Tag: testing
Code Coverage - The Essential Tool That Must Never Be Measured
Posted by bsstahl on 2024-09-14 and Filed Under: development
TLDR: Code Coverage is the Wrong Target
Code coverage metrics HURT code quality, especially when gating deployments, because they are a misleading target, prioritizing superficial benchmarks over meaningful use-case validation. A focus on achieving coverage percentages detracts from real quality assurance, as developers write tests that do what the targets insist that they do, satisfy coverage metrics rather than ensuring comprehensive use-case functionality.
When we measure code coverage instead of use-case coverage, we limit the value of the Code Coverage tools for the developer going forward as a means of identifying areas of concern within the code. If instead we implement the means to measure use-case coverage, perhaps using Cucumber/SpecFlow BDD tools, such metrics might become a valuable target for automation. Short of that, test coverage metrics and gates actually hurt quality rather than helping it.
- Do Not use code coverage as a metric, especially as a gate for software deployment.
- Do use BDD style tests to determine and measure the quality of software.
What is Code Coverage?
Code coverage measures the extent to which the source code of a program has been executed during the testing process. It is a valuable tool for developers to identify gaps in unit tests and ensure that their code is thoroughly tested. An example of the output of the Code Coverage tools in Visual Studio Enterprise from my 2015 article Remove Any Code Your Users Don't Care About can be seen below. In this example, the code path where the property setter was called with the same value the property already held, was not tested, as indicated by the red highlighting, while all other blocks in this code snippet were exercised by the tests as seen by the blue highlighting.

When utilized during the development process, Code Coverage tools can:
Identify areas of the codebase that haven't been tested, allowing developers to write additional tests to ensure all parts of the application function as expected.
Improve understanding of the tests by identifying what code is run during which tests.
Identify areas of misunderstanding, where the code is not behaving as expected, by visually exposing what code is executed during testing.
Focus testing efforts on critical or complex code paths that are missing coverage, ensuring that crucial parts of the application are robustly tested.
Identify extraneous code that is not executed during testing, allowing developers to remove unnecessary code and improve the maintainability of the application.
Maximize the value of Test-Driven Development (TDD) by providing immediate feedback on the quality of tests, including the ability for a developer to quickly see when they have skipped ahead in the process by creating untested paths.
All of these serve to increase trust in our unit tests, allowing the developers the confidence to "refactor ruthlessly" when necessary to improve the maintainability and reliability of our applications. However, they also depend on one critical factor, that when an area shows in the tooling as covered, the tests that cover it do a good job of guaranteeing that the needs of the users are met by that code. An area of code that is covered, but where the tests do not implement the use-cases that are important to the users, is not well-tested code. Unfortunately, this is exactly what happens when we use code coverage as a metric.
The Pitfalls of Coverage as a Metric
A common misunderstanding in our industry is that higher code coverage equates to greater software quality. This belief can lead to the idea of using code coverage as a metric in attempts to improve quality. Unfortunately, this well-intentioned miscalculation generally has the opposite effect, a reduction in code quality and test confidence.
Goodhart's Law
Goodhart's Law states that "When a measure becomes a target, it ceases to be a good measure." We have seen this principle play out in many areas of society, including education (teaching to the test), healthcare (focus on throughput rather than patient outcomes), and social media (engagement over truth).
This principle is particularly relevant when it comes to code coverage metrics. When code coverage is used as a metric, developers will do as the metrics demand and produce high coverage numbers. Usually this means writing one high-quality test for the "happy path" in each area of the code, since this creates the highest percentage of coverage in the shortest amount of time. It should be clear that these are often good, valuable tests, but they are not nearly the only tests that need to be written.
Problems as outlined in Goodhart's Law occur because a metric is nearly always a proxy for the real goal. In the case of code coverage, the goal is to ensure that the software behaves as expected in all use-cases. The metric, however, is a measure of how many lines of code have been executed by the tests. This is unfortunately NOT a good proxy for the real goal, and is not likely to help our quality, especially in the long-run. Attempting to use Code Coverage in this way is akin to measuring developer productivity based on the number of lines of code they create -- it is simply a bad metric.
A Better Metric
If we want to determine the quality of our tests, we need to measure the coverage of our use-cases, not our code. This is more difficult to measure than code coverage, but it is a much better proxy for the real goal of testing. If we can measure how well our code satisfies the needs of the users, we can be much more confident that our tests are doing what they are supposed to do -- ensuring that the software behaves as expected in all cases.
The best tools we have today to measure use-case coverage are Behavior Driven Development tools like Cucumber, for which the .NET implementation is called SpecFlow. These tools test how well our software meets the user's needs by helping us create test that focus on how the users will utilize our software. This is a much better proxy for the real goal of testing, and is much more likely to help us achieve our quality goals.
The formal language used to describe these use-cases is called Gherkin, and uses a Given-When-Then construction. An example of one such use-case test for a simple car search scenario might look like this:
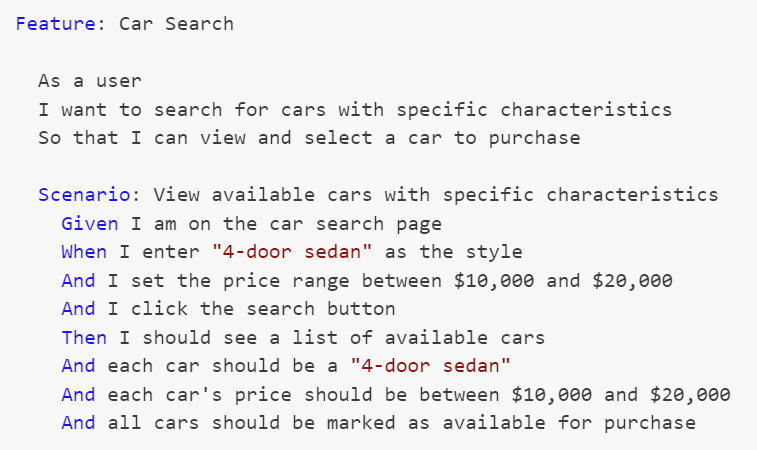
These Gherkin scenarios, often created by analysts, are translated into executable tests using step definitions. Each Gherkin step (Given, When, Then) corresponds to a method in a step definition file created by a developer, where annotations or attributes bind these steps to the code that performs the actions or checks described. This setup allows the BDD tool to execute the methods during test runs, directly interacting with the application and ensuring that its behavior aligns with defined requirements.
Since these tests exercise the areas of the code that are important to the users, coverage metrics here are a much better proxy for the real goal of testing, because they are testing the use-cases that are important to the users. If an area of code is untested by BDD style tests, that code is either unnecessary or we are missing use-cases in our tests.
Empowering Developers: Code Coverage Tools, Visualization, and Use Case Coverage
One of the most powerful aspects of code coverage tools are their data visualizations, allowing developers to assess which lines of code have been tested and which have not, right inside the code in the development environment. This visualization transcends the mere percentage or number of lines covered, adding significant value to the development process and enabling developers to make informed decisions about where to focus their testing efforts.
By permitting developers to utilize code coverage tools and visualization without turning them into a metric, we can foster enhanced software quality and more comprehensive testing. By granting developers the freedom to use these tools and visualize their code coverage, they can better identify gaps in their testing and concentrate on covering the most critical use cases. If instead of worrying about how many lines of code are covered, we focus on what use-cases are covered, we create better software by ensuring that the most important aspects of the application are thoroughly tested and reliable.
Creating an Environment that Supports Quality Development Practices
Good unit tests that accurately expose failures in our code are critical for the long-term success of development teams. As a result, it is often tempting to jump on metrics like code coverage to encourage developers to "do the right thing" when building software. Unfortunately, this seemingly simple solution is almost always the wrong approach.
Encourage Good Testing Practices without Using Code Coverage Metrics
So how do we go about encouraging developers to build unit tests that are valuable and reliable without using code coverage metrics? The answer is that we don't. A culture of quality development practices is built on trust, not metrics. We must trust our developers to do the right thing, and create an environment where they are empowered to do the job well rather than one that forces them to write tests to satisfy a metric.
Developers want to excel at their jobs, and never want to create bugs. No matter how much of a "no blame" culture we have, or how much we encourage them to "move fast and break things", developers will always take pride in their work and want to create quality software. Good tests that exercise the code in ways that are important to the users are a critical part of that culture of quality that we all want. We don't need to force developers to write these tests, we just need to give them the tools and the environment in which to do so.
