Tag: reliability
Consider Quality Before Cost in Application Development
Posted by bsstahl on 2023-08-04 and Filed Under: development
Assessing the costs associated with using a specific tool is usually more straightforward than evaluating the less tangible costs related to an application's life-cycle, such as those tied to quality. This can result in an excessive focus on cost optimization, potentially overshadowing vital factors like reliability and maintainability.
As an example, consider a solution that uses a Cosmos DB instance. It is easy to determine how much it costs to use that resource, since the Azure Portal gives us good estimates up-front, and insights as we go. It is much more difficult to determine how much it would cost to build the same functionality without the use of that Cosmos DB instance, and what the scalability and maintainability impacts of that decision would be.
In this article, we will consider a set of high-level guidelines that can help you identify when to consider costs during the development process. By following these guidelines, you can make it more likely that your dev team accurately prioritizes all aspects of the application without falling into the trap of over-valuing easily measurable costs.
1. Focus on Quality First
As a developer, your primary objective should be to create applications that meet the customers needs with the desired performance, reliability, scalability, and maintainability characteristics. If we can meet a user need using a pre-packaged solution such as Cosmos DB or MongoDB, we should generally do so. While there are some appropriate considerations regarding cost here, the primary focus of the development team should be on quality.
Using Cosmos DB as an example, we can leverage its global distribution, low-latency, and high-throughput capabilities to build applications that cater to a wide range of user needs. If Cosmos DB solves the current problem effectively, we probably shouldn't even consider building without it or an equivalent tool, simply for cost savings. An additional part of that calculus, whether or not we consider the use of that tool a best-practice in our organization, falls under item #2 below.
2. Employ Best Practices and Expert Advice
During the development of an application, it's essential to follow best practices and consult experts to identify areas for improvement or cost-effectiveness without compromising quality. Since most problems fall into a type that has already been solved many times, the ideal circumstance is that there is already a best-practice for solving problems of the type you are currently facing. If your organization has these best-practices or best-of-breed tools identified, there is usually no need to break-out of that box.
In the context of Cosmos DB, you can refer to Microsoft's performance and optimization guidelines or consult with your own DBAs to ensure efficient partitioning, indexing, and query optimization. For instance, you can seek advice on choosing the appropriate partition key to ensure even data distribution and avoid hot-spots. Additionally, you can discuss the optimal indexing policy to balance the trade-off between query performance and indexing cost, and define the best time-to-live (TTL) for data elements that balance the need for historical data against query costs. If you are seeing an uneven distribution of data leading to higher consumption of RU/s, you can look at adjusting the partition key. If you need to query data in several different ways, you might consider using the Materialized View pattern to make the same data queryable using different partitioning strategies. All of these changes however have their own implementation costs, and potentially other costs, that should be considered.
3. Establish Cost Thresholds
Defining acceptable cost limits for different aspects of your application ensures that costs don't spiral out of control while maintaining focus on quality. In the case of Cosmos DB, you can set cost thresholds for throughput (RU/s), storage, and data transfer. For instance, you can define a maximum monthly budget for provisioned throughput based on the expected workload and adjust it as needed. This can help you monitor and control costs without affecting the application's performance. You can also setup alerts to notify you when the costs exceed the defined thresholds, giving you an opportunity to investigate and take corrective action.
Limits can be defined similarly to the way any other SLA is defined, generally by looking at existing systems and determining what normal looks like. This mechanism has the added benefit of treating costs in the same way as other metrics, making it no more or less important than throughput, latency, or uptime.
4. Integrate Cost Checks into Code Reviews and Monitoring
A common strategy for managing costs is to introduce another ceremony specifically related to spend, such as a periodic cost review. Instead of creating another mandated set of meetings that tend to shift the focus away from quality, consider incorporating cost-related checks into your existing code review and monitoring processes, so that cost becomes just one term in the overall equation:
- Code review integration: During code review sessions, include cost-related best practices along with other quality checks. Encourage developers to highlight any potential cost inefficiencies or violations of best practices that may impact the application's costs in the same way as they highlight other risk factors. Look for circumstances where the use of resources is unusual or wasteful.
