Tag: ddd
Introducing the Behavioral Layer
Posted by bsstahl on 2026-03-14 and Filed Under: development
Modern systems increasingly receive free‑text input, either from humans or from language models. These inputs can be ambiguous, incomplete, or phrased in ways the domain layer cannot act on directly. They are not the predictable, schema‑bound shapes that a traditional Anti‑Corruption Layer (ACL) is designed to translate. They require interpretation before any downstream component can reason about them. This is the realm of the Behavioral Layer.
What the Behavioral Layer Does
The Behavioral Layer is responsible for taking unstructured or highly variable inputs, such as those produced by a person or a language model, and producing a clean, normalized, and predictable shape that the rest of the system can trust. It is the architectural boundary where the system interprets intent before any downstream components have to reason about structure.
At a high level, the Behavioral Layer:
- Interprets what behavior the sender is attempting to invoke
- Normalizes inconsistently presented or incomplete inputs
- Detects structural and behavioral anomalies in the message
- Enriches the data with derived or inferred attributes
- Produces a stable output object that downstream components can rely on
The Behavioral Layer is defined by its responsibilities, not by any specific technology. You can implement it with deterministic rules, heuristics, or fine-tuned models. The architecture stays the same regardless of the tools you choose.
A Machine to Machine Example
To ground this in something concrete, consider a service that exposes an OpenAI‑compatible API for the purpose of intent determination and routing. This service is designed to accept natural language inside a structured request, classify the intent, and direct the call to the correct downstream system. Even in a machine to machine scenario, the request still contains unstructured text because the caller may be a human, a script, or an upstream LLM.
Here is an example of the kind of request this router might receive:
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are a plan selection assistant."
},
{
"role": "user",
"content": "please switch the user to the premium plan with the extras"
}
],
"user": "8821",
"source": "recommendation-service"
}
The outer structure is predictable, but the content is not. The router cannot forward this request until it determines what the caller is trying to do. The phrase premium plan with the extras is natural language, not an instruction the domain layer can act on. The router must identify the intent so it can send the request to the correct downstream service, which in this case is probably a plan or user service.
A Behavioral Layer implementation might produce something like this.
{
"userId": "8821",
"source": "recommendation-service",
"intent": "changePlan",
"confidence": "high",
"notes": [
{
"message": "The request refers to 'premium plan with the extras'."
}
]
}
The business logic within the router may take this input, determine which service is best suited to handle it, and route the original request to that service. The Behavioral Layer has taken a natural language request and expressed the sender's behavior in a structured form. It has identified what the caller is trying to do, surfaced any uncertainty, and produced a stable intent that the rest of the system can trust. Nothing about this output depends on domain rules or specific plan identifiers. The Behavioral Layer simply interprets the behavior contained in the text and turns it into a predictable shape that downstream components can build on. It has NOT concerned itself with mapping to the domain language, since this layer is not responsible for that. If additional mapping is required into the language of the domain, an anti-corruption or other mapping layer should be used to maintain the separation of concerns.
How It Works
The Behavioral Layer sits between the raw input and the ACL or domain layer. It receives whatever the outside world provides and applies a series of transformations that gradually reduce uncertainty.
A typical flow looks like this:
- Receive the raw input exactly as it arrived.
- Perform structural checks to understand what type of thing it might be.
- Apply behavioral checks to understand what the sender is trying to accomplish.
- Normalize fields, resolve aliases, and fill in missing but inferable information.
- Detect suspicious or incoherent combinations of attributes.
- Produce a Behavioral Output object that expresses the input in a clean, predictable shape.
Neither the ACL nor the domain layer ever sees the raw input. They only see the Behavioral Output, which keeps both layers small, deterministic, and easy to reason about.
How It Differs From a Traditional ACL
A traditional Anti-Corruption Layer protects the domain from other systems. It translates external models into internal ones, isolates upstream changes, and ensures that foreign concepts do not leak into the domain.
The Behavioral Layer protects the domain from ambiguous inputs. It resolves uncertainty, interprets intent, and produces a coherent behavioral shape before any translation or invariant enforcement occurs.
