Tag: solution
Scalable Decision Making
Posted by bsstahl on 2017-06-01 and Filed Under: development
I recently had a developer colleague return from an AI conference and tell me something along the lines of "…all they really showed were algorithms, nothing that really learned." Unfortunately, there is this common misconception, even among people in the software community, that to have an AI, you need Machine Learning. Now don't get me wrong, Machine Learning is an amazing technique and it has been used to create many real breakthroughs in Software Engineering. But, to have AI you don't need Machine Learning, you simply need a system that makes decisions that otherwise would need to be made by humans. That is, you need a machine to act rationally. There are many ways to accomplish this goal. I have explored a few methods in this forum in the past, and will explore more in the future. Today however, I want to discuss the real value proposition of AI. That is, the ability to make decisions at scale.
The value in AI comes not from how the decisions are made, but from the ability to scale those decisions.
I see 4 types of scale as key in evaluating the value that Artificial Intelligences may bring to a problem. They are the solution space, the data requirements, the problem space and the volume. Let's explore each of these types of scale briefly.
Solution Space
The solution space consists of all of the possible answers to a question. It is the AIs job to evaluate the different options and determine the best decision to make under the circumstances. As the number of options increases, it becomes more and more important for the decisions to be made in an automated, scalable way. Artificial Intelligences can add real value when solving problems that have very large solution spaces. As an example, let's look at the scheduling of conference sessions. A very small conference with 3 sessions and 3 rooms during 1 timeslot is easy to schedule. Anyone can manually sort both the sessions and rooms by size (expected and actual) and assign the largest room to the session where the most people are expected to attend. 3 sessions and 3 rooms has only 6 possible answers, a very small solution space. If, on the other hand, our conference has 450 sessions spread out over 30 rooms and 15 timeslots, the number of possibilities grows astronomically. There are 450! (450 factorial) possible combinations of sessions, rooms and timeslots in that solution space, far too many for a person to evaluate even in a lifetime of trying. In fact, that solution space is so large that a brute-force algorithm that evaluates every possible combination for fitness, may never complete either. We need to depend on combinatorial optimization techniques and good heuristics to manage these types of decisions, which makes problems with a large solution space excellent candidates for Artificial Intelligence solutions.
Data Requirements
The data requirements consist of all of the different data elements needed to make the optimal decision. Decisions that require only a small number of data elements can often be evaluated manually. However, when the number of data elements to be evaluated becomes unwieldy, a problem becomes a good candidate for an Artificial Intelligence. Consider the problem of comparing two hitters from the history of baseball. Was Mark McGwire a better hitter than Mickey Mantle? We might decide to base our decision on one or two key statistics. If so, we might say that McGwire was a better hitter than Mantle because his OPS is slightly better (.982 vs .977). If, however we want to build a model that takes many different variables into account, hopefully maximizing the likelihood of making the best determination, we may try to include many of the hundreds of different statistics that are tracked for baseball players. In this scenario, an automated process has a better chance of making an informed, rational decision.
Problem Space
The problem space defines how general the decision being made can be. The more generalized an AI, the more likely it is to be applicable to any given situation, the more value it is likely to have. Building on our previous example, consider these three problems:
- Is a particular baseball hitter better than another baseball hitter?
- Is a particular baseball player better than another baseball player (hitter or pitcher)?
- Is a particular baseball player a better athlete than a particular soccer player?
It is relatively easy to compare apples to apples. I can compare one hitter to another fairly easily by simply comparing known statistics after adjusting for any inconsistencies (such as what era or league they played in). The closer the comparison and the more statistics they have in common, the more likely I am to be able to build a model that is highly predictive of the optimum answer and thus make the best decisions. Once I start comparing apples to oranges, or even cucumbers, the waters become much more muddied. How do I build a model that can make decisions when I don't have direct ways to compare the options?
AIs today are still limited to fairly small problem spaces, and as such, they are limited in scope and value. Many breakthroughs are being made however that allow us to make more and more generalizable decisions. For example, many of the AI "personal assistants" such as Cortana and Siri use a combination of different AIs depending on the problem. This makes them something of an AI of AIs and expands their capabilities, and thus their value, considerably.
Volume
The volume of a problem describes the way we usually think of scale in software engineering problems. That is, it is the number of times the program is used to reach a decision over a given timeframe. Even a very simple problem with small solution and problem spaces, and very simple data needs, can benefit from automation if the decision has to be made enough times in a rapid succession. Let's use a round-robin load balancer on a farm of 3 servers as an example. Round Robin is a simple heuristic for load balancing that attempts to distribute the load among the servers by deciding to send the traffic to each machine in order. The only data needed for this decision is the knowledge of what machine was selected during the last execution. There are only 3 possible answers and the problem space is very small and well understood. A person could easily make each decision without difficulty as long as the volume remains low. As soon as the number of requests starts increasing however, a person would find themselves quickly overwhelmed. Even when the other factors are small in scale, high-volume decisions make very good candidates for AI solutions.
These 4 factors describing the scale of a problem are important to consider when attempting to determine if an automated Artificial Intelligence solution is a good candidate to be a part of a solution. Once it has been decided that an AI is appropriate for a problem, we can then look at the options for implementing the solution. Machine Learning is one possible candidate for many problems, but certainly not all. Much more on that in future articles.