- Utilize tools for cost analysis: Leverage tools and extensions that can help you analyze and estimate costs within your development environment. For example, you can use Azure Cost Management tools to gain insights into your Cosmos DB usage patterns and costs. Integrating these tools into your development process can help developers become more aware of the cost implications of their code changes, and act in a similar manner to quality analysis tools, making them just another piece of the overall puzzle, instead of a special-case for costs.
- Include cost-related SLOs: As part of your performance monitoring, include cost-related SLIs and SLOs, such as cost per request or cost per user, alongside other important metrics like throughput and latency. This will help you keep an eye on costs without overemphasizing them and ensure they are considered alongside other crucial aspects of your application.
5. Optimize Only When Necessary
If cost inefficiencies are identified during code reviews or monitoring, assess the trade-offs and determine if optimization is necessary without compromising the application's quality. If cost targets are being exceeded by a small amount, and are not climbing rapidly, it may be much cheaper to simply adjust the target. If target costs are being exceeded by an order-of-magnitude, or if they are rising rapidly, that's when it probably makes sense to address the issues. There may be other circumstances where it is apporpriate to prioritize these types of costs, but always be aware that there are costs to making these changes too, and they may not be as obvious as those that are easily measured.
Conclusion
Balancing quality and cost in application development is crucial for building successful applications. By focusing on quality first, employing best practices, establishing cost thresholds, and integrating cost checks into your existing code review and monitoring processes, you can create an environment that considers all costs of application development, without overemphasizing those that are easy to measure.
Tags: architecture coding-practices reliability
Microservices: Size Doesn't Matter, Reliability Does
Posted by bsstahl on 2023-02-20 and Filed Under: development
There are conflicting opinions among architects about how many microservices a distributed system should have, and the size of those services. Some may say that a particular design has too many microservices, and that it should be consolidated into fewer, larger services to reduce deployment and operational complexity. Others may say that the same design doesn't have enough microservices, and that it should be broken-down into smaller, more granular services to reduce code complexity and improve team agility. Aside from the always true and rarely helpful "it depends...", is there good guidance on the subject?
The truth is, the number and size of microservices is not a measure of quality or performance unto itself, it is a design decision based on one primary characteristic, Reliability. As such, there is a simple rule guiding the creation of services, but it isn't based on the size or quantity of services. The rule is based entirely on how much work a service does.
After security, reliability is the most important attribute of any system, because it affects the satisfaction of both the users and developers, as well as the productivity and agility of the development and support teams. A reliable system has the following characteristics:
- It performs its duties as expected
- It has minimal failures where it has to report to the user that it is unable to perform its duties
- It has minimal downtime when it cannot be reached and opportunities may be lost
- It recovers itself automatically when outages do occur, without data loss
Having reliable systems means that your support engineers won't be constantly woken-up in the middle of the night to deal with outages, and your customers will remain satisfied with the quality of the product.
How do we build reliable systems with microservices?
The key to building reliable systems using microservices is to follow one simple rule: avoid dual-writes. A dual-write is when a service makes more than one change to system state within an execution context. Dual-writes are the enemy of reliability, because they create the risk of inconsistency, data loss, and data corruption.
For example, a web API that updates a database and sends a message to a queue during the execution of a single web request is performing a dual-write since it is making two different changes to the state of the system, and both of the changes are expected to occur reliably. If one of the writes succeeds and the other fails, the system state becomes out of sync and system behavior becomes unpredictable. The errors created when these types of failures occur are often hard to find and remediate because they can present very differently depending on the part of the process being executed when the failure happened.
The best-practice is to allow microservices to perform idempotent operations like database reads as often as they need, but to only write data once. An atomic update to a database is an example of such a write, regardless of how many tables or collections are updated during that process. In this way, we can keep the state of each service consistent, and the system behavior deterministic. If the process fails even part-way through, we know how to recover, and can often do it automatically.
Building this type of system does require a change in how we design our services. In the past, it was very common for us to make multiple changes to a system's state, especially inside a monolithic application. To remain reliable, we need to leverage tools like Change Data Capture (CDC), which is available in most modern database systems, or the Transactional Outbox Pattern so that we can write our data once, and have that update trigger other activities downstream.
