possibilities in the works for November and beyond. I’ll announce them here periodically, but you can always see my schedule, as well as past events and the talks I am currently giving, using the “Speaking Engagements” link above.
Tags: code camp user group speaking presentation
SOA–Beyond the Buzzwords
Posted by bsstahl on 2014-06-28 and Filed Under: event development
For those who saw my code camp presentation, “SOA – Beyond the Buzzwords”, you can find the slide deck here.
There is much more to building a Service Oriented Architecture than just creating services. SOA services can be much more difficult to build, requiring more analysis and design work up-front than a non-service-enabled system or a system that relies on CRUD-style data services. In this session, we will look at real-world examples of SOAs, examining what a good SOA might look like, what conditions present a good opportunity to use a Service Oriented Architecture, and how we can make the process more agile. We will also look at some practical tips to help make your services more extensible and maintainable.
For those who haven’t yet seen this presentation, I will be giving this session at several other code camps and user groups around the US between now and the end of the year. Keep an eye on my Speaking Engagements page to know where and when I will be presenting.
Tags: soa services presentation slides code camp
Upcoming Presentations
Posted by bsstahl on 2013-02-06 and Filed Under: event
Here is an update on where and when I’ll be delivering presentations about software development in .NET over the next few months. I still have some availability left for the H1 2013 and H2 is effectively wide open. You can request me as a speaker by Contacting Me.
Southern Most User Group in Key West FL on February 7th - “Code Portability in .NET”
South Florida Code Camp in Ft. Lauderdale FL on February 9th - “Building a DSL Using an OData Source”
Desert Code Camp on April 20th in Gilbert AZ – “Building a DSL Using an OData Source”
Twin Cities Code Camp in Minneapolis MN on April 27th – “Code Portability in .NET”
SELA Dev Conference in Tel-Aviv Israel on May 5-9 – a full day seminar version of “.NET TDD Kickstart” as well as “Code Portability in .NET”
CodeStock in Knoxville TN on July 12-13 “Code Portability in .NET” (assuming the attendees vote for my session)
I hope to see you at one or more of these events.
Tags: presentation
South Florida Code Camp 2011
Posted by bsstahl on 2011-02-13 and Filed Under: event
For the 2nd time in the last 3 years, I was lucky enough to be able to attend the South Florida Code Camp. Code Camps are free, community driven technical conferences that take place during off-hours, usually weekends, so I try to make it to as many of them as I can. I have attended most of our local (Arizona) Desert Code Camp events, and will be speaking at the upcoming Desert Code Camp in April 2011, but I also try to attend other code camps whenever possible to get the broadest range of speakers and experiences. If you haven’t been to the local code camp in your area, you are missing out on a lot of great technical content and opportunities to chat with some awesome technologists.
I was able to attend a session in each of the 6 time slots for South Florida Code Camp 2011. I’d like to thank the speakers for all of the sessions as each was useful and worth attending:
- Zachary Gramana - Custom Tooling Using a VS Add-In and T4 Templates
- Colin Blakey – Building OData/WCF Data Service Providers
- Bayer White - Hosting Workflows as WCF Services Through Windows Server AppFabric
- Olec Sych – ASP.Net Dynamic Data
- Woody Pewitt – Technical Debt
- Chris Eargle – Code Like a Ninja: Enhance Productivity with Visual Studio and Just Code
Three of these sessions deserve some special mention. The OData/WCF session was probably the most useful from a technical perspective as the demos gave specific examples of exactly what I’d need to do to implement the technology. The session on technical debt was the most useful overall, Woody from ComponentOne, who is always a fantastic speaker, gave some specific tools to use to calculate the costs of carrying technical debt. In fact, I was fortunate enough to come-away from the raffle with a license to ComponentOne’s Studio Enterprise product. I’m especially looking forward to trying out the Silverlight controls. Finally, in the last session of the day, which turned into a free-form Visual Studio tips session, Chris did a great job of going with the flow and giving the already rowdy crowd, exactly what they wanted, including demos of some of the coolest features of Just Code.
All of the speakers and organizers did a fantastic job and it was a great event. Hopefully I will be able to make it back for next year’s event.
Tags: presentation code camp
Dev Ignite
Posted by bsstahl on 2009-11-09 and Filed Under: event
I just submitted my slide deck for my Developer Ignite #2 presentation on AZGiveCamp. I welcome any comments or suggestions.
Tags: ignite presentation slides
Developer Ignite Presentation - Slide Deck
Posted by bsstahl on 2009-07-23 and Filed Under: event
Here is the slide deck for my Developer Ignite presentation, "Simplicity Through Abstraction".
Tags: presentation ignite slides
Presentation Proposal - Developer Ignite Phoenix
Posted by bsstahl on 2009-06-26 and Filed Under: event
I just submitted the following proposal for a talk at Developer Ignite Phoenix which will be held July 22, 2009 at Gangplank in Chandler.
Simplicity Through Abstraction
The goal of this presentation is to explore, at a very high level, one methodology for software developers and architects to create software that is simple and maintainable, and thus has a lower total-cost-of-ownership (TCO).
Using abstraction via the provider pattern allows us to create software that is more testable, easier to map (find the piece of code that does X), and easier to understand at a component level. We can use providers to develop systems that have fewer bugs, and are more maintainable then tightly-coupled systems. As a result, these abstractions can significantly reduce costs for most systems, especially in the area of system maintenance.
I look forward to seeing you there.