There are a number of ways we can identify when this culture is not yet in place. Be on the lookout for any of these signs:
- Areas of code where, every time something needs to change, the developers first feel it necessary to write a few dozen tests so that they have the confidence to make the change, or where changes take longer and are more error-prone because developers can't be confident in the code they are modifying.
- Frequent bugs or failures in areas of the code that represent key user scenarios. This suggests that tests may have been written to create code coverage rather than to exercise the important use-cases.
- A developer whose code nobody else wants to touch because it rarely has tests that adequately exercise the important features.
- Regression failures where previous bugs are reintroduced, or exposed in new ways, because the early failures were not first covered by unit tests before fixing them.
The vast majority of developers want to do their work in an environment where they don't have to worry when asked to making changes to their teammates' code because they know it is well tested. They also don't want to put their teammates in situations where they are likely to fail because they had to make a change when they didn't have the confidence to do so, or where that confidence was misplaced. Nobody wants to let a good team down. It is up to us to create an environment where that is possible.
Conclusion: Code Coverage is a Developer's Tool, Not a Metric
Code coverage is an invaluable tool for developers, but it should not be misused as a superficial metric. By shifting our focus from the number of code blocks covered to empowering developers with the right tools and environment, we can ensure software quality through proper use-case coverage. We must allow developers to utilize these valuable tools, without diluting their value by using them as metrics.
Tags: development testing principle code-coverage
Continuing a Conversation on LLMs
Posted by bsstahl on 2023-04-13 and Filed Under: tools
This post is the continuation of a conversation from Mastodon. The thread begins here.
Update: I recently tried to recreate the conversation from the above link and had to work far harder than I would wish to do so. As a result, I add the following GPT summary of the conversation. I have verified this summary and believe it to be an accurate, if oversimplified, representation of the thread.
The thread discusses the value and ethical implications of Language Learning Models (LLMs).
@arthurdoler@mastodon.sandwich.net criticizes the hype around LLMs, arguing that they are often used unethically, or suffer from the same bias and undersampling problems as previous machine learning models. He also questions the value they bring, suggesting they are merely language toys that can't create anything new but only reflect what already exists.
@bsstahl@CognitiveInheritance.com, however, sees potential in LLMs, stating that they can be used to build amazing things when used ethically. He gives an example of how even simple autocomplete tools can help generate new ideas. He also mentions how earlier LLMs like Word2Vec were able to find relationships that humans couldn't. He acknowledges the potential dangers of these tools in the wrong hands, but encourages not to dismiss them entirely.
@jeremybytes@mastodon.sandwich.net brings up concerns about the misuse of LLMs, citing examples of false accusations made by ChatGPT. He points out that people are treating the responses from these models as facts, which they are not designed to provide.
@bsstahl@CognitiveInheritance.com agrees that misuse is a problem but insists that these tools have value and should be used for legitimate purposes. He argues that if ethical developers don't use these tools, they will be left to those who misuse them.
I understand and share your concerns about biased training data in language models like GPT. Bias in these models exists and is a real problem, one I've written about in the past. That post enumerates my belief that it is our responsibility as technologists to understand and work around these biases. I believe we agree in this area. I also suspect that we agree that the loud voices with something to sell are to be ignored, regardless of what they are selling. I hope we also agree that the opinions of these people should not bias our opinions in any direction. That is, just because they are saying it, doesn't make it true or false. They should be ignored, with no attention paid to them whatsoever regarding the truth of any general proposition.
Where we clearly disagree is this: all of these technologies can help create real value for ourselves, our users, and our society.
In some cases, like with crypto currencies, that value may never be realized because the scale that is needed to be successful with it is only available to those who have already proven their desire to fleece the rest of us, and because there is no reasonable way to tell the scammers from legit-minded individuals when new products are released. There is also no mechanism to prevent a takeover of such a system by those with malicious intent. This is unfortunate, but it is the state of our very broken system.
This is not the case with LLMs, and since we both understand that these models are just a very advanced version of autocomplete, we have at least part of the understanding needed to use them effectively. It seems however we disagree on what that fact (that it is an advanced autocomplete) means. It seems to me that LLMs produce derivative works in the same sense (not method) that our brains do. We, as humans, do not synthesize ideas from nothing, we build on our combined knowledge and experience, sometimes creating things heretofore unseen in that context, but always creating derivatives based on what came before.
Word2Vec uses a 60-dimensional vector store. GPT-4 embeddings have 1536 dimensions. I certainly cannot consciously think in that number of dimensions. It is plausible that my subconscious can, but that line of thinking leads to the the consideration of the nature of consciousness itself, which is not a topic I am capable of debating, and somewhat ancillary to the point, which is: these tools have value when used properly and we are the ones who can use them in valid and valuable ways.
The important thing is to not listen to the loud voices. Don't even listen to me. Look at the tools and decide for yourself where you find value, if any. I suggest starting with something relatively simple, and working from there. For example, I used Bing chat during the course of this conversation to help me figure out the right words to use. I typed in a natural-language description of the word I needed, which the LLM translated into a set of possible intents. Bing then used those intents to search the internet and return results. It then used GPT to summarize those results into a short, easy to digest answer along with reference links to the source materials. I find this valuable, I think you would too. Could I have done something similar with a thesaurus, sure. Would it have taken longer: probably. Would it have resulted in the same answer: maybe. It was valuable to me to be able to describe what I needed, and then fine-tune the results, sometimes playing-off of what was returned from the earlier requests. In that way, I would call the tool a force-multiplier.
Yesterday, I described a fairly complex set of things I care to read about when I read social media posts, then asked the model to evaluate a bunch of posts and tell me whether I might care about each of those posts or not. I threw a bunch of real posts at it, including many where I was trying to trick it (those that came up in typical searches but I didn't really care about, as well as the converse). It "understood" the context (probably due to the number of dimensions in the model and the relationships therein) and labeled every one correctly. I can now use an automated version of this prompt to filter the vast swaths of social media posts down to those I might care about. I could then also ask the model to give me a summary of those posts, and potentially try to synthesize new information from them. I would not make any decisions based on that summary or synthesis without first verifying the original source materials, and without reasoning on it myself, and I would not ever take any action that impacts human beings based on those results. Doing so would be using these tools outside of their sphere of capabilities. I can however use that summary to identify places for me to drill-in and continue my evaluation, and I believe, can use them in certain circumstances to derive new ideas. This is valuable to me.
So then, what should we build to leverage the capabilities of these tools to the benefit of our users, without harming other users or society? It is my opinion that, even if these tools only make it easier for us to allow our users to interact with our software in more natural ways, that is, in itself a win. These models represent a higher-level of abstraction to our programming. It is a more declarative mechanism for user interaction. With any increase in abstraction there always comes an increase in danger. As technologists it is our responsibility to understand those dangers to the best of our abilities and work accordingly. I believe we should not be dismissing tools just because they can be abused, and there is no doubt that some certainly will abuse them. We need to do what's right, and that may very well involve making sure these tools are used in ways that are for the benefit of the users, not their detriment.
Let me say it this way: If the only choices people have are to use tools created by those with questionable intent, or to not use these tools at all, many people will choose the easy path, the one that gives them some short-term value regardless of the societal impact. If we can create value for those people without malicious intent, then the users have a choice, and will often choose those things that don't harm society. It is up to us to make sure that choice exists.
I accept that you may disagree. You know that I, and all of our shared circle to the best of my knowledge, find your opinion thoughtful and valuable on many things. That doesn't mean we have to agree on everything. However, I hope that disagreement is based on far more than just the mistrust of screaming hyperbolists, and a misunderstanding of what it means to be a "overgrown autocomplete".
To be clear here, it is possible that it is I who is misunderstanding these capabilities. Obviously, I don't believe that to be the case but it is always a possibility, especially as I am not an expert in the field. Since I find the example you gave about replacing words in a Shakespearean poem to be a very obvious (to me) false analog, it is clear that at lease one of us, perhaps both of us, are misunderstanding its capabilities.
I still think it would be worth your time, and a benefit to society, if people who care about the proper use of these tools, would consider how they could be used to society's benefit rather than allowing the only use to be by those who care only about extracting value from users. You have already admitted there are at least "one and a half valid use cases for LLMs". I'm guessing you would accept then that there are probably more you haven't seen yet. Knowing that, isn't it our responsibility as technologists to find those uses and work toward creating the better society we seek, rather than just allowing extremists to use it to our detriment.