You can think of the responsibilities like this:
- Behavioral Layer: coherence
- ACL: translation and isolation
- Domain: correctness and invariants
The Behavioral Layer is not a variant of an ACL and not a replacement for one. It is a complementary layer that handles a different class of problems. The ACL expects structured, well-formed inputs. The Behavioral Layer exists precisely because real-world inputs often are not fully structured.
If you are building a "modular monolith", where all functionality is crammed into a single deployment unit, you can manage both sets of fuctionality (translation and behavioral) in a single place, however you probably don't want to mash them together so they can be more completely separated if it becomes appropriate.
Why is it Called the Behavioral Layer
The name comes from the nature of the inputs it handles. At this boundary, the system is not reacting to a schema. It is reacting to behavior. A person behaves unpredictably when typing a request. A language model behaves unpredictably when generating a response. A third-party system behaves unpredictably when sending a payload that almost matches your expectations.
The Behavioral Layer exists to interpret that behavior.
It focuses on what the sender is trying to do, not how the sender structures the data. It resolves intent, ambiguity, and variability before any translation or invariant enforcement occurs. The name fits because it describes the responsibility: making sense of behavior so the rest of the system does not have to.
Implementation Options
You can build a Behavioral Layer using several strategies, depending on your constraints and the variability of your inputs.
Deterministic Rules
This is the simplest approach. You define explicit rules for classification, normalization, and enrichment. It works well when the input space is small and predictable. It may work in more complex spaces with the help of a rules-engine or similar logic framework.
- Pros: transparent, easy to test, easy to reason about
- Cons: brittle when inputs vary widely or evolve over time
Heuristics and Pattern Matching
This approach uses scoring, thresholds, and pattern recognition to handle more variability without committing to full machine learning.
- Pros: flexible, adaptable, still deterministic
- Cons: harder to maintain, can drift into complexity
Fine-Tuned Language Models
A small, purpose-built model can classify intent, normalize fields, and map ambiguous inputs into structured forms with far more reliability than hand-written rules.
- Pros: handles real-world variability, reduces rule complexity, improves resilience
- Cons: requires training data, monitoring, and versioning discipline
The Behavioral Layer does not require a language model. LLMs and other probabilistic models simply make it easier to implement the layer when the input space becomes too variable for deterministic approaches.
Use Case 2: Human Input
The earlier example showed how a machine to machine request can contain natural language inside a structured API call. The same problem appears when a human interacts with the system. A user may type a request in their own words, combine multiple actions in a single message, or omit details that downstream components require. The Behavioral Layer handles this variability by interpreting what the user is trying to do and expressing that behavior in a predictable shape.
Imagine a system that receives inbound support messages from users. The messages can arrive through email, chat, or a mobile app. Users may not follow a template. They may combine multiple requests in one message. They may use synonyms, shorthand, or incomplete phrasing.
A raw message might look like:
"Hey, can you change my home address to the new one on file and also switch my plan to the premium thing"
The Behavioral Layer would:
- Translate the sender information into discrete fields
- Detect that the message contains two distinct intents
- Normalize "premium thing" into a known plan identifier
- Extract the address reference and map it to the stored address record
As shown below, this layer might also interpret normalized data that it has access to. For example, if the list of plans is accessible to the Behavioral Layer, it might add an indication that "premium thing" is not an exact match to a known plan. This is one of the places however where some judgement is required because, depending on the circumstances, that functionality might be better left to an ACL or the Domain.
The Behavioral layer would consider the input above along with the email metadata and might produce an output object similar to the one shown below:
{
userIds: [
"email": "sampleuser@cognitiveinheritance.com",
"eMailName": "Sample User",
"dkimDomain": "cognitiveinheritance.com",
"spfDomain": "sendgrid.net"
],
intents: [
{ type: "updateAddress", addressId: "home" },
{ type: "changePlan", planId: "premiumPlan" }
],
confidence: "high",
anomalies: [
{ "fieldName": "planId", "value": "'premium thing' not an exact match to plan name" }
]
}
The ACL or domain layer now has a clean, predictable structure to work with. It does not need to parse free‑form text or guess what the user meant. The Behavioral Layer has already done that work.
What Comes Next
This post introduces the Behavioral Layer as an architectural concept and distinguishes it from a traditional ACL. In the next article, we will look at how fine‑tuned language models can assist with the transformations inside the layer. We will walk through how to build small, purpose‑built models using Microsoft Foundry, how to train them on your domain, and how to integrate them into a reliability‑first architecture.