Since microservices are sized to avoid dual-writes, the number of microservices in a system is determined by what they do and how they interact. The number of microservices is not a fixed or arbitrary number, but a result of the system design and the business needs. By following the rule of avoiding dual-writes, you can size your microservices appropriately, and achieve a system that is scalable and adaptable, but most of all, reliable. Of course, this practice alone will not guarantee the reliability of your systems, but it will make reliability possible, and is the best guideline I've found for sizing microservices.
For more detail on how to avoid the Dual-Writes Anti-Pattern, please see my article from December 2022 on The Execution Context.
Tags: architecture coding-practices event-driven microservices reliability soa
Microservices - Not Just About Scalability
Posted by bsstahl on 2023-01-30 and Filed Under: development
Scalability is an important feature of microservices and event-driven architectures, however it is only one of the many benefits these types of architectures provide. Event-driven designs create systems with high availability and fault tolerance, as well as improvements for the development teams such as flexibility in technology choices and the ability to subdivide tasks better. These features can help make systems more robust and reliable, and have a great impact on development team satisfaction. It is important to consider these types of architectures not just for systems that need to scale to a high degree, but for any system where reliability or complexity are a concern.
The reliability of microservices come from the fact that they break-down monolithic applications into smaller, independently deployable services. When implemented properly this approach allows for the isolation of failures, where the impact of a failure in one service can be limited to that service and its consumers, rather than cascading throughout the entire system. Additionally, microservice architectures enable much easier rollbacks, where if a new service version has a bug, it can be rolled back to a previous version without affecting other services. Event-driven approaches also decouple services by communicating through events rather than direct calls, making it easier to change or replace them without affecting other services. Perhaps most importantly, microservice architectures help reliability by avoiding dual-writes. Ensuring that our services make at most one state change per execution context allows us to avoid the very painful inconsistencies that can occur when data is written to multiple locations simultaneously and these updates are only partially successful.
When asynchronous eventing is used rather than request-response messages, these systems are further decoupled in time, improving fault-tolerance and allowing the systems to self-heal from failures in downstream dependencies. Microservices also enable fault-tolerance in our services by making it possible for some of our services to be idempotent or even fully stateless. Idempotent services can be called repeatedly without additional side-effects, making it easy to recover from failures that occur during our processes.
Finally, microservices improve the development and support process by enabling modularity and allowing each team to use the tools and technologies they prefer. Teams can work on smaller, independent parts of the system, reducing coordination overhead and enabling faster time-to-market for new features and improvements. Each service can be deployed and managed separately, making it easier to manage resource usage and address problems as they arise. These architectures provide greater flexibility and agility, allowing teams to focus on delivering value to the business without being bogged down by the constraints of a monolithic architecture.
While it is true that most systems won't ever need to scale to the point that they require a microservices architecture, many of these same systems do need the reliability and self-healing capabilities modern architectures provide. Additionally, everyone wants to work on a development team that is efficient, accomplishes their goals, and doesn't constantly force them to wake up in the middle of the night to handle support issues.
If you have avoided using event-driven microservices because scalability isn't one of the key features of your application, I encourage you to explore the many other benefits of these architectures.
Tags: architecture coding-practices event-driven microservices reliability soa
You Got Your Policy in my Redis
Posted by bsstahl on 2021-04-22 and Filed Under: development
Using a distributed cache such as Redis is a proven method of improving the performance and reliability of our applications. As with any tool, use in accordance with best practices will help to reduce support time and outages, and give our customers the best possible experience.
As much as we’d like to believe that our cloud services are highly available and reliable, the fact is that no matter how much effort goes into their resilience, we will never get 100% availability from them. Even if it is just due to random Internet routing issues, we must take measures to protect our applications, our customers, and our support personnel, from these inevitable hiccups. There are a number of patterns we can use to make our cache access more resilient, and therefore less susceptible to these outages. There are also libraries we can use to implement these patterns, allowing us to declare policies for these patterns, and implement and compose them with ease.