Update: I realize I never addressed the issue of the models being trained on licensed works.
Unless a model builder has permission from a user to train their models using that user's works, be it an OSS or Copyleft license, explicit license agreement, or direct permission, those items should not be used to train models. If it is shown that a model has been trained using such data sets, and there have been indications (unproven as yet to my knowledge) that this may be the case for some models, especially image-generators, then that is a problem with those models that needs to be addressed. It does not invalidate the general use of these models, nor is it an indictment of any person or model except those in violation. Our trademark and copyright systems are another place where we, as a society, have completely fallen-down. Hopefully, that collapse will not cause us to forsake the value that these tools can provide.
Tags: coding-practices development enterprise responsibility testing ai algorithms ethics mastodon
Programmers -- Take Responsibility for Your AI’s Output
Posted by bsstahl on 2018-03-16 and Filed Under: development
plus ça change, plus c'est la même chose – The more that things change, the more they stay the same. – Rush (and others
)
In 2013 I wrote that programmers needed to take responsibility for the output of their computer programs. In that article, I advised developers that the output of their system, no matter how “random” or “computer generated”, was still their responsibility. I suggested that we cannot cop out by claiming that the output of our programs is not our fault simply because we didn’t directly instruct the computer to issue that specific result.
Today, we have a similar problem, only the stakes are much, much, higher.
In the world of 2018, our algorithms are being used in police work and inside other government agencies to know where and when to deploy resources, and to decide who is and isn’t worthy of an opportunity. Our programs are being used in the private sector to make decisions from trading stocks to hiring, sometimes at a scale and speed that puts us all at risk of economic events. These tools are being deployed by information brokers such as Facebook and Google to make predictions about how best to steal the most precious resource we have, our time. Perhaps scariest of all, these algorithms may be being used to make decisions that have permanent and irreversible results, such as with drone strikes. We simply have no way of knowing the full breadth of decisions that AIs are making on our behalf today. If those algorithms are biased in any way, the decisions made by these programs will be biased, potentially in very serious ways and with serious results.
If we take all available steps to recognize and eliminate the biases in our systems, we can minimize the likelihood of our tools producing output that we did not expect or that violates our principles.
All of the machines used to execute these algorithms are bias-free of course. A computer has no prejudices and no desires of its own. However, as we all know, decision-making tools learn what we teach them. We cannot completely teach these algorithms free of our own biases. It simply cannot be done since all of our data is colored by our existing biases. Perhaps the best known example of bias in our data is in crime data used for policing. If we send police to where there is most often crime, we will be sending them to the same places we’ve sent them in the past, since generally, crime involves having a police office in the location to make an arrest. Thus, any biases we may have had in the past about where to send police officers, will be represented in our data sets about crime.
While we may never be able to eliminate biases completely, there are things that we can do to minimize the impact of the biases we are training into our algorithms. If we take all available steps to recognize and eliminate the biases in our systems, we can minimize the likelihood of our tools producing output that we did not expect or that violates our principles.
Know that the algorithm is biased
We need to accept the fact that there is no way to create a completely bias-free algorithm. Any dataset we provide to our tools will inherently have some bias in it. This is the nature of our world. We create our datasets based on history and our history, intentionally or not, is full of bias. All of our perceptions and understandings are colored by our cognitive biases, and the same is true for the data we create as a result of our actions. By knowing and accepting this fact, that our data is biased, and therefore our algorithms are biased, we take the first step toward neutralizing the impacts of those biases.
Predict the possible biases
We should do everything we can to predict what biases may have crept into our data and how they may impact the decisions the model is making, even if that bias is purely theoretical. By considering what biases could potentially exist, we can watch for the results of those biases, both in an automated and manual fashion.
Train “fairness” into the model
If a bias is known to be present in the data, or even likely to be present, it can be accounted for by defining what an unbiased outcome might look like and making that a training feature of the algorithm. If we can reasonably assume that an unbiased algorithm would distribute opportunities among male and female candidates at the same rate as they apply for the opportunity, then we can constrain the model with the expectation that the rate of accepted male candidates should be within a statistical tolerance of the rate of male applicants. That is, if half of the applicants are men then men should receive roughly half of the opportunities. Of course, it will not be nearly this simple to define fairness for most algorithms, however every effort should be made.
Be Open About What You’ve Built
The more people understand how you’ve examined your data, and the assumptions you’ve made, the more confident they can be that anomalies in the output are not a result of systemic bias. This is the most critical when these decisions have significant consequences to peoples’ lives. A good example is in prison sentencing. It is unconscionable to me that we allow black-box algorithms to make sentencing decisions on our behalf. These models should be completely transparent and subject to our analysis and correction. That they aren’t, but are still being used by our governments, represent a huge breakdown of the system, since these decisions MUST be made with the trust and at the will of the populace.
Build AIs that Provide Insight Into Results (when possible)
Many types of AI models are completely opaque when it comes to how decisions are reached. This doesn’t mean however that all of our AIs must be complete black-boxes. It is true that most of the common machine learning methods such as Deep-Neural-Networks (DNNs) are extremely difficult to analyze. However, there are other types of models that are much more transparent when it comes to decision making. Some model types will not be useable on all problems, but when the options exist, transparency should be a strong consideration.
There are also techniques that can be used to make even opaque models more transparent. For example, a hybrid technique (AI That Can Explain Why & An Example of a Hybrid AI Implementation) can be used to run opaque models iteratively. This can allow the developer to log key details at specific points in the process, making the decisions much more transparent. There are also techniques to manipulate the data after a decision is made, to gain insight into the reasons for the decision.
Don’t Give the AI the Codes to the Nukes
Computers should never be allowed to make automated decisions that cannot be reversed by a human if necessary. Decisions like when to attack a target, execute a criminal, vent radioactive waste, or ditch an aircraft are all decisions that require human verification since they cannot be undone if the model has an error or is faced with a completely unforeseen set of conditions. There are no circumstances where machines should be making such decisions for us without the opportunity for human intervention, and it is up to us, the programmers, to make sure that we don’t give them that capability.
Don’t Build it if it Can’t be Done Ethically
If we are unable to come up with an algorithm that is free from bias, perhaps the situation is not appropriate for an automated decision making process. Not every situation will warrant an AI solution, and it is very likely that there are decisions that should always be made by a human in totality. For those situations, a decision support system may be a better solution.
The Burden is Ours
As the creators of automated decision making systems, we have the responsibility to make sure that the decisions they make do not violate our standards or ethics. We cannot depend on our AIs to make fair and reasonable decisions unless we program them to do so, and programming them to avoid inherent biases requires an awareness and openness that has not always been present. By taking the steps outlined here to be aware of the dangers and to mitigate it wherever possible, we have a chance of making decisions that we can all be proud of, and have confidence in.
Tags: coding-practices development enterprise responsibility testing ai algorithms ethics
A Requirement for AI Systems
Posted by bsstahl on 2017-05-24 and Filed Under: development
I've written and spoken before about the importance of using the Strategy Pattern to create maintainable and testable systems. Strategies are even more important, almost to the level of necessity, when building AI systems.
The Strategy Pattern is to algorithms what the Repository Pattern is to data stores, a useful and well-known abstraction for loose-coupling. — Barry Stahl (@bsstahl) January 6, 2017
The Strategy Pattern is an abstraction tool used to maintain loose-coupling between an application and the algorithm(s) that it uses to do its job. Since the algorithms used in AI systems have many different ways they could be implemented, it is important to abstract the implementation from the system that uses it. I tend to work with systems that use combinatorial optimization methods to solve their problems, but there are many ways for AIs to make decisions. Machine Learning is one of the hottest methods right now but AI systems can also depend on tried-and-true object-oriented logic. The ability to swap algorithms without changing the underlying system allows us the flexibility to try multiple methods before settling on a specific implementation, or even to switch-out implementations as scenarios or situations change.
When I give conference talks on building AI Systems using optimization methods, I always encourage the attendees to create a "naïve" solution first, before spending a lot of effort to build complicated logic. This allows the developer to understand the problem better than he or she did before doing any implementation. Creating this initial solution has another advantage though, it allows us to define the Strategy interface, giving us a better picture of what our application truly needs. Then, when we set-out to build a production-worthy engine, we do so with the knowledge of exactly what we need to produce.