Tags: architecture ddd responsibility pattern
Objects with the Same Name in Different Bounded Contexts
Posted by bsstahl on 2023-10-29 and Filed Under: development
Imagine you're working with a Flight entity within an airline management system. This object exists in at least two (probably more) distinct execution spaces or 'bounded contexts': the 'passenger pre-purchase' context, handled by the sales service, and the 'gate agent' context, managed by the Gate service.
In the 'passenger pre-purchase' context, the 'Flight' object might encapsulate attributes like ticket price and seat availability and have behaviors such as 'purchase'. In contrast, the 'gate agent' context might focus on details like gate number and boarding status, and have behaviors like 'check-in crew member' and 'check-in passenger'.
Some questions often arise in this situation: Should we create a special translation between the flight entities in these two contexts? Should we include the 'Flight' object in a Shared Kernel to avoid duplication, adhering to the DRY (Don't Repeat Yourself) principle?
My default stance is to treat objects with the same name in different bounded contexts as distinct entities. I advocate for each context to have the autonomy to define and operate on its own objects, without the need for translation or linking. This approach aligns with the principle of low coupling, which suggests that components should be as independent as possible.
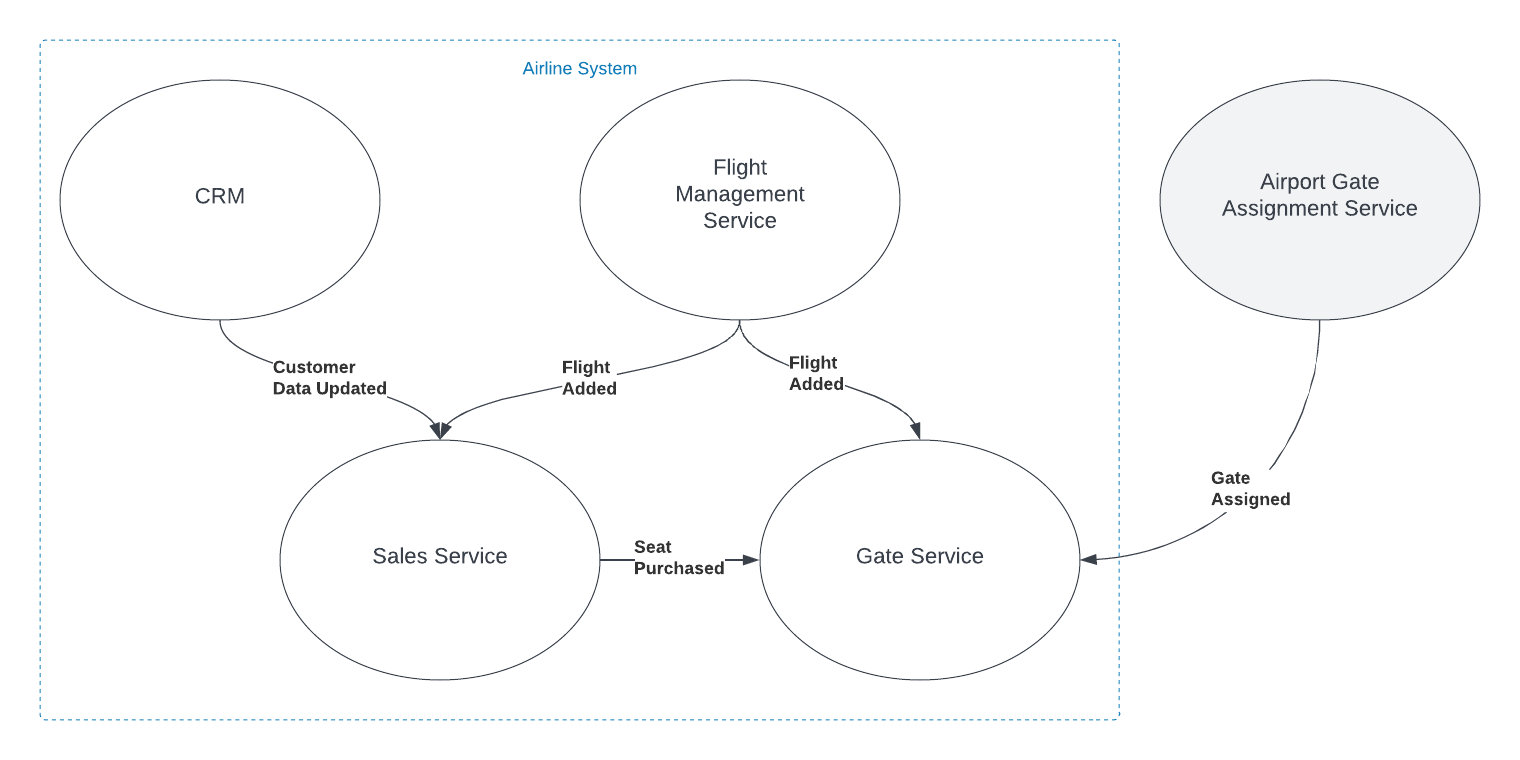
In the simplified example shown in the graphic, both the Sales and Gate services need to know when a new flight is created so they can start capturing relevant information about that flight. There is nothing special about the relationship however. The fact that the object has the same name, and in some ways represents an equivalent concept, is immaterial to those subsystems. The domain events are captured and acted on in the same way as they would be if the object did not have the same name.