Do you agree that the value in AI comes not from how the decisions are made, but from the ability to scale those decisions? Did I miss any scale factors that should be considered when determining if an AI solution might be appropriate? Sound off in the Fediverse @bsstahl.
Tags: ai algorithms optimization solution
A.I. That Can Explain "Why"
Posted by bsstahl on 2016-12-15 and Filed Under: development
One of my favorite authors among Software Architects, IBM Fellow Grady Booch, made this reference to AlphaGo, IBM’s program built to play the board game Go, in April of 2016:
"...there are things neural networks can't easily do and likely never will. AlphaGo can't reason about why it made a particular move." – Grady Booch
Grady went on to refer to the concept of “Hybrid A.I.” as a means of developing systems that can make complex decisions requiring the processing of huge datasets, while still being able to explain the rationale behind those decisions.
While not exactly the type of system Grady was describing, it reminded me of a solution I was involved with creating that ultimately became a hybrid of an iterative, imperative system and a combinatorial optimization engine. The resulting solution was able to both determine the optimum solution for a problem with significant data requirements, while still being able to provide information to support the decision, both to prove it was correct, and to help the users learn how to best use it.
The problem looked something like this:
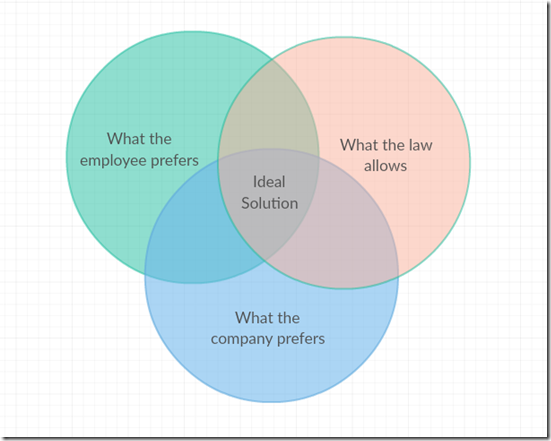
There are many possible ways to allocate work assignments among employees. Some of those allocations would not be legal, perhaps because the employee is not qualified for that assignment, or because of time limits on how much he or she can work. Other options may be legal, but are not ideal. The assignment may be sub-optimal for the employee who may have a schedule conflict or other preference against that particular assignment, or for the company which may not be able to easily fill the assignment with anyone else.
The complexity in this problem comes from the fact that this diagram is different for each employee to be assigned. Each employee has their own set of preferences and legalities, and the preferences of the company are probably different for each employee. It is likely that many employees will not be able to get an assignment that falls into the “Ideal Solution” area of the drawing. If there were just a few employees and a supervisor was making these decisions, that person would have to explain his or her rationale to the employees who did not get the assignments they wanted, or to the bosses if company requirements could not be met. If an optimization solution made the decisions purely on the basis of a mathematical model, we could be guaranteed the best solution based on our criteria, but would have no way to explain how one person got an assignment that another wanted, or why company preferences were ignored in any individual case.
The resulting hybrid approach started by eliminating illegal options, and then looking at the most important detail and assigning the best fit for that detail to the solution set. That is, if the most important feature to the model was the wishes of the most senior employee, that employee’s request would be added to the solution. The optimization engine would then be run to be sure that a feasible solution was still available. As long as an answer could still be found that didn’t violate any of the hard constraints, the selection was fixed in the solution and the next employee’s wishes addressed. If a feasible solution could not be found using the selected option, that selection would be recorded along with the result of the optimization and the state of the model at the time of processing. This allows the reasoning behind each decision to be exposed to the users.
A very simplified diagram of the process is shown below.
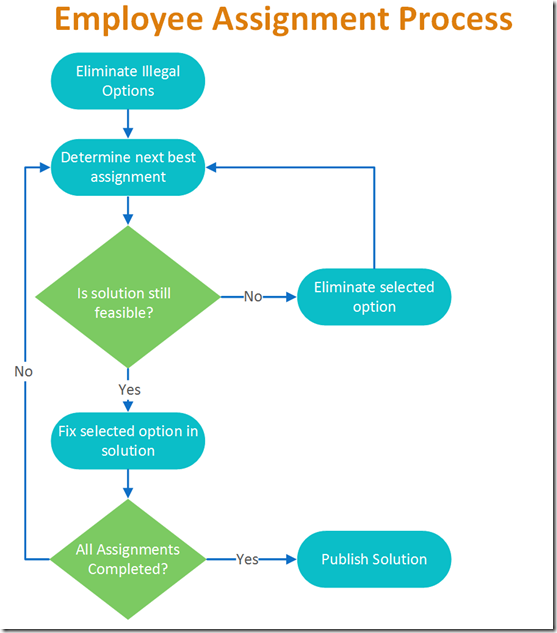
Each time the green diamond testing “Is the solution still feasible?” is hit, the optimization model is run to verify that a solution can be found. It is this hybrid process, the iterative execution of a combinatorial solution engine, that gives this tool its ability to both answer the question of how to do things, while also being able to answer the question of why it needs to be done this way.
Like Grady, I expect we will see many more examples of these types of hybrids in the very near future.