There is also another component of many AIs that can benefit from the use of the Strategy pattern, and that is the determination of user intent. Many implementations of AI will include a user interaction, perhaps through a text-based interface as in a chatbot or a voice interface such as a personal assistant. Each cloud provider has their own set of services designed to determine the intent of the user based on the text or voice input. Each of these implementations has its own strengths and weaknesses. It is beneficial to be able to swap those mechanisms out at will, along with the ability to implement a "naïve" user intent solution during development, and the ability to mock user intent for testing. The strategy pattern is the right tool for this job as well.
As more and more of our applications depend heavily on algorithms, we will need to make a concerted effort to abstract those algorithms away from our applications to maintain loose-coupling and all of the benefits that loose-coupling provides. This is why I consider the Strategy Pattern to be a necessity when developing Artificial Intelligence solutions.
Tags: abstraction algorithms ai cloud coding-practices decision interface pattern testing unit testing
Testing the Untestable with Microsoft Fakes
Posted by bsstahl on 2017-03-20 and Filed Under: development
It is fairly easy these days to test code in isolation if its dependencies are abstracted by a reusable interface. But what do we do if the dependency cannot easily be referenced via such an interface? Enter Shims, from the Microsoft Fakes Framework(formerly Moles). Shims allow us to isolate our testing from any dependent methods, including methods in assemblies we do not control, even if those methods are not exposed through a reusable interface. To see how easy it is, follow along with me through this example.
In this sample code on GitHub, we are building a repository for an application that currently gets its data from a file exported from a system that tracks scheduled meetings. It is very likely that the system will, in the future, expose a more modern interface for that data so we have isolated the data storage using a simple Repository interface that has one method. This method, called GetMeetings returns a collection of Meeting entities that start during the specified date range. The method will return an empty collection if no data is found matching the specified criteria, and could throw either of 2 custom errors, a PermissionsExceptionwhen the user does not have the proper permissions to access the information, and a DataUnavailableException for when the data source is unavailable for any other reason, such as a network outage or if the data file cannot be located.
It is important to point out why a custom exception should be thrown when the data file is not found, rather than allowing the FileNotFoundException to bubble-up. If we allow the implementation-specific exception to bubble, we have exposed an implementation detail to the caller. That is, the calling code is now aware of the fact that this is a file system implementation. If code is written in a client that traps for FileNotFoundException, then the repository implementation is swapped-out for a SQL server implementation, the client code will have to change to handle the new types of errors that could be thrown by that implementation. This violates the Dependency Inversion principle, the “D” from the SOLID principles. By exposing only a custom exception, we are hiding those implementation details from the caller.
Downstream clients can easily test code that uses this repository without having to actually access the repository implementation because we have exposed the IMeetingSourceRepository interface. However, it is a bit more difficult to actually test the repository implementation itself. We have a few options here:
- Create data files that hold known data samples and load those files during unit testing.
- Create a wrapper around the System.IO namespace that exposes an interface, such as in the System.IO.Abstractions project.
- Don’t test any code that requires reaching-out to the file system.
Since I am of the opinion that 100% code coverage is both reasonable, and desirable (although not a measurable goal), I will summarily dispose of option 3 for the purpose of this analysis. I have used option 2 many times in my life, and while employing wrapper code is a valid and reasonable solution, it adds additional code to my production deployments that is very limited in terms of what it adds to the loose-coupling of my solution since I already am loosely-coupled to this implementation via the IMeetingSourceRepository interface.
Even though it is far from a perfect solution (many would consider them more integration tests than unit tests), I initially selected option 1 for this implementation. That is, I created data files and deployed them along with my tests. You can see the test files I created in the Data folder of the MeetingSystem.Data.FileSystem.Test project. These files are deployed alongside my tests using the DeploymentItem directive that decorates the Repository_GetMeetings_Should class of the test project. Using this method, I was able to create tests that:
- Verify that the correct # of meetings are returned from a file
- Verify that meetings are properly filtered by the StartDateTime of the meeting
- Validate the data elements returned from the file
- Validate that the proper custom exception is thrown if a FileNotFoundException is thrown by the underlying code
So we have verified nearly everything we need to test in our implementation. We’ve verified that the data is returned properly, and that one of our custom exceptions is being returned. But what about the PermissionsException? We were able to simulate a FileNotFoundException in our tests by just using a bad filename, but how do we test for a permissions problem? The ReadAllText method of the File object from System.IO will throw a System.Security.SecurityException if the file cannot be read due to a permissions problem. We need to trap this exception and throw our own exception, but how can we validate that we have successfully done so and that the functionality remains intact through future refactoring? How can we simulate a permissions exception on a file that we have enough permission on to deploy to a test folder? Enter Shims from the Microsoft Fakes Framework.
Instead of having our tests actually reach-out to the file system and actually try to load a file, we can intercept calls to the System.IO.File.ReadAllText method and have those calls execute some delegate code instead. This code, which we write in our test methods, can be specific to each test and exist only within the context of the test. As a result, we are not deploying any additional code to production, while still thoroughly validating our code. In fact, using this methodology, I could re-implement my previous tests, including my test data in the tests themselves, making these tests better unit tests. I could then reserve tests that actually reach out to files for integration test libraries that are run less frequently, and perhaps even behind the scenes.
Note: If you wish to follow-along with these instructions, you can grab the code from the DemoStart branch of the GitHub repo, rather than the Master branch where this is already done.
To use Shims, we first have to create a Fakes Assembly. This is done by right-clicking on the System reference in the test project from Visual Studio 2017, and selecting “Add Fakes Assembly” (full framework only – not yet available for .NET Core assemblies). Be sure to do this in the test project since we don’t want to actually deploy the Fakes assembly in our production code. Using the add fakes assembly menu item does 2 things:
- Adds a reference to Microsoft.QualityTools.Testing.Fakes assembly
- Creates 2 .fakes XML files in the Fakes folder within the test project. These items are built into corresponding fakes dll files that are deployed with the test project and used to provide stub and shim objects that mimic the objects in the selected assemblies. These fake objects reside in the same namespace as their “real” counterparts, except with “Fakes” on the end. Thus, our fake File object will reside in the System.IO.Fakes namespace.
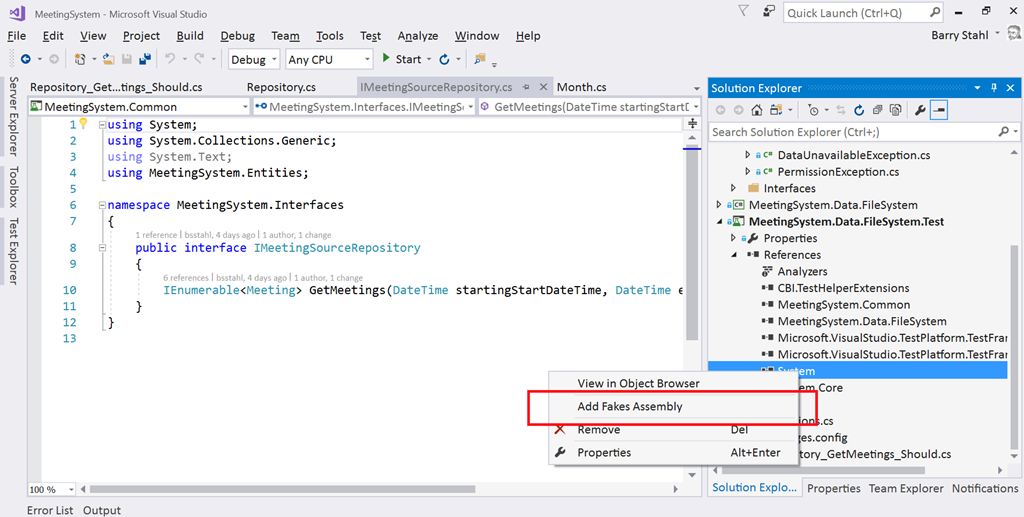
The next step in using shims is to create a ShimsContext within a Using statement. Any method calls that execute within this context can be intercepted and replaced by our delegates. For example, a test that replaces the call to ReadAllText with a method that returns a single line of constant data can be seen below.
Methods on shim objects are referenced through properties of the fake object. These properties are of type FakesDelegate.Func and match the signature of the method being shimmed. The return data type is also appended to the property name so that each item’s signature can be represented with a different property name. In this case, the ReadAllText method of the File object is represented in the System.IO.Fakes.File object as a property called ReadAllTextString, of type FakesDelegate.Func<string, string>, since the method takes a string parameter (the path of the file), and returns a string (the text contents of the file). If we assign a method delegate to this property, that method will be executed in place of the call to System.IO.File.ReadAllText whenever ReadAllText is called within the ShimContext.