You can think about it as analogous to a relational database where there are two tables that have columns with the same names. The two columns may represent the same or similar concepts, but unless there are referential integrity rules in place to force them to be the same value, they are actually distinct and should be treated as such.
I do recognize that there are likely to be situations where a Shared Kernel can be beneficial. If the 'Flight' object has common attributes and behaviors that are stable and unlikely to change, including it in the Shared Kernel could reduce duplication without increasing coupling to an unnaceptable degree, especially if there is only a single team developing and maintaining both contexts. I have found however, that this is rarely the case, especially since, in many large and/or growing organizations, team construction and application ownership can easily change. Managing shared entities across multiple teams usually ends up with one of the teams having to wait for the other, hurting agility. I have found it very rare in my experience that the added complexity of an object in the Shared Kernel is worth the little bit of duplicated code that is removed, when that object is not viewed identically across the entire domain.
Ultimately, the decision to link objects across bounded contexts or include them in a Shared Kernel should be based on a deep understanding of the domain and the specific requirements and constraints of the project. If it isn't clear that an entity is seen identically across the entirety of a domain, distinct views of that object should be represented separately inside their appropriate bounded contexts. If you are struggling with this type of question, I reccommend Event Storming to help gain the needed understanding of the domain.
Tags: development principle ddd
Event Storming
Posted by bsstahl on 2021-09-21 and Filed Under: development
What is Event Storming?
Event storming is a process for building a model of a problem domain by analyzing the domain from a business perspective. The results of an Event Storming session include a logical model of the domain, as seen by the business owners, that is extremely useful to engineers in defining software systems for that domain. Event Storming follows a four-step process to produce a model of the system that is based on Domain Events, historical facts about the business process that are relevant to the business owners.
The process occurs on a whiteboard surface, ideally in-person but often virtually. Sticky-notes of various colors are used to represent elements of the domain and the model is built-up by everyone on the team, regardless of their role. The exercise starts as a brainstorming session of a sort, then evolves until it results in a model of the business process.
The Goals of Event Storming
Produce a model of the domain that is valuable to both the business owners and the engineers who are building software systems for that domain.
Document a Ubiquitous Language for the domain that represents the shared set of terms used by everyone working in that domain.
Level everyone in the domain on the same understanding of what problems are being solved so that all players have a strong working background.
Important Terminology
Note: The items below represent the different elements of the model we wish to produce. Each type of item is represented by a different color of sticky-note on our design surface. Terms not color-coded exist in the context of Domain Driven Design and may be used during the session, but will not be modeled on the board.
Aggregate
An aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items. These objects will likely be created from distinct classes when built within the context of a software system, but it is useful to treat them as a single aggregate for the purposes of modeling the domain. That is, it is simpler to think about an Order with all of its line-items as a single unit within the model. Additionally, some objects will be able to be viewed from multiple perspectives. If we model a User which contains a collection of Roles, we could also see a Role as having a collection of users. The User and Role objects are each separate aggregates and can be modeled separately depending on the context, even though they represent the same relationship and a collection of one object likely exists on the other. The primary object within each Aggregate is known as the Aggregate Root which is used to describe the aggregate as a whole.