These concepts are useful in all tool chains, with or without a policy library, and policy libraries are available for many common development languages. However, this article will focus on using the Polly library in C# for implementation. That said, I will attempt to describe the concepts, as much as possible, in terms that are accessible to developers using all tool chains. I have also used the Polly library generically. That is, any calls that result in data being returned could be used in place of the caching operations described here. In addition, for clients that use Microsoft’s IDisributedCache abstraction, there is a caching specific package, Polly.Caching.Distributed, that does all of these same things, but with a simplified syntax for caching operations.
Basic Cache-Retrieval
The most straightforward use-case for a caching client is to have the cache pre-populated by some other means so that the client only has to retrieve required values. In this situation, either the value is successfully retrieved from the cache, or some error condition occurs (perhaps a null returned or an Exception thrown). This usage, as described, is very simple, but can still provide a lot of value for our applications. Having low-latency access to data across multiple instances of our application can certainly improve the performance of our apps, but can also improve their reliability, depending on the original data source. We can even use the cache as a means for our services to own-their-own-data, assuming we take any long-term persistence needs into account.
It goes without saying however that this simple implementation doesn’t handle every circumstance on its own. Many situations exist where the data cannot all be stored in the cache. Even if the cache can be fully populated, there are circumstances, depending on the configuration, where values may need to be evicted. This pattern also requires each client to handle cache errors and misses on their own, and provides no short-circuiting of the cache during outage periods. In many cases, these types of situations are handled, often very differently, by the consuming clients. Fortunately, tools exist for many languages that allow us to avoid repeating the code to manage these situations by defining policies to handle them.
Using a Circuit-Breaker Policy
It is an unfortunate fact of distributed system development that our dependencies will be unavailable at times. Regardless of how reliable our networks and cloud dependencies are, we have to act like they will be unavailable, because sometimes they will be. One of the ways we have to protect our applications from these kinds of failures is to use a circuit-breaker.
A circuit-breaker allows us to specify conditions where the cache is not accessed by our client, but instead the cache-call fails immediately. This may seem counterintuitive, but in circumstances where we are likely in the middle of an outage, skipping the call to the cache allows us to fail quickly. This quick-failure protects the users from long timeout waits, and reduces the number of network calls in-process. Keeping the number of network calls low reduces the risk of having our pods recycled due to port-exhaustion problems, and allows our systems to recover from these outages gracefully.
To use a Polly circuit-breaker in C#, we first define the policy, then execute our request against the policy. For example, a sample policy to open the circuit-breaker under the configured conditions and log the change of state is shown below.

This code uses the static logger to log the state changes and has members (_circuitBreakerFailureThresholdPercentage, _circuitBreakerSamplingDuration, etc...) for the configuration values that specify the failure conditions. For example, we could configure this policy to open when 50% of our requests fail during a 15 second interval where we handle at least 20 requests. We could then specify to keep the circuit open for 1 minute before allowing traffic through again. A failure, in this policy, is defined at the top of the above expression as:
- When any Exception occurs (.Handle
() ) or - When a default result is returned such as a null (.OrResult(default(T)))
Once our policy is available, we can simply execute our cache requests in the context of that policy. So, if we call our cache on a dependency held in a _cacheClient member, it might look like the samples below with and without using a policy.
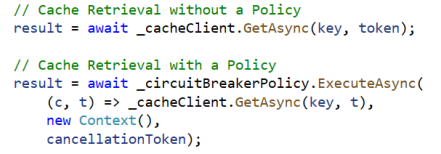
To use the policy, we call the same method as we would call without the policy, but do so within the ExecuteAsync method of the policy object. You might notice there is a Context object passed in to the policy. This allows information to be passed-around to the different sections of the policy. We will be using this later.
...the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
Executing our cache requests within the context of this policy allows the policy to keep track of the results of our requests and trigger the policy if the specified conditions are met. When this policy is triggered, the state of the circuit is automatically set to open and no requests are allowed to be serviced until the circuit is closed again. When either of these state transitions occur (Closed=>Open or Open=>Closed) the appropriate lambda is executed in the policy. Only logging is being done in this example, but the lambda that is executed when the circuit is opened is also a good place to execute logic to help the system to recover. This might include resetting the multiplexer if you are using the StackExchange.Redis client.