In the gist shown above, the variable p represents the input parameter and will hold the path specified in the test (in this case “April2017.abc”). The return value for our delegate method comes from the constant string dataFile. We can put anything we want here. We can replace the delegate with a call to an anonymous method, or with a call to an existing method. We can return a value gleaned from an external source, or, as is needed for our permissions test, throw an exception.
For the purposes of our test to verify that we throw a PermissionsException when a SecurityException is thrown, we can replace the value of the ReadAllTextString property with our delegate which throws the exception we need to test for, as seen here:
System.IO.Fakes.ShimFile.ReadAllTextString =
p => throw new System.Security.SecurityException("Test Exception");
Then, we can verify in our test that our custom exception is thrown. The full working example can be seen by grabbing the Master branch of the GitHub repo.
What can you test with these Shim objects that you were unable to test before? Tell me about it @bsstahl.
Tags: abstraction assembly code sample framework fakes interface moles mstest solid tdd testing unit testing visual studio
Demo Code for Testing in Visual Studio 2017
Posted by bsstahl on 2017-03-16 and Filed Under: event
The demo code for my presentation on Testing in Visual Studio 2017 at the VS2017 Launch event can be found on GitHub. There are 2 branches to this repository, the Main branch which holds the completed demo, and the DemoStart branch which holds the starting point of the demonstration in case you would like to implement the sample yourself.
The demo shows how Microsoft Fakes (formerly Moles) can be used to create tests against code that does not implement a reusable interface. This can be done without having to resort to integration style tests or writing extra wrapper code just to implement an interface. During my launch presentation, I also use this code to demonstrate the use of Intellitest (formerly Pex) to generate exploratory tests.
Tags: abstraction code sample coding-practices community conference development di interface microsoft moles mstest pex phoenix presentation tdd testing unit testing visual studio
Testing a .NET Core Library in VS2015
Posted by bsstahl on 2017-01-09 and Filed Under: development
I really enjoy working with .NET Core. I like the fact that my code is portable to many platforms and that the footprint is so much smaller than with traditional .NET applications. Unfortunately, the tooling has not quite reached the level that we expect from a Microsoft finished product (which it isn’t – yet). As a result, there are some additional actions we need to take when setting up our solutions in Visual Studio 2015 to allow us to unit test our code properly. The following are the steps that I currently take to setup and test a .NET Core library using XUnit and Moq. I know that a number of these steps will be done for us, or at least made much easier, by the tooling in the coming months, either by Visual Studio 2017, or by enhancements to the Visual Studio 2015 environments.
- Create the library to be tested in Visual Studio 2015
- File > New Project > .Net Core > Class Library
- Notice that this project is created in a solution folder called ‘src’
- Create a solution folder named ‘test’ to hold our test projects
- Right-click on the Solution > Add > New Solution Folder
- Add a new console application to the test folder as our test project
- Right-click on the ‘test’ folder > Add > New Project > .Net Core > Console Application
- Add a reference to the library being tested in the test project
- Right-click on the test project > Add > Reference > Select the library to be tested
- Install packages needed for unit testing from NuGet to the test project
- Right-click on the test project > Manage NuGet Packages > Browse
- Install ‘xunit’ as our unit test runner
- The current version for .Net Core is ‘2.2.0-beta4-build3444’
- Install ‘dotnet-test-xunit’ to integrate xunit with the Visual Studio test tools
- The current version for .Net Core is ‘2.2.0-preview2-build1029’
- Install ‘Moq’ as our mocking library
- The current version for .Net Core is ‘4.6.38-alpha’
- Edit the project.json of the test library
- Change the “EmitEntryPoint” option to false
- Add “testrunner” : “xunit” node
Some other optional steps include:
- Install the ‘Microsoft.CodeCoverage’ package from NuGet to enable the code coverage tooling
- Install the ‘Microsoft.Extension.DependencyInjection’ package from NuGet to enable DI
- Install the ‘TestHelperExtensions’ package from NuGet to add extensions that assist with writing good unit tests
- Add any additional runtimes that might be needed. Some options are:
- win10-x86
- win10-x64
- win7-x86
- win7-x64
- Set ‘Run tests after build’ in Visual Studio so tests run automatically
There will likely be better ways to do many of these things shortly, but if you know a better way now, please let me know @bsstahl.
Tags: testing code coverage development di ioc microsoft moq mocks professional development tdd unit testing visual studio dotnet
Code Coverage Teaches and Protects
Posted by bsstahl on 2016-10-14 and Filed Under: development
I often hail code coverage as a great tool to help improve your code base. Today, my use of Code Coverage taught me something about the new .NET Core tooling, and helped protect me from having to support useless code for the lifespan of my project.
In the code below, I used a common dependency injection pattern. That is, an IServiceProvider object holding my dependencies is passed-in to my object and stored as a member variable. When a dependency is needed, I retrieve that dependency from the service provider, and then take action on it. Since there is no guarantee that the dependency I need will have been placed in the container, I use some common guard logic to protect my code.
templates = _serviceProvider.GetService<IEnumerable<Template>>();
if ((templates==null) || (!templates.Any(s => s.TemplateType==ContactPage)))
throw new TemplateNotFoundException(TemplateType.ContactPage, string.Empty);
In this code, I first test that I was able to retrieve a collection of Template objects from the service provider, then verify that the type of Template I need is present in the collection. If either is not the case, an exception is thrown.
I had two tests that covered this section of code, one where the collection was not added to the service provider, the other where an empty collection was added. Both tests passed, however, it wasn't until I looked at the results of the Code Coverage that I realized that the 1st test wasn't doing what I thought it was doing. It turns out that there is actually no way to get a null collection object out of the Microsoft.Extensions.DependencyInjection.ServiceProvider object I am using for my .NET Core apps. That provider simply returns an empty collection if there isn't one in the container. Thus, my check for null was never matched and that branch of code was never executed.
Based on this new knowledge of the behavior of the IServiceProvider, I had a few options. I could:
- Rewrite my test to check for an empty collection. This option seems redundant to me since my check to see if the container holds the template I need is really what I care about.
- Leave the code as-is just in case the behavior of the container changes, accepting that I have what is currently unnecessary and untestable code in my application. I considered this option but it seems to me that a better defense against the unlikely event of a breaking change in the IServiceProvider implementation is described below in option 3.
- Create a new test that verifies the behavior on the ServiceProvider that an empty collection is returned if no collection is supplied to the container. I am not a big fan of this option since it requires me to test OPC (other people's code), and because the risk of this type of breaking change is, in my opinion, extremely low.
- Remove the guard code that tests for null and the test that supports it. Since the code is completely unnecessary, the test itself is redundant because it is, essentially identical to the test verifying that the template I need is in the collection.
I'm sure you've guessed by now that I selected option 4. I removed the guard code and the test from my solution. In doing so, I removed dead code that served no purpose, but would have to be supported through the life of the project.
For those who might be thinking something similar to, "It's nice that the coverage tooling helped you learn about your code, but using Code Coverage as a metric is actually a bad idea so I won't use Code Coverage at all", I'd like to remind you that any tool, such as a hammer or a car, can be abused. That doesn't mean we don't continue to use them, we just make certain that we use them properly. Code Coverage is a horrible way to measure a development team or effort, but it is an outstanding tool and should be used by the development team whenever possible to discover things about the code base.
Tags: abstraction agile assert code analysis code coverage coding-practices csharp ioc testing unit testing dotnet
TDD Helps Validate Your Tests
Posted by bsstahl on 2016-03-05 and Filed Under: development
One of the reasons to use TDD over test-later approaches is that you get a better validation of your tests.
When the first thing you do with a test or series of tests is to run them against code that does nothing but throw a NotImplementedException, you know exactly what to expect. That is, all tests should fail because the code under test threw a NotImplementedException. After that, you can take iterative steps to implement the code. Along the way, you should always see your tests fail in appropriate ways. Eventually, all of your tests should pass when the code is complete.
If tests start passing before they should, continue to fail when they shouldn’t, or fail for reasons that are different than what you’d expect at that point in the development process, you have a good indication that the test may not be doing what you want it to be doing. This additional information about the tests can be very helpful in making sure your unit tests are properly testing your code.