Bounded Context
A Bounded Context is a logical area within a system where business processes are implemented, a ubiquitous language is applied, and certain terms make very clear and specific sense. A term can have exactly one meaning within a bounded context, a meaning which may not be exactly the same as that same term in another bounded context. As an example, let's look at a Customer object. Bounded Contexts that exist in a state after a user has logged-in to the system might have a User object or UserId property associated with it. Meanwhile, this User object or UserId may not exist in a Bounded Context that exists purely pre-login, or where login status has no bearing on the functionality.
Business Process (dark purple stickies)
The business rules and logic required to handle a Command or a Domain Event. A business process may create one or more domain events, or may reject the command outright.
Command (light blue stickies)
An instruction submitted by a user, usually through a view, that typically results in the creation of one or more Domain Events. Commands may be rejected by the Business Processes that handle them, perhaps due to permissions or data validation issues. If a command is rejected, it may or may not result in one or more domain events representing the submission and/or rejection of that command.
Domain Event (orange stickies)
Domain Events are the keys to Event Storming. A Domain Event is something that happened in the domain that is relevant to the business. Events are always written in the past tense since they represent historical facts that cannot change. Examples of domain events include “vehicle locked” and “delivery scheduled.” Though the term event is somewhat overloaded, these Domain Events should not be conflated with the messages that can be used to represent them. While many Domain Events will eventually be represented by event messages of some form, many will not. Event Storming is an implementation agnostic process, thus there is no prescription as to how events are communicated. Domain events, in this context, exist entirely as historical facts and nothing more.
External System (light purple stickies)
A third-party service provider such as a payment gateway or shipping company. These services may utilize View Models within our system and may create Domain Events that trigger Business Processes.
Questions or Risks (pink or red stickies)
We use pink stickies to identify items that are unclear, overly complex or have unanswered questions or risks. Callout concerns with these pink stickies liberally whenever there is something that should be known about an item or area of the model. Sections of the model where there are a lot of pink sticky notes may require additional attention.
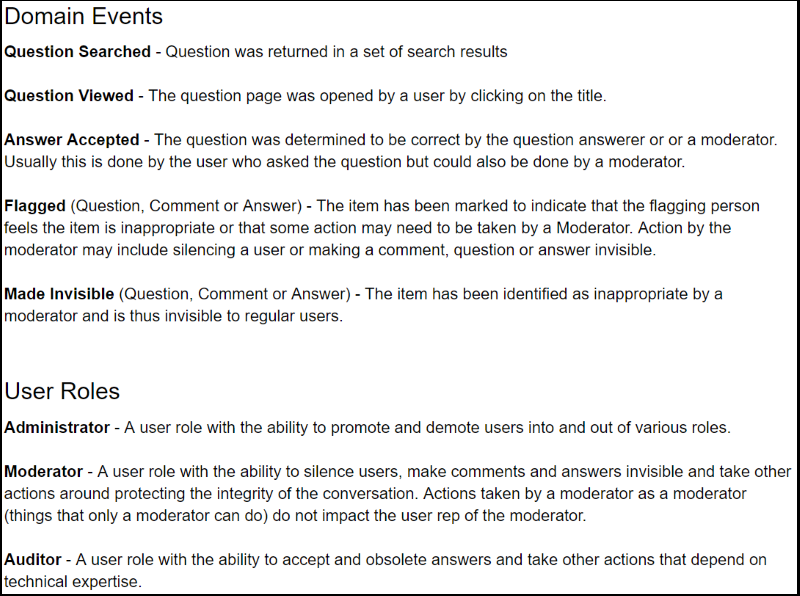
Ubiquitous Language
A set of terms describing the domain that are meaningful to the business team. These are the terms that are used by all domain team members to identify and communicate about activities of the system. A sample excerpted from a Ubiquitous Language document is shown below.
User/Actor (yellow stickies)
A person who interacts with the system. These interactions will usually take the form of executing a Command, typically through a view populated by a View Model.
View / Read Model (light green stickies)
A presentation of data that Users, Business Processes, and External Systems interact with to carry out a task in the system. As an example, an external system may call a REST service within the domain that returns data that we represent with a View Model.