We can now protect our applications against outages. However, this does nothing to handle the situation where the data is not available in our cache. For this, we need a Failover (Fallback) policy.
Using a Failover Policy to Fall-Back to the System of Record
Many use-cases for caching involve holding frequently or recently retrieved values in the cache to avoid round-trips to a relational or other data source. This pattern speeds access to these data items while still allowing the system to gather and cache the information if it isn’t already in the cache.
Many policy libraries have methods to handle this pattern as well. A Polly policy describing this pattern is shown below.
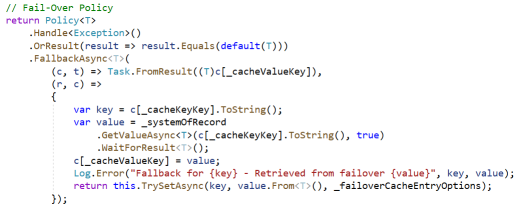
And to access the cache using this policy, we might use code like this.
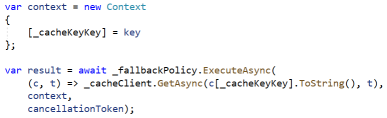
You’ll notice that the code to update the cache is specified in the policy itself (the 2nd Lambda). Like the circuit-breaker, this policy responds when any Exception is thrown or a default value (i.e. null) is returned. Unlike the circuit-breaker however, this policy executes its code every time there is a miss or error, not just when thresholds have been exceeded. You’ll also notice that, in the calling code, a Context object is defined and the cache key value is added to that property bag. This is used in the handling mechanism to access the value from the System of Record and to update the cache with that value. Once the value has been updated in the cache, it is returned to the caller by being pulled back out of the property bag by the 1st Lambda expression in the policy.
We’ll need to be careful here that we set the _failoverCacheEntryOptions appropriately for our use-case. If we allow our values to live too long in the cache without expiring, we can miss changes, or cause other values to be ejected from the cache. As always, be thoughtful with how long to cache the values in your use-case. We also do nothing here to handle errors occurring in the fallback system. You’ll want to manage those failures appropriately as well.
We can now declare a policy to fail-over to the system of record if that is appropriate for our use-case, but this policy doesn’t do anything to protect our systems from outages like our circuit-breaker example does. This is where our policy libraries can really shine, in their ability to combine policies.
Wrapping It Up - Combining Multiple Policies using Policy Wrappers
One of the real advantages of using a policy library like Polly is the ability to chain policies together to form complex reliability logic. Before going too deep into how we can use this to protect our cache-based applications, let’s look at the code to combine the two policies defined above, the Circuit-Breaker and Fallback policies. The code inside the CreateFallbackPolicy and CreateCircuitBreakerPolicy methods are just the return statements shown above that create each policy.
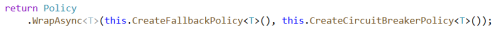
These policies are executed in the order specified, which means that the last one specified is the one closest to the cache itself. This is important because, if our circuit is open, we want the Fallback policy to handle the request and fail-over to the system of record. If we were to reverse this order, opening the circuit would mean that the Fallback policy is never executed because the Circuit Breaker policy would block it.
This combined policy, as shown above, does everything we need from a cache client for our most common use-cases.
- Returns the value from the cache on cache-hit
- Returns the value from the backup system (system of record) on cache-miss
- Populates the cache with values retrieved from the backup system on cache-miss
- Opens the circuit for the specified time if our failure thresholds are reached, indicating an outage
- Gives us the opportunity to perform other recovery logic, such as resetting the Multiplexer, when the circuit is opened
- Closes the circuit again after the specified timeframe
- Gives us the opportunity to to perform other logic as needed when the circuit is closed
In many cases our applications have implemented some or all of this logic themselves, whether it is in custom clients or abstractions like Queries or Repositories. If these applications are working well, and adequately protecting our systems and our customers from the inevitable failures experienced by distributed systems, there is certainly no need to change them. However, for systems that are experiencing problems when outages occur, or those being built today, I highly recommend considering using a policy library such as Polly to implement these reliability measures.