Think about what happens when you add tests after the code has already been written. Suppose you write a test for existing code, and it passes. What do you really know about the test? Is it working because it is adequately exercising your code? Did you forget to do an assert? Is it even testing the proper bit of code? Code coverage tools can help with some of this but they can only help if the code under test is not already touched by other tests. Stepping through the code in debug mode is another possibility, a third option is to comment out the code as if you were starting from scratch, effectively doing a TDD process without any of the other benefits of TDD.
What about when you write a test for previously written code, and the test fails? At this point, there are 2 possibilities:
- The code-under-test is broken
- The test is broken
You now have 2 variables in the equation, the code and the test, when you could have had only 1. To eliminate 1 of the variables, you have to again perform the TDD process without most of its benefits by commenting out the code and starting from ground zero.
Following a good TDD process is the best way to be confident that any test failures indicate problems in the code being tested, instead of the tests themselves.
Tags: code analysis code coverage coding-practices tdd testing unit testing
Test-Driven Bug Fixes
Posted by bsstahl on 2016-02-27 and Filed Under: development
I had an experience this past week that reminded me of both the importance of continuing the Test Driven Development process beyond the initial development phases of a application's life-cycle, and that not all developers have yet fully grasped the concepts behind Test Driven Development.
One of the development teams I work with had a bug come-up in a bit of complex logic that I designed. I was asked to pair-up with one of the developers to help figure out the bug since he had already spent several hours looking at it. When I asked him to show me the tests that were failing, there weren't any. The bug was for a situation that we hadn't anticipated during initial development (a common occurrence) and he had not yet setup any tests that exposed the bug.
We immediately set out to rectify the situation by creating tests that failed as a result of the bug. Once these tests were created, it was a fairly simple process to use those tests as a debug platform to step through the code, find the problem and correct the bug. As is sometimes the case, fixing that bug caused another test to fail, a situation that was easily remedied since we knew about it due to the failing test.
After the code was complete and checked-in for build, the developer I was working with remarked on how he now "got it". He had heard the words before, "…write a test to expose the bug, then fix the bug." but they were empty words until he actually experienced using a test to do the debugging, and then saw existing tests prevent a regression failure in other code due to our bug fix. It is an experience all TDD practitioners have at some point and it is easy to forget that others may not yet have grokked the concepts behind the process.
Coincidentally, that very night, I got a ping from my friend Jeremy Clark (blog, twitter) asking for comments on his latest YouTube video on TDD. After watching it, I really couldn't offer any constructive criticism for him because there was absolutely nothing to criticize. As an introduction to the basics of TDD, I don't think it could have been done any better. If you are just getting started with TDD, or want to get started with TDD, or want a refresher on the basics of TDD, you need to watch this video.
Jeremy has indicated he will be doing more in this series in the future, delving deeper into the topic of TDD. Perhaps he will include an example of fixing a bug in existing code in a future video.
Tags: agile coding-practices professional development tdd testing unit testing
Remove Any Code Your Users Don't Care About
Posted by bsstahl on 2015-09-28 and Filed Under: development
Code Coverage has been the topic of a number of conversations lately, most recently after the last Southeast Valley .NET User Group meeting where Jeremy Clark presented his great talk, Unit Testing Makes Me Faster. During this presentation, Jeremy eponymized, on my behalf, something I've been saying for a while, that the part of an application that you don't need to test is the part that your users don't care about. That is, if your users care about something in your application, you should be writing tests that ensure that the users' needs are fulfilled by your code. This has never really been a controversial statement, just one that sometimes gets lost in the myriad of information about unit testing and test driven development.
Where the conversation got really interesting was when we started discussing what should happen if you decide that a piece of code really isn't important to your users. It is my assertion that code which is deemed unimportant enough to the user that it might not be tested, should be removed from the project, even if is part of a standard implementation. I will attempt to justify this assertion by using the example of a property implementation that supports the INotifyPropertyChanged interface.
A visualization of the results of Code Coverage analysis on a typical property implementation. The blue highlights represent code that is covered by tests, the red highlights represent code that is NOT covered by tests.
In this example, we have a property getter and setter. The getter simply returns the value stored in the internal member. However the setter holds some actual logic. In this case, the new value being set is compared to the current value of the property. If the property value is changing, the update is made and a method called that fires a notification event indicating that the value of the property has changed. This is a fairly common implementation, especially for View-Model layer code.
Decision: Do my users care about this feature?
The conditional in this code is designed to skip the assignment and the change notification if the property value is not really changing. If we were to eliminate the conditional, it would impact the users of this code in the following ways?
- A few CPU cycles may be wasted on an assignment that isn't doing anything
- An event indicating the property was changed would fire incorrectly
In the vast majority of cases, the performance hit from item 1 is trivial and can be ignored. Item 2 however is a bit more complicated. Unless I know for certain that firing the event when the property is not really changing isn't a problem, I have to assume it is a problem, since there are any number of things that could happen as a result of having an event fire. Often, when this event fires it will cause a refresh of the bound data to the UI elements. This may have a significant impact on performance, or it may not. There may also be additional actions taken by the programmers of this event client that may not be foreseeable when designing this layer. If the circumstances are such that I know there will be no problems if the event fires more often than it should, then I can probably conclude that my users don't care about this code. In all other circumstances, I should probably conclude that they do.
Decision: Should I remove this code?
If I have concluded that my users care about the code, then my path is clear, I should leave the code in place and write tests to make sure that the event fires when it should, and only when it should. However, if I have concluded that my users don't care about this particular code, then I have another decision to make. I need to decide if I should leave the code untested but in place, remove the code from my project, or leave it in and write tests for it anyway.
If the feature is not important to the users and there is no likelihood that the feature will become important to the users in the future, then the code should not be there. Period. We cannot waste time and effort supporting code that our users will not need. Scope-creep is a real danger to any project and should be avoided at all costs, even on the small stuff. Lots of small stuff adds up to big stuff, especially over the lifespan of any non-trivial application.
So, if the features are important to the users, we test them, if they are unimportant to the users, we remove them. No controversy here. The questions come in when there is a likelihood that the feature could become important in the future, or if the feature is important to someone other than the users, such as the developers.
Suppose we decide that the users are likely to request this feature in the future. Wouldn't it be easier just to implement the feature now, when we are already in the code and familiar with it? My answer to this is to fall back on YAGNI. You Ain't Gonna Need It, has proven itself a valuable principal for preventing scope-creep. Even if you think it is pretty likely that you'll need something later, the reality is that you probably won’t. Based on this principal, we should not be putting features into our projects that are not needed right now.
But what about the situation where code is important to someone other than the users, for example, the developers? In this case, we have to decide if the code really is important, or is it just another case where the YAGNI principal should be applied. Technical requirements can be legitimate, but any requirement that is not directly in support of the user's needs is a smell that should be investigated. In the case of our property setter, saying that standardization is important and using that logic to make standardization a requirement sounds a lot like saying "I think this feature may be important someday" and it probably falls to YAGNI to keep it out of our code. That being said, if there is a technical requirement that is truly needed, it should be tested like any other important requirement. For a little more information on this, see my earlier analysis Conflict of Interest: Yagni vs. Standardization.
How About we Leave It and Just Don't Test It?
It is important to remember that we shouldn't simply leave code untested in our production code, even if the users don't really care about it right now. If we do so, and the feature becomes important in the future, we will almost certainly end up with code that is important to our users, but is untested and therefore at-risk. We are unlikely to go back into an application and just add tests for a feature that already exists simply because that feature is now important when it wasn't earlier. We'd like to think we would, but the fact is that we won't. No, leaving the code in the application, but untested, is not an option.
The Case for 100% Code Coverage
So, we want to remove any code that is not currently required by our users, and test all code that is truly needed. If you have come along with me on this you may now realize that 100% code coverage is actually a reasonable goal, since that would be the result of removing all unneeded code and testing all needed code. This is not to say that it is reasonable to use Code Coverage as a metric with which to judge a development team, but instead it should be considered as a tool that can help identify scope-creep and missing tests. Since we are testing all code that our users care about, and not adding any code that the users don't care about, we should expect to approach 100% code coverage in order to have a good chance of producing well-tested, maintainable code that gives us the flexibility and confidence to refactor ruthlessly.