The Event Storming Process
Each step builds on the previous steps to result in a cohesive picture of the domain from a business perspective. This view of the system has proven to be extremely useful to engineers in defining software systems for that domain.
1 - Collect Domain Events
The first step in Event Storming is to brainstorm the Domain Events that occur during the course of the business process. These events should be described on orange sticky notes using verbs in the past-tense. Each sticky should represent a single event and should be placed on the modeling surface in roughly chronological order. Since this is brainstorming, we should limit the amount of time we spend discussing and refining each event. There will be more time for that in step 2. However, we do want to have enough discussion to trigger thoughts on additional events which often result from these conversations.
Any events where there are unresolved questions or concerns should be marked with a pink sticky note indicating the question or risk. In this first step we should make liberal use of these stickies.
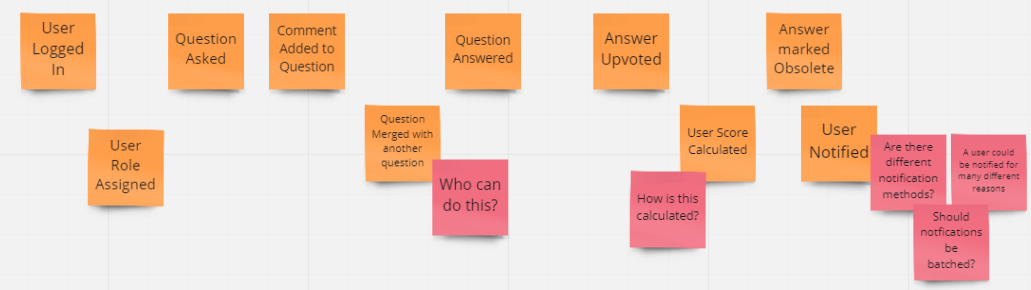
2 - Refine Domain Events
Once we have thrown all of the events we can think of on the board, we can start to refine those events. In step 1 we were brainstorming so multiple side-conversations may have been occurring at various times. In step 2 we want to bring the entire team together in a single conversation about each event. This is where we drill-in to the details of the events, and modify our model as appropriate.
We begin by walking through the timeline, usually from left to right, but jumping around as needed to best navigate the domain. Each event should be discussed with all participants to be certain that the entire team understands the details of the event. Other things to discuss include whether or not the event is in the proper place on the timeline, if there are any additional events that may be related to the one being discussed, if any duplicate events should be combined, if any of the questions or risks identified in the pink stickies can be resolved, and if there are additional questions or concerns that should be called-out using pink stickies.
Finally, for each event, be certain that any important terms are documented in the Ubiquitous Language document and that we are not using synonyms of the documented terms to describe our events. We always want to use the correct terminology to describe all aspects of our domain.
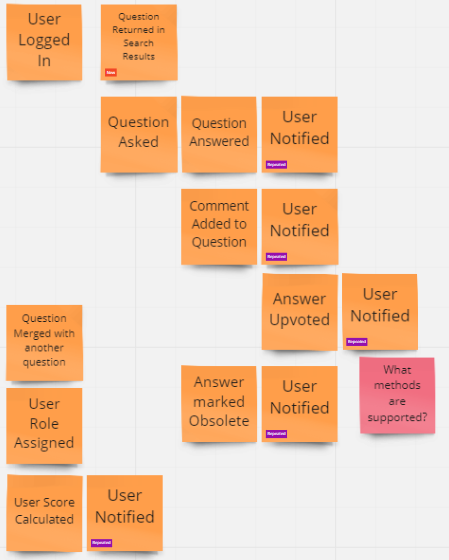
3 - Track Causes
In step 3, things start to get really interesting. The goal of this step is to determine the causes of each of the Domain Events. There are three causes of domain events: User actions, Business Processes, and External Systems. For each event we need to identify the interactions surrounding it, including what triggers it, and what downstream events it may cause. This step, once completed, results in a model that looks like a series of flows.
User Actions
Users typically trigger events via View Models and Commands. A view model may be displayed to the user from which they issue a command to take an action. This command may directly result in a Domain Event, but is more likely to be consumed by a Business Process which may validate the command before either rejecting it or executing logic that results in a Domain Event.