Code Coverage sometimes gets a bad reputation because it can be easy to game. That is, it is not a good metric of success for a development team. However, it is a magnificenttool to help you identify places where tests are missing. It won't tell you where your tests are not doing what they need to do, but it will tell you when you have a piece of code that is not exercised by any tests. If you are a TDD (Test-Driven-Development) practitioner, as I am, Code Coverage will tell you when you’ve gotten ahead of yourself and written code before writing a test for it. This is especially valuable for those who are just learning TDD, but never loses its value no matter how experienced you are at TDD.
Continue the Conversation
How do you feel about this logic? Did I miss something critical in this analysis? Have you found something different in your experience? Let's keep this conversation going. Ping me @bsstahl with your comments, or post on your blog and send me the link.
Tags: code coverage testing tdd unit testing yagni agile
Introducing TestHelperExtensions
Posted by bsstahl on 2015-08-26 and Filed Under: development
TL;DR Version
I've released a new Open-Source library of extension methods that can be used to create more effective unit and integration tests. This library is called TestHelperExtensions. The source code is available on GitHub (pull requests welcome), a .NET 4 package is available via NuGet, and the documentation is available here. The goal is to allow anyone to have access to the same set of test helpers I have been using, and building up, for many years.
The Story
I have been giving Test Driven Development (TDD) sessions at code camps and conferences for a number of years. During those sessions, I spend a lot of time in code, building up a test suite for a production application, and demonstrating the process I use for TDD. Part of this process is using a set of extension methods to perform common tasks, such as generating test data, and doing comparisons of DateTime values. Many people have asked for access to this library during these sessions and my answer has always been the same, "you can grab it from the sample code". Now, I've decided to make it easier for anyone to include it in their projects via NuGet, and to allow the community the opportunity to extend and modify the library on GitHub.
Going Forward
I still have a small backlog of features I'd like to add to this tool. After that, It's up to you what happens with it. If you have a feature suggestion, please let me know. @bsstahl is the best place to start a conversation about this, or any development topic with me. You can also create an issue on GitHub, or simply submit a pull request. I'd love to hear how you are using this library, and anything that can be done to make it more effective for you.
Tags: agile community development framework open source tdd testing unit testing visual studio
New OSS Project
Posted by bsstahl on 2014-07-11 and Filed Under: development
I recently started working on a set of open-source projects for Code Camps and other community conferences with my friend Rob Richardson (@rob_rich). In addition to doing some good for the community, I expect these projects, which I will describe in more detail in upcoming posts, to allow me to experiment with several elements of software development that I have been looking forward to trying out. These include:
- Using Git as a source control repository
- Using nUnit within Visual Studio as a test runner
- Solving an optimization problem in C#
- Getting to work on a shared project with and learning from Rob
As an enterprise developer, I have been using MSTest and Team Foundation Server since they were released. My last experience with nUnit was probably about 10 years ago, and I have never used Git before. My source control experience prior to TFS was in VSS and CVS, and all of that was at least 6 or 7 years ago.
So far, I have to say I'm very pleased with both Git for source control, and nUnit for tests. Honestly, other than for the slight syntactical changes, I really can't tell that I'm using nUnit instead of MSTest. The integration with Visual Studio, once the appropriate extensions are added, is seamless. Using Git is a bit more of a change, but I am really liking the workflow it creates. I have found myself, somewhat automatically, committing my code to the local repository after each step of the Red-Green-Refactor TDD cycle, and then pushing all of those commits to the server after each full completion of that cycle. This is a good, natural workflow that gives the benefits of frequent commits, without breaking the build for other developers on the project. It also has the huge advantage of being basically unchanged in a disconnected environment like an airplane (though those are frequently not disconnected anymore).
The only possible downside I can see so far is the risk presented by the fact that code committed to the local repository, is not yet really safe. Committing code has historically been a way of protecting ourselves from disc crashes or other catastrophes. In this workflow, it is the push to the server, not the act of committing code, that gives us that redundancy protection. As long as we remember that we don't have this redundancy until we push, and make those pushes part of the requirements of our workflow, I think the benefits of frequent local commits greatly outweigh any additional risk.
As to the other two items on my list, I have already learned a lot from both working with Rob and in working toward implementing the optimization solution. Even though we've only been working on this for a few days, and have had only 1 pairing session to this point, I feel quite confident that both the community and I will get great benefit from these projects.
In my next post, I'll discuss what these projects are, and how we plan on implementing them.
Tags: ai code camp community conference csharp enterprise mstest nunit open source professional development tdd testing unit testing
Visual Studio Unit Test Generator
Posted by bsstahl on 2013-08-05 and Filed Under: development
As a follow-up to my posts here and here on the missing “Create Unit Test” feature in VS2012, I point you to this post from the Visual Studio ALM & TFS blog announcing the Release Candidate of their new Unit Test Generator for Visual Studio. According to the post, this extension
“…adds the “create unit test” feature back, with a focus on automating project creation, adding references and generating stubs, extensibility, and targeting of multiple test frameworks.”
I am installing the extension now and will comment on how well it works for my TDD workflow in a future post.
Tags: visual studio unit testing testing tdd
Programmers -- Take Responsibility for Your Program’s Output
Posted by bsstahl on 2013-03-03 and Filed Under: development
You have probably seen the discussion of the “Keep Calm and Rape a Lot” T-Shirts that were made available, for a time, by an Amazon reseller. These shirts were one of several thousand computer-generated designs offered for sale on Amazon, to be printed and shipped if anyone cared to buy one. At first blush, and as some have pointed-out, it seems like a simple error. A verb list that contained the word “rape” was not properly vetted and therefore the offensive shirt promoting violent crime was offered for sale by mistake. No offense was intended, so, as long as the company takes the proper action of apologizing and removing the offending item, all is well. This sentiment seems to be summed-up by the well-read post by Pete Ashton on the subject:
Because these algorithms generally mimic decisions that used to be made directly by people we have a tendency to humanise the results and can easily be horrified by what we see. But some basic understanding of how these systems work can go a long way to alleviating this dissonance.
However, I believe it is not nearly this simple. For one thing, I wonder about how this offensive shirt was “discovered”. Did somebody really stumble across it in the Amazon store, or, was its existence “leaked” to generate publicity. I don’t know the answer to this question, but if it were the case that someone at the company knew it was there, and either did nothing or worse, used it for marketing purposes, that would invalidate the “…it was computer generated” defense. However, in my mind, that defense doesn’t hold water for another reason. That is, we know this can happen and have the responsibility to make sure it doesn’t.
The companies that use our software are responsible for the output of our programs. If we are using a sequence of characters that could potentially form a word, those companies are responsible for the message that word conveys. If our programs output a sequence of words that could potentially form a sentence, they are responsible for that message as well. If the reasonable possibility exists that a message generated by these algorithms would be offensive, and visible to the public, failure to properly vet the message makes that company responsible for it.
This fact is made even more critical when our customers are enterprise scale clients and we are building software for use by the general public. As an example, lets look at one of the common systems for creating airline reservations which has been in operation for decades. This system presents to the consumer a six-character alphanumeric code known as the Record Locator Number. This identifier is used for the reservation by both automated and manual systems. What do you think would happen if you were making an airline reservation, and the response, either verbally, or in text, came back with the Record Locator “FATASS”? How about “FUKOFF” or “UBITCH”? If the programmers who created this system had just coded a random (or incrementing) set of any 6 characters, these letter combinations would have come up, probably multiple times by now because of the sheer volume of use. However, the system creators knew this could happen and did what needed to be done to prevent sequences with meaning from being used. As language changes and different letter combinations have different meanings, these policies need to be reviewed and amended to include additional letter combinations. Problems like this are not new and have been solved many times before, when the clients wanted them to be solved.
Knowing that random combinations of words can result in meaningful, and potentially offensive sentences, we are responsible for the failure when they actually do, whether they happened “intentionally” or not.
Tags: coding-practices development enterprise responsibility testing
Code Sample for My TDD Kickstart Sessions
Posted by bsstahl on 2012-02-13 and Filed Under: development
The complete, working application for my .NET TDD Kickstart sessions can be found here.
Unzip the files into a solution folder and open the Demo.sln solution in a version of Visual Studio 2010 that has Unit Testing capability (Professional, Premium or Ultimate). Immediately, you should be able to compile the whole solution, and successfully execute the tests in the Bss.QueueMonitor.Test and Bss.Timing.Test libraries.
To get the tests in the other two test libraries (Bss.QueueMonitor.Data.EF.Test & Bss.QueueMonitor.IntegrationTest) to pass, you will need to create the database used to store the monitored data in the data-tier and integration tests, and enable MSMQ on your system so that a queue to be monitored can be created for the Integration test.