Business Processes
Business Processes often produce one or more events during the execution of their logic. An example might be that when a question is answered by a user in a StackOverflow type Q & A domain, it results in a “Question Answered” event. This event may be consumed by a business process to notify subscribed users resulting in one or more “User Notified” events. Business Processes often make use of Read Models to provide additional information as to the state of the system.
External Systems
External Systems are business processes that exist outside of the domain, and as such, have a smaller surface with which to interact with our systems. These processes may utilize Read Models from within our domain to gather information and are usually modeled as creating Domain Events to interact with the system. These interactions are typically modeled as Domain Events because most external system events are seen as important historical facts to our business. After all, if they weren’t important to our business domain experts, why would our systems care about them at all? This is not a hard and fast rule however and your domain may differ. It is conceivable that external logic could issue Commands to internal systems, though it seems more reasonable that those would be viewed as Domain Events.
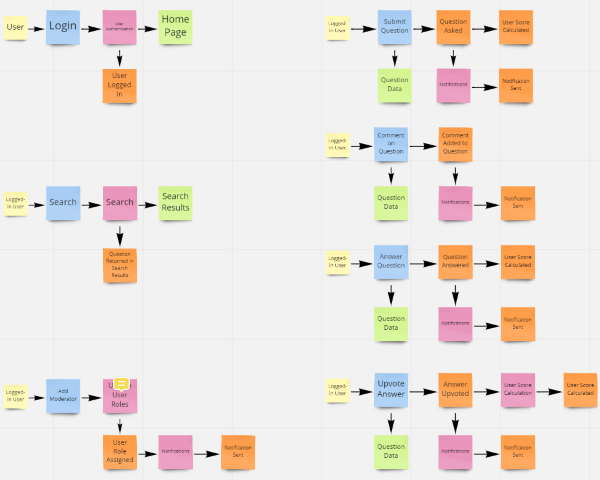
4 - Aggregation (Software Modeling)
The final step is all about grouping our new logic flows around the Aggregates they act upon and describing the communications between these newly identified sub-domains.
As you recall, an Aggregate is an object graph treated as a single object and identified by the Aggregate Root. In this step we identify the aggregates in our system, and then group each of the flows from step 3 by the Aggregate they act upon. At the same time, we can draw lines between the groups to identify the communications across these boundaries. This will result in the final model of this process, a set of flows grouped by their Aggregate into subdomains that can often be viewed as a good proxy for a microservice.
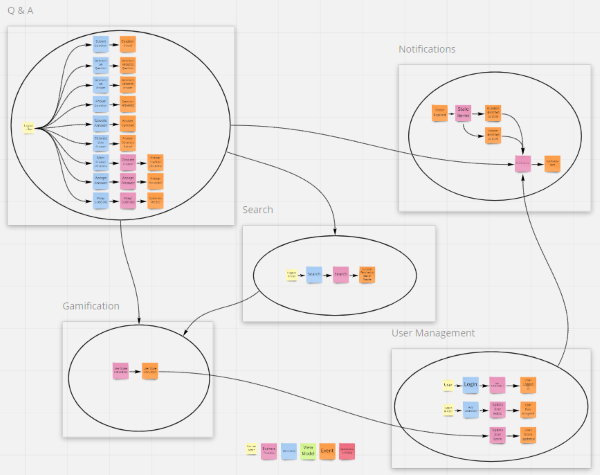
Additional Resources
- Intro to Event Storming - Lightning Talk Video
- Event Storming Presentation - Slide Deck
- Alberto Brandolini - Creator of Event Storming - On Why it Should be Done In-Person
- Adam Dymitruk on Event Modeling - a similar (more expansive) system
Conclusion
The practice of Event Storming offers a dynamic and inclusive approach to understanding and modeling business domains, bridging the gap between technical and non-technical stakeholders. By fostering collaboration, promoting a shared language, and visualizing the flow of Domain Events, teams can unlock a deeper comprehension of the business processes at hand. This method not only streamlines the development process but also ensures that the resulting software systems are precisely aligned with business objectives. As we've seen, Event Storming stands out as an invaluable tool in the arsenal of modern software development practices, embodying principles of agility, domain-driven design, and team cohesion to tackle complex domain problems effectively.