The solution is configured to use a SQLExpress database called TDDDemo. You can use any name or SQL implementation you like, you’ll just need to update the configuration of all of the test libraries to use the new connection. The script to execute in the new database to create the table needed to run the tests can be found in the Bss.QueueMonitor.Data.EF library and is called QueueDepthModel.edmx.sql.
You can install Message Queuing on computers running Windows 7 by using Programs and Features in the Control Panel. You do not need to create any specific queue because the integration test creates a queue for each test individually, then deletes the queue when the test is complete.
If you have any questions or comments about this sample, please start a conversation in the Fediverse @bsstahl or Contact Me.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di event framework ioc tdd testing unit testing visual studio
.NET TDD Kickstart
Posted by bsstahl on 2012-01-26 and Filed Under: event development
I head out to Fullerton tomorrow for the start of my .NET TDD Kickstart world tour. 
In this session, the speaker and the audience will "pair up" for a coding session which will serve as an introduction to Test Driven Development in an Agile environment. We will use C#, Visual Studio and Rhino Mocks to unit test code to be built both with and without dependencies. We will also highlight some of the common issues encountered during TDD and discuss strategies for overcoming them.
I will be presenting this session at numerous venues around the country this year, including, so far:
- Southern California Code Camp – Fullerton in January
- South Florida Code Camp – Ft. Lauderdale in February
- New Mexico .NET User’s Group – Albuquerque in March
- Twin Cities Code Camp – Minneapolis in April
If you are interested in having me present this or another session at your event, please contact me.
There is much more than an hour’s worth of material to be presented, so instead of trying to rush through everything I want to talk about during this time, I’ve instead taken some questions from this presentation and posted them below. Please contact me if you have any additional questions, need clarification, or if you have an suggestions or additions to these lists.
Update: I have moved the FAQ list here to allow it to be maintained separately from this post.
Tags: abstraction agile assert code camp coding-practices community conference csharp development di framework ioc tdd testing unit testing visual studio
Order Matters in the Rhino Mocks Fluent Interface
Posted by bsstahl on 2012-01-16 and Filed Under: development
I noticed something interesting with Rhino Mocks today while testing some demo code:
Rhino.Mocks.Expect.Call(myDependency.MyMethod(param1)).Return(result).Repeat.Times(5);
behaves as I anticipated; it expects the call to MyMethod to be repeated 5 times and returns the value of result all 5 times. Meanwhile:
Rhino.Mocks.Expect.Call(myDependency.MyMethod(param1)).Repeat.Times(5).Return(result);
also has the expectation of 5 executions, but it returns the value of result only once. The other 4 executions return 0.
When I think about it now, it makes sense, but it wasn't the behavior I originally expected.
Tags: abstraction tdd testing mocks
Demo Code for EF4Ent Sessions
Posted by bsstahl on 2011-06-26 and Filed Under: development
I previously posted the slides for my Building Enterprise Apps using Entity Framework 4 talk here. I can now post the source code for the completed demo application. That code, created for use in Visual Studio 2010 Ultimate, is available in zip format below. This is the same code that was demonstrated at Desert Code Camp 2011.1 and SoCalCodeCamp 2011 as well as the New Mexico .NET User’s Group (NMUG).
Tags: abstraction agile assembly code analysis code camp code contracts code sample coding-practices conference csharp enterprise library entity entity framework fxcop interface testing unit testing visual studio
Unit Testing the Data Tier
Posted by bsstahl on 2007-08-23 and Filed Under: development
Recently, both Jeffrey Polermo and Scott Bellware have written posts on codebetter.com positing that testing the Database should be avoided when doing unit testing. Specifically, Polermo points out that
Unit testing, by common definition, excludes external dependencies. It's not a unit test if we reach out and touch things.
While this may be a nice ideal, in reality it simply does not turn out to be the best way to do things in the majority of situations. Of course, to be fair, every situation is different and I'm sure there are many circumstances where it is better to pull-out database testing into integration tests or similar. In fact, there are perfectly valid reasons why we might not want to call it a unit-test if we test the database. However, for the majority of software projects (i.e. the 80% use-case), I belive it is not only legitimate, but best-practice, to test the database with our unit tests.
To understand the primary reasoning here, we need to go back to the fundamentals and look at our logical view of this 80% use-case software system.
The drawing illustrates many of the systems we create today in .NET. Of course, not all systems will fit into this model, but it certainly represents the classic 3-tier architecture used by so many of our projects. As this drawing shows, our data-access objects, which are often just thin wrappers over stored procedures, perhaps containing some ORM logic, are really part of the data-services layer. Even though these objects may physically reside alongside the business-layer objects, they really belong to the data-services. Thus, the assertion that we cross boundaries by testing the database when we test the data-services "unit" is not, in my mind, a valid concern. Yes, the tests will make out-of-process calls in getting to the database, and we will suffer a performance penalty as a result, but the fact remains that the database is not a dependency of the data-access objects, it is an integral part of that layer. Thus, in order to test that layer, we must test the database.
From a practical standpoint, this view of the application works out best in terms of testing it since the data-access objects are generally so thin. What is the point of testing those objects in isolation since they are basically wrappers most of the time? It is sometimes appropriate to write some tests for these objects on their own if they contain ORM type logic that can be tested as a unit, but for the most part, when we test the data-layer, what we want to test is that the proper data is returned. Validating that the proper data is returned from the data-tier requires testing the entire layer, including the database. Another factor here is that the database itself cannot generally be tested without some form of .NET object interface. As an example, if we were to try and write a unit test for a stored procedure in nUnit or VS Team System, we would need to have the same data-access code in our test, as we have in our data-tier object. Thus, it only makes sense to test those items as one unit. Perhaps down the road, since SQL server now has its own CLR, we may be able to do more testing of the database objects at that level and not need data-access objects. When that occurs, we should definately revisit our best-practices. But for now it is clear that the best way to test data-access is to test the data-services layer as a unit.
Please do not think that in any way I am suggesting we need to test the database in the same tests that are used for the business-layer objects. That would be a clear violation of the separation-of-concerns discussed by both Polermo and Bellware as well as many others and would best be described as an integration test because it crosses the boundaries in the diagram above. We should definately isolate the layers of our applications from each other in order to accurately test them. What I am saying is that the isolation of the data-tier should occur between the business-tier and the data-tier on the diagram. Thus, testing of the data-access objects includes testing of the database objects. The question then really becomes, how do we unit-test the data-services layer so that the tests execute as quickly as possible, do not have dependancies on existing data so that changes to the data cause tests to fail, yet still accurately and completely test that unit. I am attempting to put together a list of best-practices in this area and will make that the subject of a future post.
Tags: testing database architecture
Unit Test "Normalization"
Posted by bsstahl on 2007-07-07 and Filed Under: development
In a recent conversation about Unit Tests, I was asked about how many asserts I would put into a single test, since some feel that there should only be one Assert per test. My answer was, that I look at it like database normalization with the test name serving as the primary key; that is, the asserts in the test should relate directly and only to that key. This analogy is also appropriate because DB normalization is a good thing within reason, but can definately be overdone. Unit test "normalization" can also be overdone if we try to break-out each assert into its own test.
An example of where multiple asserts might be put into one test is a test of the Add method of a collection object which inherits from System.Collection.CollectionBase. When an item is added, it is appropriate to test for the proper index of that item to be returned from the method, as well as to test that the collection is holding the correct number of items after the Add is done. Both tests relate directly to the Add method. An argument could be made that the count of items relates to the Count property of the collection and therefore that assert doesn't relate only to the Add method, but since we are usually not coding the count property (because it was coded for us in CollectionBase), we don't need to test the Count property on its own, and it should be tested as part of the Add test.
Tags: tdd testing assert
nUnit vs. VSTS
Posted by bsstahl on 2006-10-07 and Filed Under: development
Mark Michaelis posted a hit list of things to do to convert from nUnit to VSTS tests in his article Converting a class library to a VSTS Test Project. A big part of this process is understanding the attribute translation:
| nUnit | VSTest |
|---|---|
| TestFixture | TestClass |
| TestFixtureSetUp | ClassInitialize |
| TestFixtureTearDown | ClassCleanup |
| SetUp | TestInitialize |
| TearDown | TestCleanup |
| Test | TestMethod |
